


01
Model Architecture and Parameters
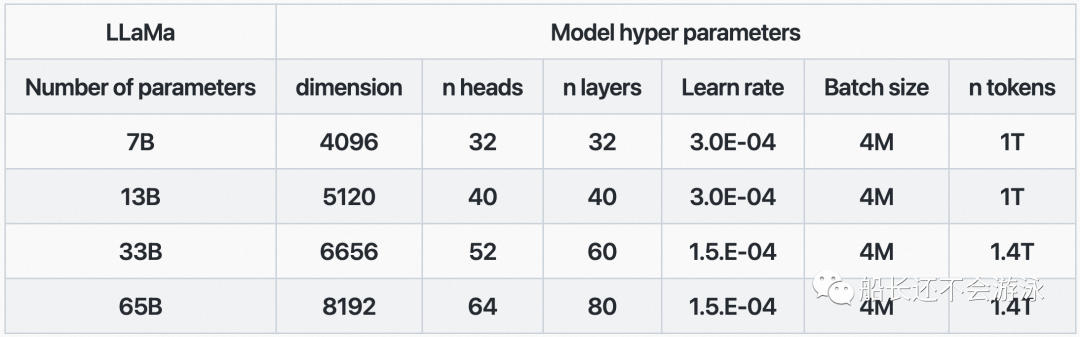
02
Data
Training Data for LLaMA
Evaluation Data and Performance of LLaMA
