Authorized Reprint from Andy’s Writing Room
Author:ANDY
The BERT pre-trained model is like a pig ready for cooking, and fine-tuning is the cooking method. The pig’s head can be made into fragrant and rich roasted pig head meat, the trotters can be made into hearty braised trotters, and the various cuts like pork belly and tenderloin each have their own cooking methods. Thus, for BERT fine-tuning, there are various culinary techniques.
Preface
Since the BERT paper was released last year, it has been half a year, and not only has BERT’s name appeared on major leaderboards, but the recent announcement of the NAACL Best Long Paper also awarded BERT, which is well-deserved.

Coincidentally, while reading papers related to BERT, I summarized and introduced the various research related to BERT fine-tuning that have emerged half a year after the paper’s release.
First, let’s briefly introduce BERT before moving on to the main topic.
What is BERT? Its full name is Bidirectional Encoder Representations from Transformers (Transformer Bidirectional Encoder Features), abbreviated as BERT, which is one of the characters from Sesame Street.
The quirky naming has led to subsequent improved models from Microsoft and Baidu being called Big-Bird and ERNIE, seemingly having entered the world of Sesame Street.
BERT is primarily groundbreaking in that it proposes using both Masked Language Model (MLM) and Next Sentence Prediction (NSP) tasks simultaneously, along with a large amount of data, to pre-train a large Transformer model.
This model is the star of today, BERT.
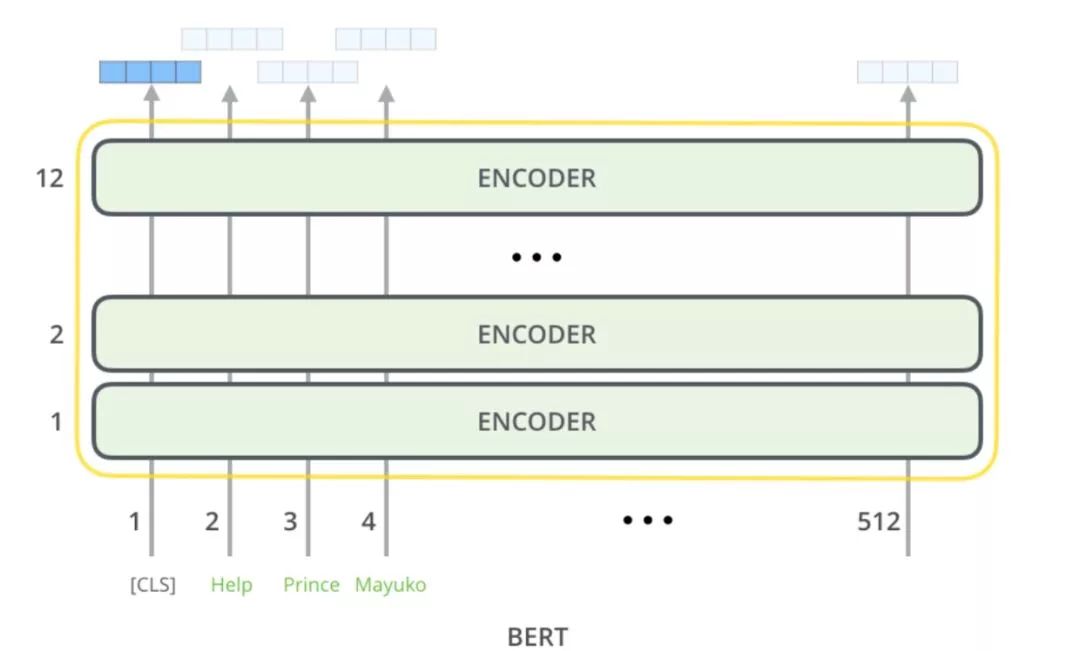
Main Components of BERT
Since we need to fine-tune each part, we must first understand the main components of the big fat pig, BERT.
First is the most critical input part, which is closely related to most fine-tuning.
