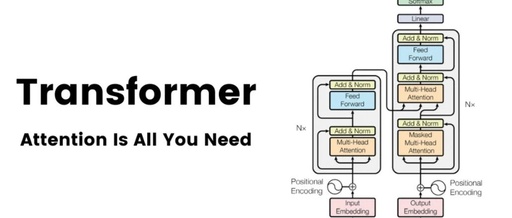
Understanding Three Attention Mechanisms in Transformer
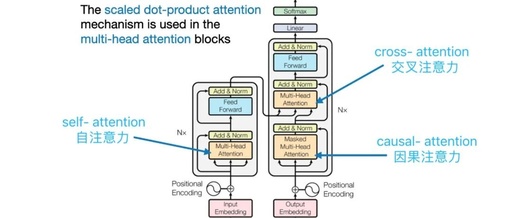
Application of Attention Mechanism in “Attention is All You Need” 3.2.3 3.2.3 Application of Attention Mechanism in Our Model The Transformer uses three different ways of multi-head attention mechanism as follows: In the “encoder-decoder attention” layer, queries come from the previous layer of the decoder, while memory keys and values come from the output of … Read more