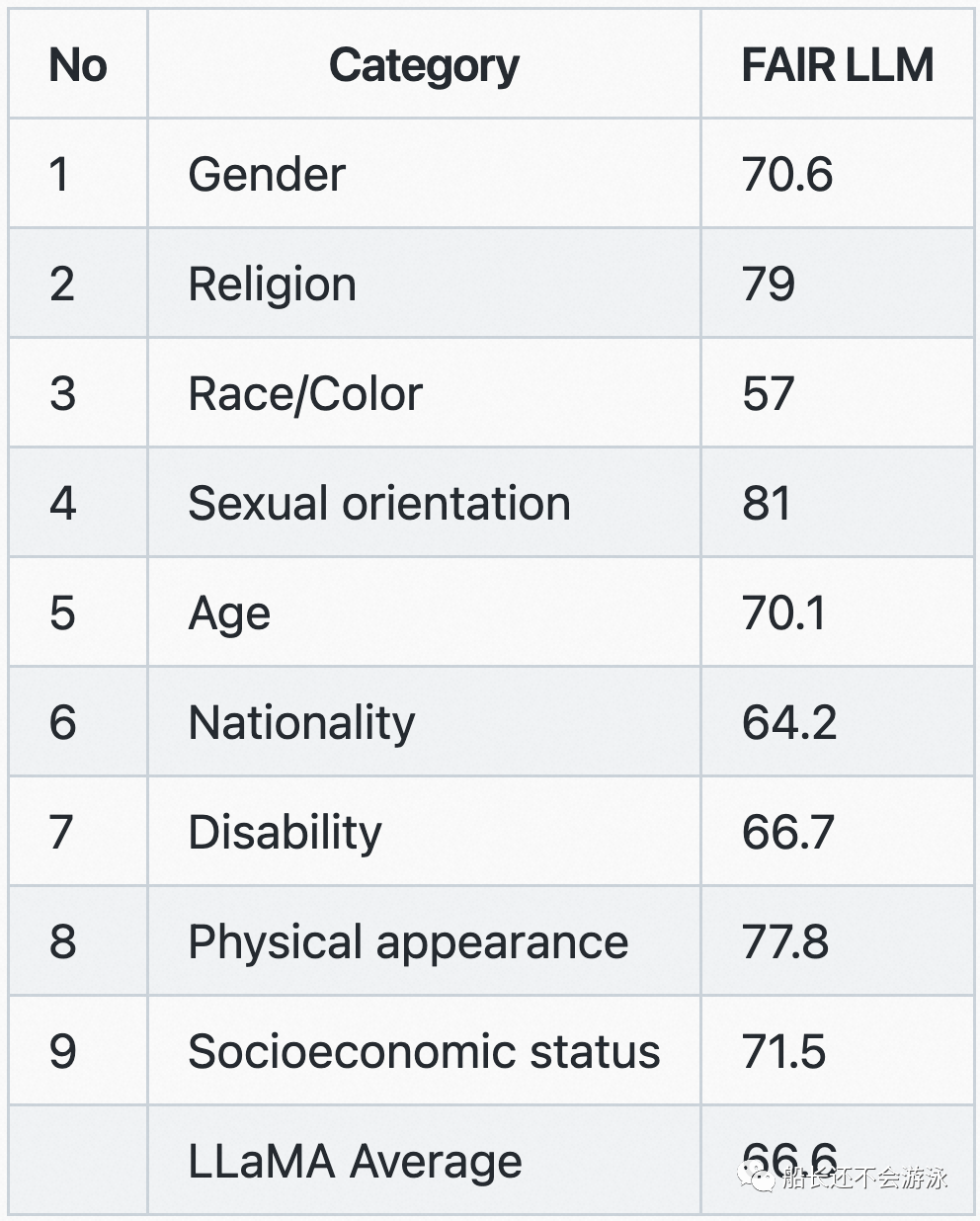
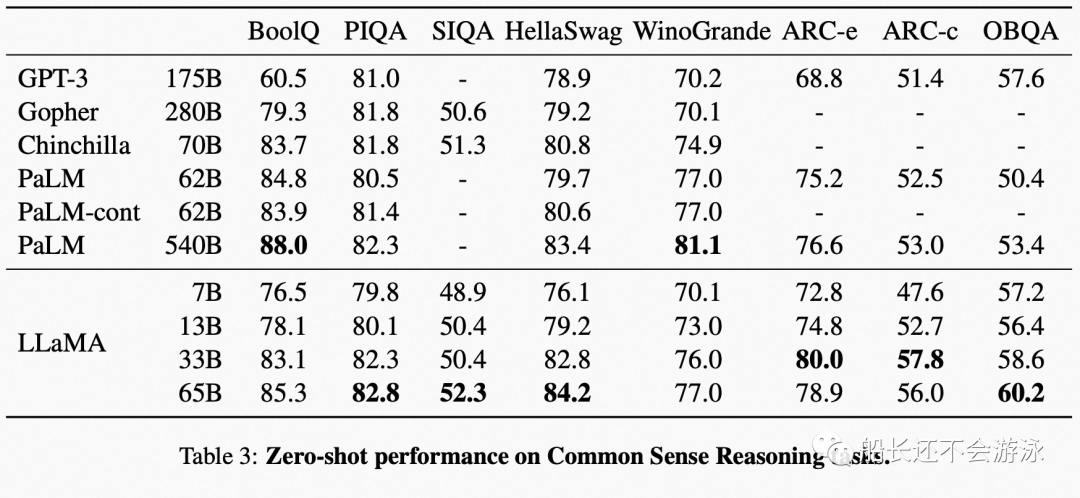
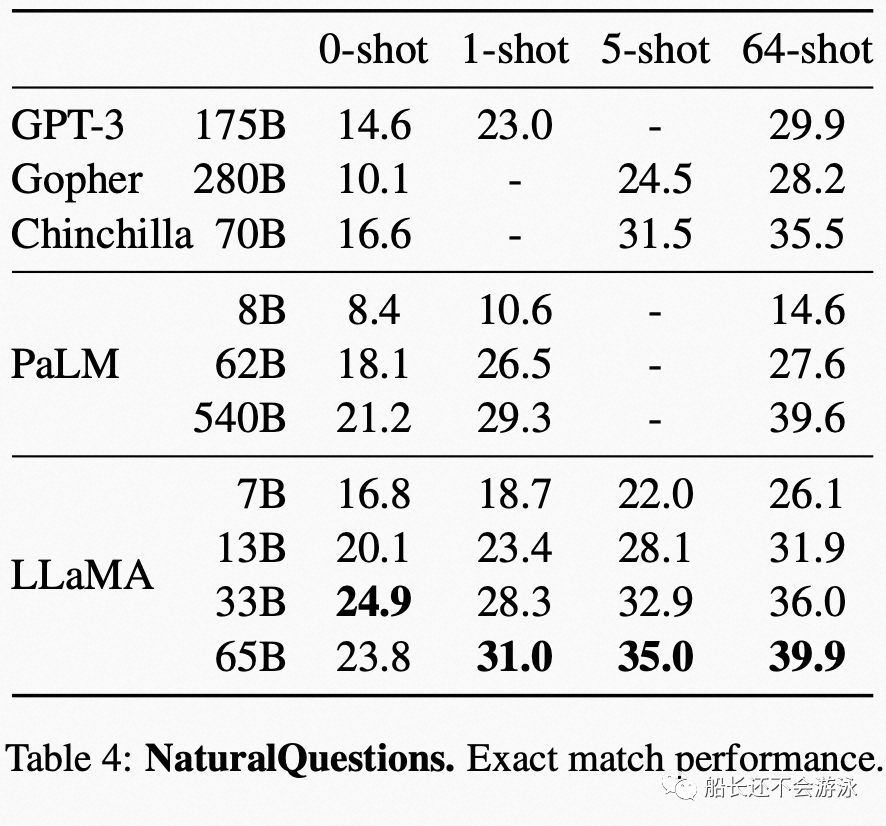
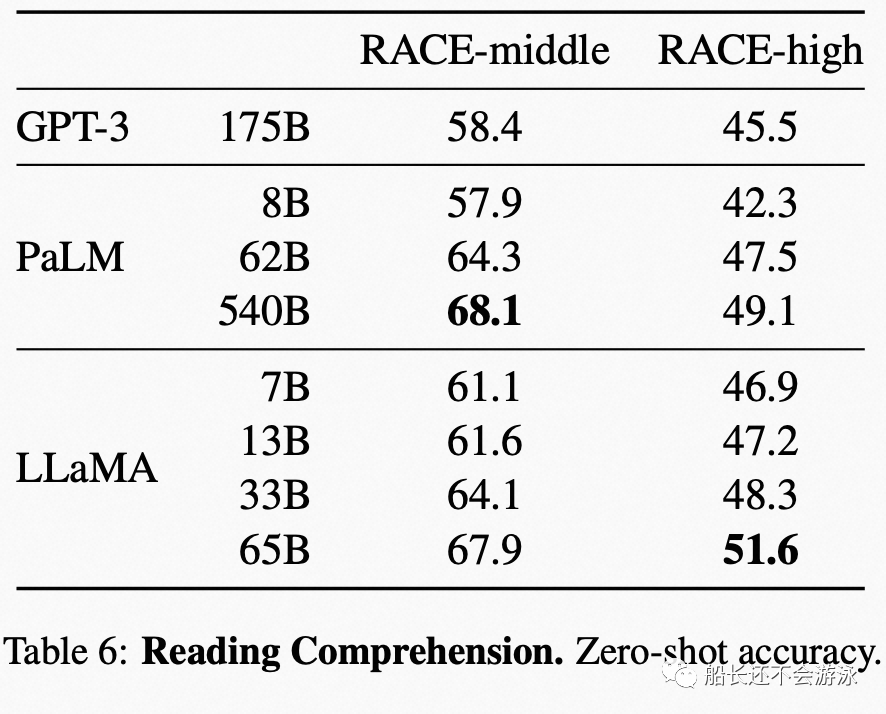