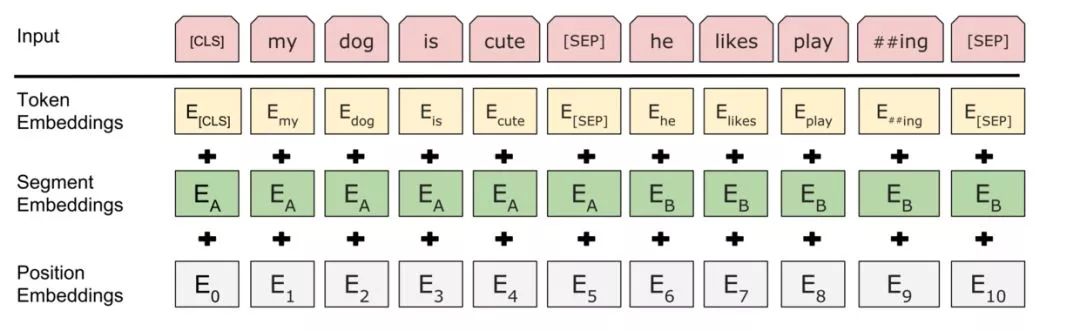
From top to bottom, we can see that the main components of BERT’s input are token vectors (here we understand them as words), segment vectors, and position vectors.
Token vectors are easy to understand and represent the main information about the words in the model;segment vectors are used because BERT has a next sentence prediction task, so two sentences are concatenated, with the first sentence having its segment vector and the second sentence having its segment vector, represented as A and B in the diagram. Additionally, sentences end with a [SEP] token, and the concatenated sentences start with a [CLS] token;the position vectors are added because the Transformer model cannot remember the sequence, so vectors representing position are artificially included.
These three vectors are then concatenated and fed into the BERT model, which outputs the representation vectors for each position.
Four Standard Methods of Fine-Tuning
Regarding fine-tuning, here we define the four methods mentioned in the BERT paper as standard methods, while other various methods are defined as fancy. If there are slight modifications to the standard methods, they are also categorized as standard.
Standard Method One: Sentence Pair Classification Task.
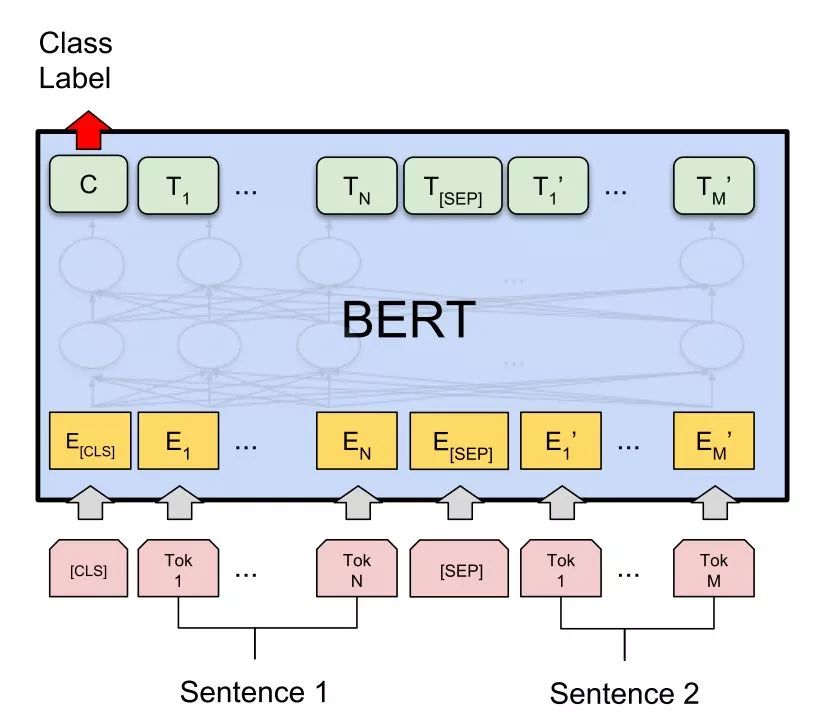
It’s simple, just like BERT’s setup, two sentences are concatenated, with [CLS] and [SEP] added, and the output vector at the [CLS] position is directly predicted for fine-tuning.
