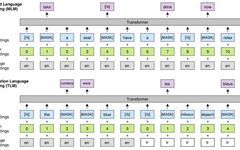
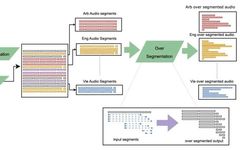
Tsinghua University’s Sun Maosong: A Glimpse into Natural Language Processing

Source: AI Technology Review This article is approximately 6625 words long and is recommended to be read in 10 minutes. This article introduces a deep discussion by Professor Sun Maosong, Executive Vice Dean of the Institute of Artificial Intelligence at Tsinghua University, on the contributions, current state, and future challenges of natural language processing. Recently, … Read more