Google & Hugging Face: The Strongest Language Model Architecture for Zero-Shot Capability

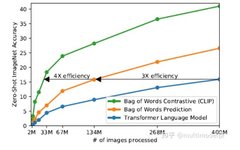
This article is approximately 2000 words long and takes about 5 minutes to read. If the goal is the model's zero-shot generalization capability, the decoder structure + language model task is the best; if multitask finetuning is also needed, the encoder-decoder structure + MLM task is the best. From GPT-3 to prompts, more and more … Read more