Standard Method Two: Single Sentence Classification Task.
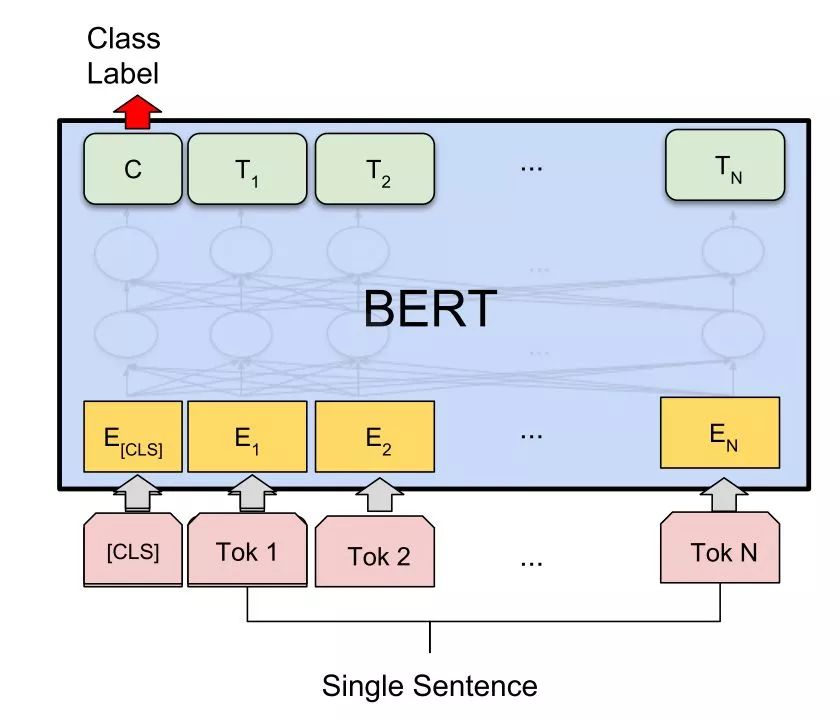
Unlike the sentence pair, a single sentence is directly taken, with [CLS] added at the front for input, and then the output is also taken from the [CLS] position for prediction during fine-tuning.
Standard Method Three: Question Answering (QA) Task.
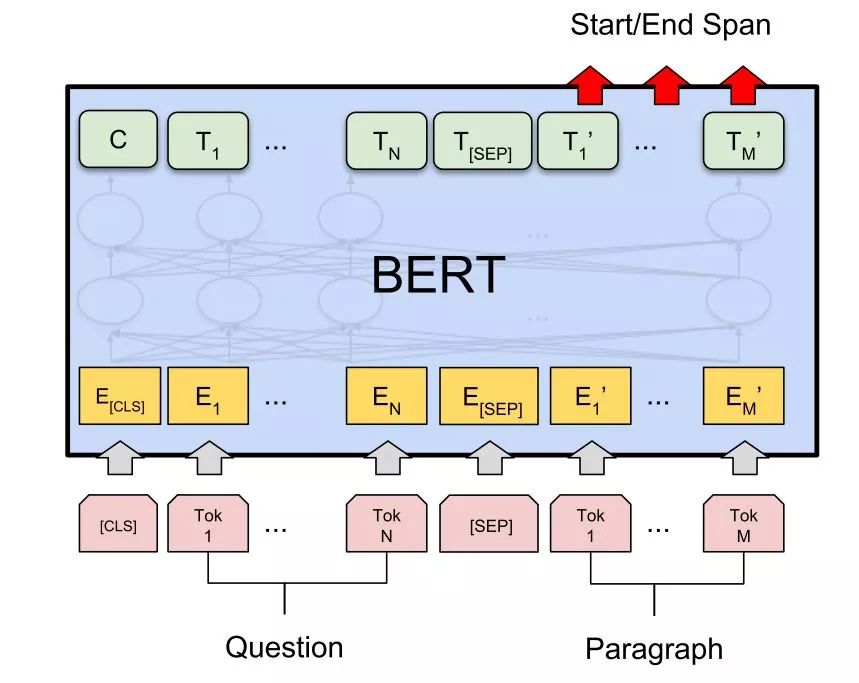
The question and the context required for answering are treated as the first and second sentences, respectively, with [CLS] and [SEP] special tokens added, and the positions of the answer in the context are predicted for fine-tuning.