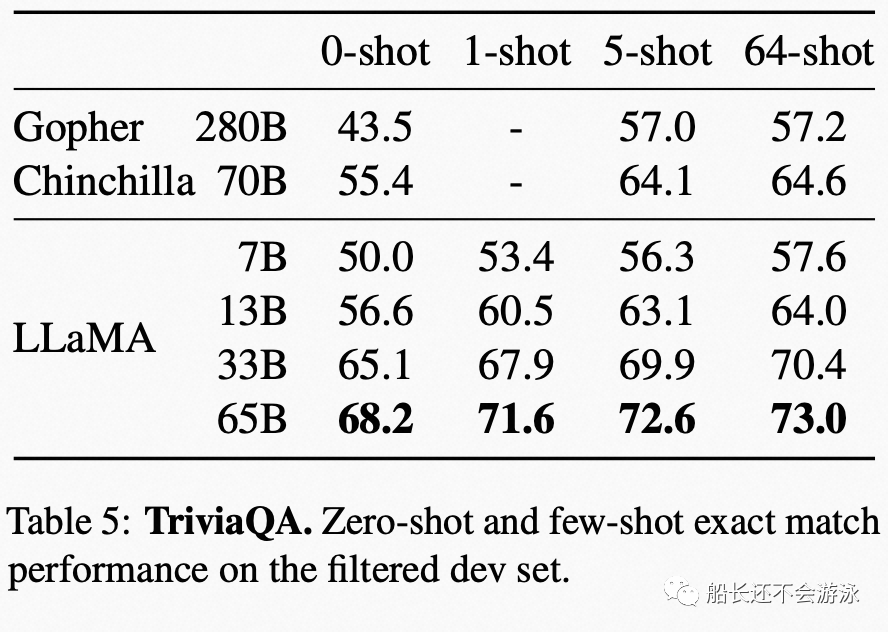
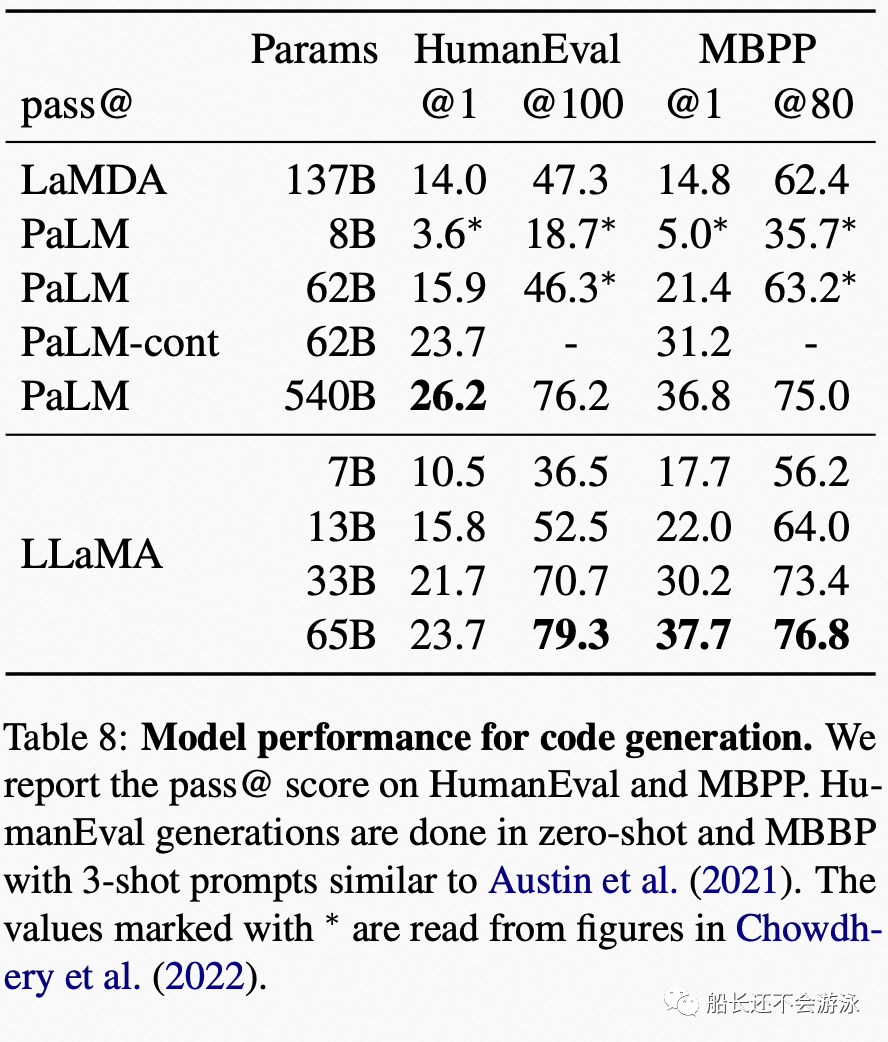
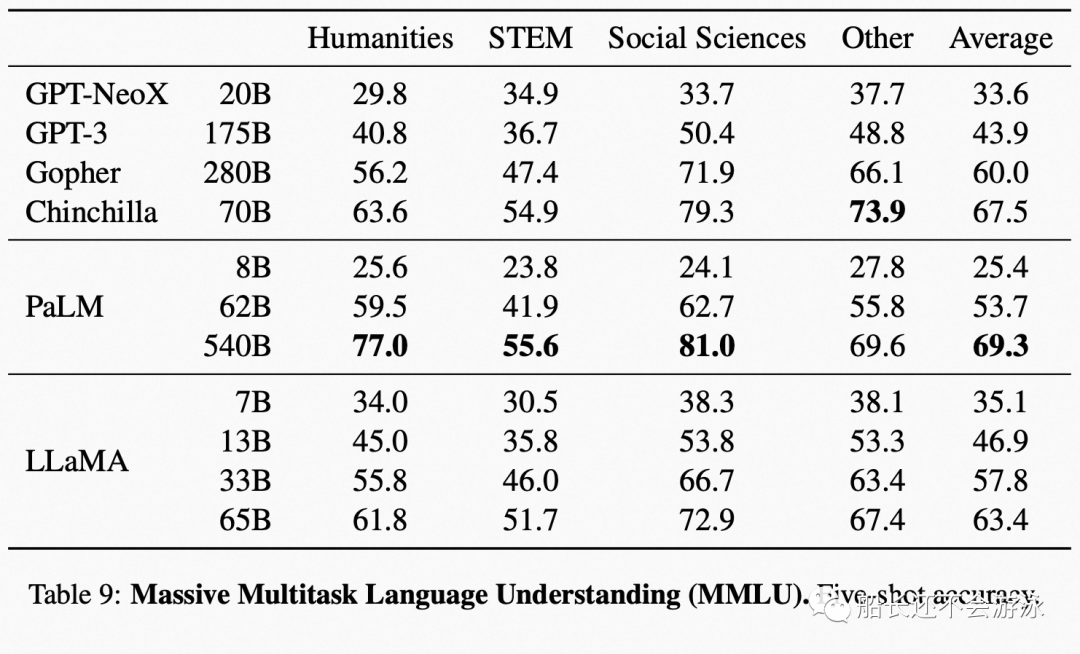
03
Computational Power
