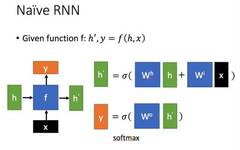
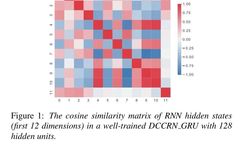
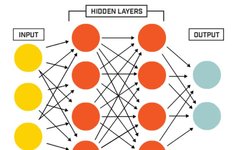
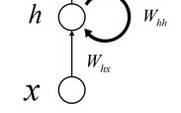
Deep Dive | Basics of Neural Networks: Seven Types of Units and Four Connection Methods
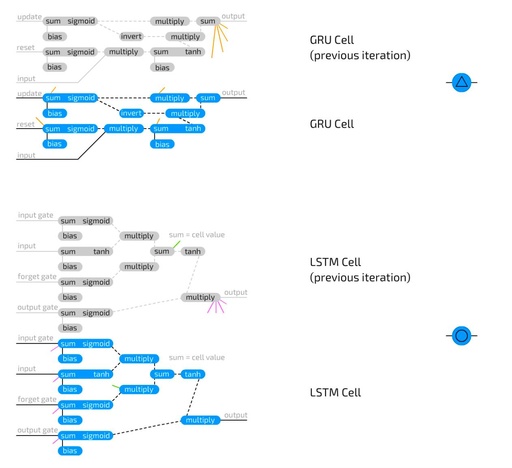
Excerpt from THE ASIMOV INSTITUTE Author: FJODOR VAN VEEN Translation by Machine Heart Contributors: Huang Xiaotian, Li Yazhou In September 2016, Fjodor Van Veen wrote an article titled “The Neural Network Zoo” (see the illustrated overview of neural network architectures: from basic principles to derivatives), which comprehensively reviewed a multitude of frameworks for neural networks … Read more