Standard Method Four: Single Sentence Tagging Task.
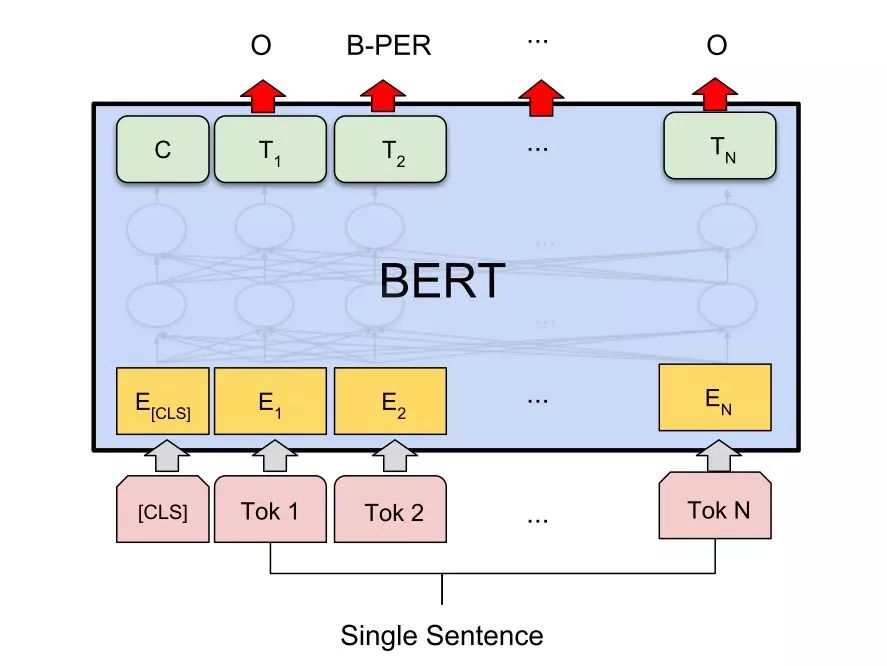
In the previous single sentence classification, [CLS] is added first, but the output is taken from other positions to predict the corresponding tags for fine-tuning.
Standard Fine-Tuning Methods
Let’s first introduce the standard methods used in the papers.
Sentence Pair Classification

The standard sentence pair classification method in tasks such as document retrieval uses the query and document as the first and second sentences, taking the output from [CLS] to predict during fine-tuning.
There are two papers:
-
Simple Applications of BERT for Ad Hoc Document Retrieval
-
Passage Re-ranking with BERT
If we say that such document retrieval mainly involves three steps:
First, use tools or algorithms (like BM25) to obtain initial candidates;
Second, re-score the query and candidates using methods, and reorder based on scores;
Third, take the top few as the result.
The main focus here is on the second step.
Simple Applications of BERT for Ad Hoc Document Retrieval
This mainly tested two tasks: first, the sentence-level retrieval matching of microblogs, using the Anserini IR toolkit to recall 1000 candidates based on the query, then concatenating the candidates and query to feed into BERT to get scores. Then, the BERT scores and Anserini scores are linearly interpolated to obtain the final scores and reorder them.