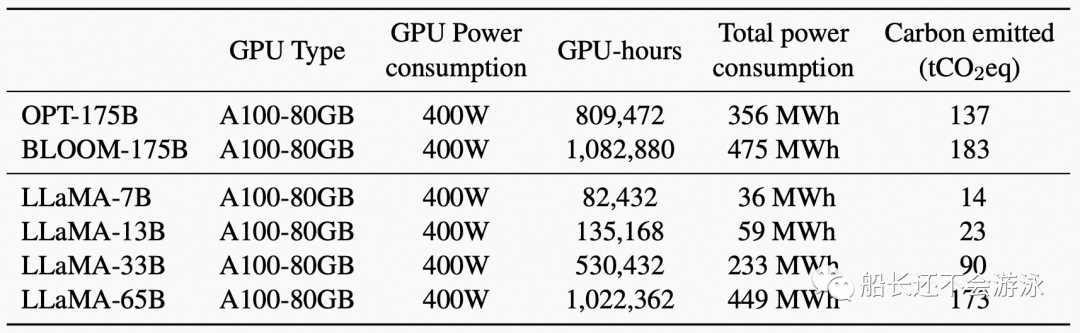
04
Can I try it out?
Let’s check out some examples provided by LLaMA.







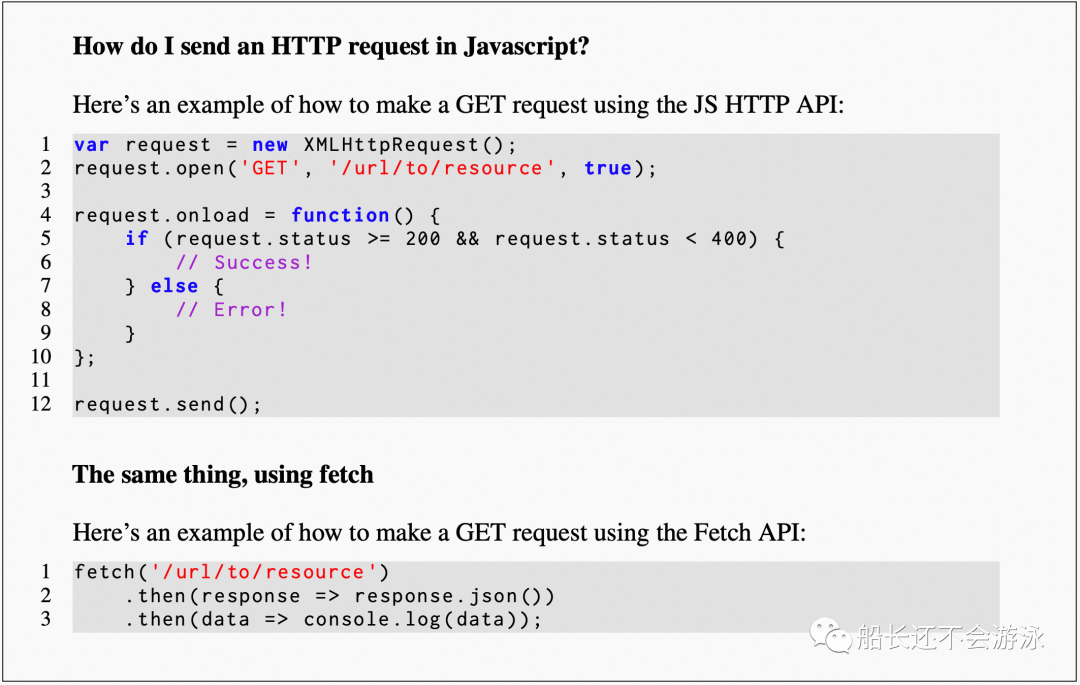








05
Some Comments and Future Impact
References
[1] Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in Neural Information Processing Systems, 32.