Then, on newswire, for long segment retrieval, the document length concatenated with the query exceeds the maximum length of the BERT pre-trained model, which is 512 tokens. In fact, the general steps are similar to sentence level, but first fine-tune at the sentence level, then calculate the scores of each sentence after splitting the document, take the top n weighted scores, and interpolate with Anserini’s scores to reorder.
Passage Re-ranking with BERT
Generally similar to the previous paper, the dataset is slightly different. The first step also uses the BM25 algorithm to obtain 1000 related candidates, then uses the query as the first sentence and the candidate as the second sentence for BERT scoring, and finally reorders the candidates.
Unlike the above method, the portion of the query that exceeds 64 tokens is truncated, and the total length of the concatenated query and candidate that exceeds 512 is also trimmed. During training, 1000 relevant examples are taken as positive samples, and irrelevant ones as negative samples, with [CLS] vector used for binary classification fine-tuning.
Single Sentence Tagging

Google’s publicly available BERT pre-trained model can be categorized by language into English, Chinese, and multilingual (104 languages). Most of the papers introduced here use the English model directly for fine-tuning, while there is none for Chinese. This paper is the only one that uses multilingual fine-tuning.
75 Languages, 1 Model: Parsing Universal Dependencies Universally
This paper utilizes Stanford’s Universal Dependencies dataset, which contains corpora for as many as 75 languages, covering tasks and tags from morphology to POS and dependency relations, among others.
When I first started in NLP, the first dataset I practiced with was this one, and I am well aware of its difficulties, as many languages are unfamiliar, and it includes various settings (unlabeled, low-resource), and how to set up multi-task training…
This paper directly uses the BERT multilingual pre-trained model for fine-tuning across all languages and tasks.
First, a major issue in multilingual settings is how to segment words, because with so many languages, the vocabulary can be enormous. Here, the authors use BERT’s built-in WordPiece to segment words, then use the output vector of the first sub-word position for prediction.
Regarding multi-tasking, UPOS and UFeats output softmax at each position, and Lemmas is similar to tagging tasks but will have post-processing, while Deps uses the “graph-based biaffine attention parser” proposed by Manning’s group.
Finally, during fine-tuning, single sentences are used with [CLS] input, but it is important to note that the output used is not from the top layer but from a learnable “Layer Attention” that aggregates different layers.
This operation is based on previous research showing that low-level task features (like POS) are primarily in the lower layers, while high-level task features (like dependency) are mainly in the upper layers. The results also confirm this, as shown below.
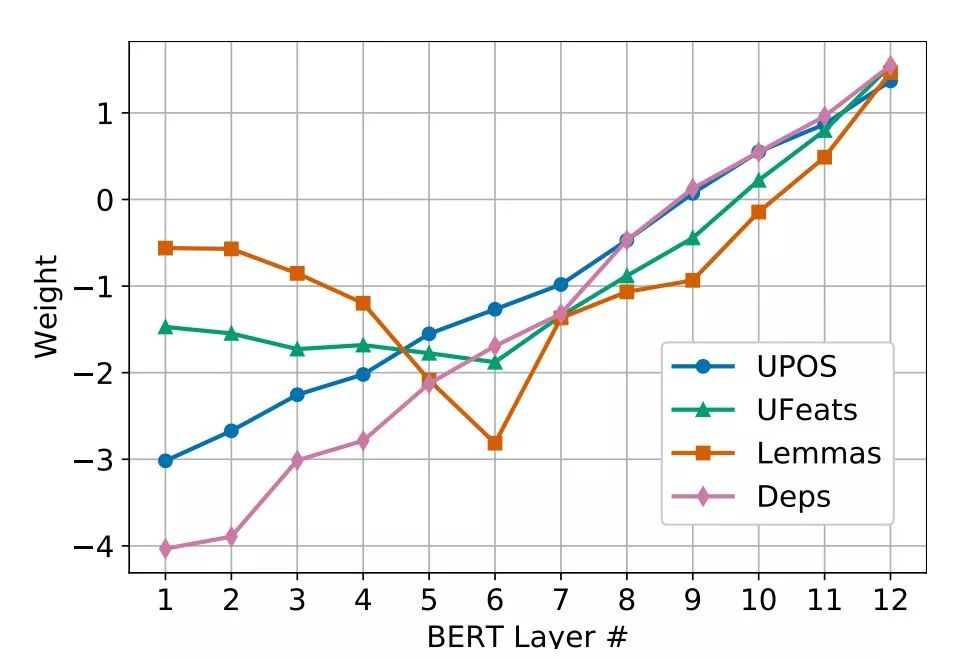
To avoid over-reliance on certain layers, Layer Dropout is also added, where certain layer outputs are randomly excluded during training.