[2] Noam Shazeer. 2020. Glu variants improve transformer. arXiv preprint arXiv:2002.05202.
[3] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2021. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
[4] LLaMA GitHub repository from Meta AI Research – FAIR team, https://github.com/facebookresearch/llama
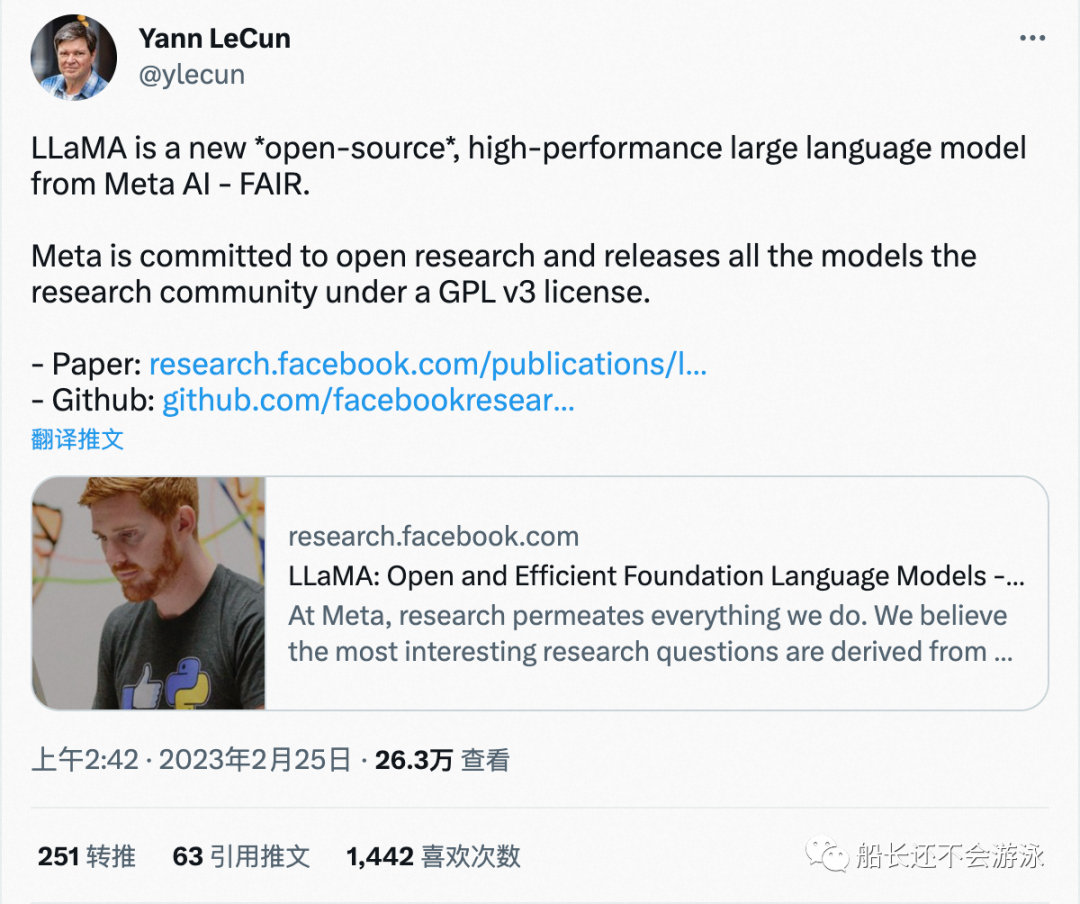
[5] Large Language Model LLaMA from Meta AI FAIR team, https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
[6] LLaMA Open and Efficient Foundation Language Models, https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
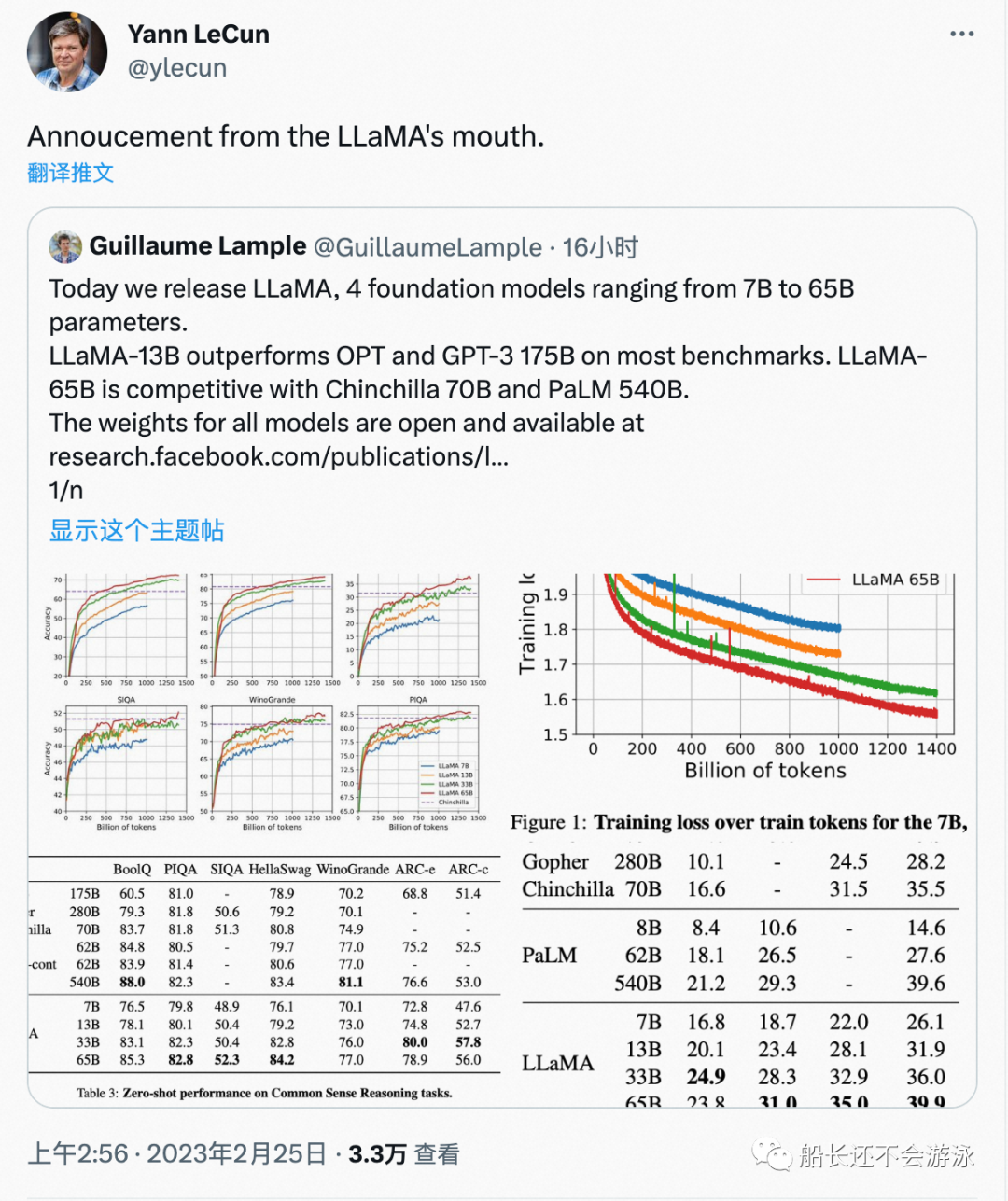
[7] https://twitter.com/ylecun/status/1629243179068268548
[8] LLaMA Announcement Tweet from Meta AI FAIR team, https://twitter.com/GuillaumeLample/status/1629151231800115202
[9] Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Wei Yu, Vincent Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed Huai hsin Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
END
Material Collection