The results show improvements in dependency tasks exceeding previous SOTA, and other tasks reaching competitive levels. The most significant improvement is seen in low-resource fine-tuning.
Sentence Pair Classification + Question Answering

Some papers may not find one standard method sufficient, so they use two simultaneously, which can also be understood as a form of multi-task learning.
A BERT Baseline for the Natural Questions
This primarily targets Google’s own Natural Questions dataset, providing corresponding fine-tuning methods.
The Natural Questions dataset is also a question-answering task, simply put, the query will be the query during a Google search, and the answer may be found in the given related Wikipedia page. The questions can be of various types, including long, short, yes/no, and may even have no answer.
Actually, their approach is quite similar to the question answering in the original paper, but it adds a question classification step. The page document is divided into multiple segments, concatenated with the query, and then predictions are made for the question types using [CLS], while the positions of other tokens predict the range, and finally, the scores of all segments in a large page are ranked to find the highest.
Single Sentence Classification + Tagging
This paper comes from Damo Academy.
BERT for Joint Intent Classification and Slot Filling
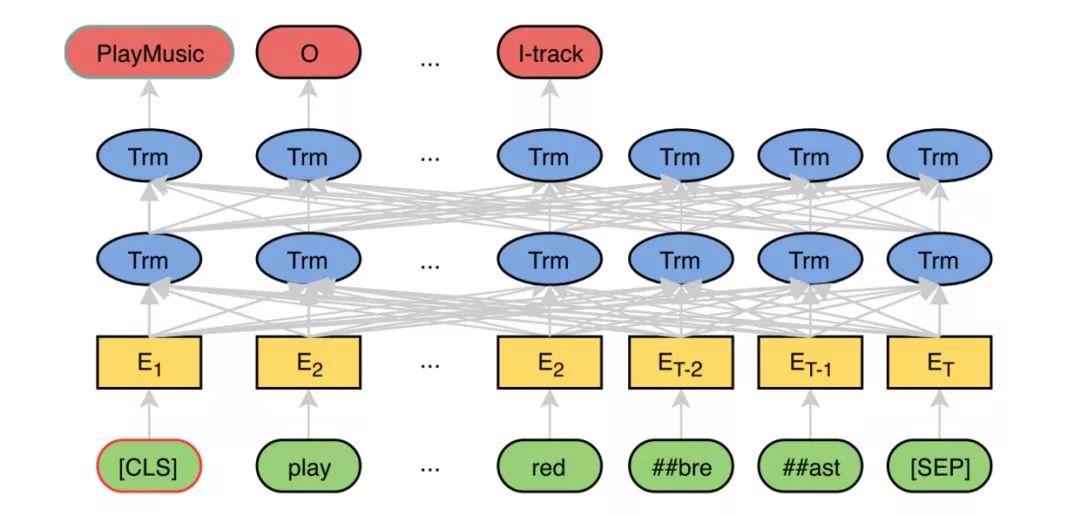
It’s quite simple; it performs fine-tuning directly on the top layer for two tasks. During fine-tuning, it uses multi-tasking, which means joint training. The [CLS] predicts Intent Classification, while other tokens predict Slot Filling.
All-Out Firepower
Since it is possible to perform multi-task fine-tuning with two tasks simultaneously, can all four standard methods be used for fine-tuning? Of course, it can.
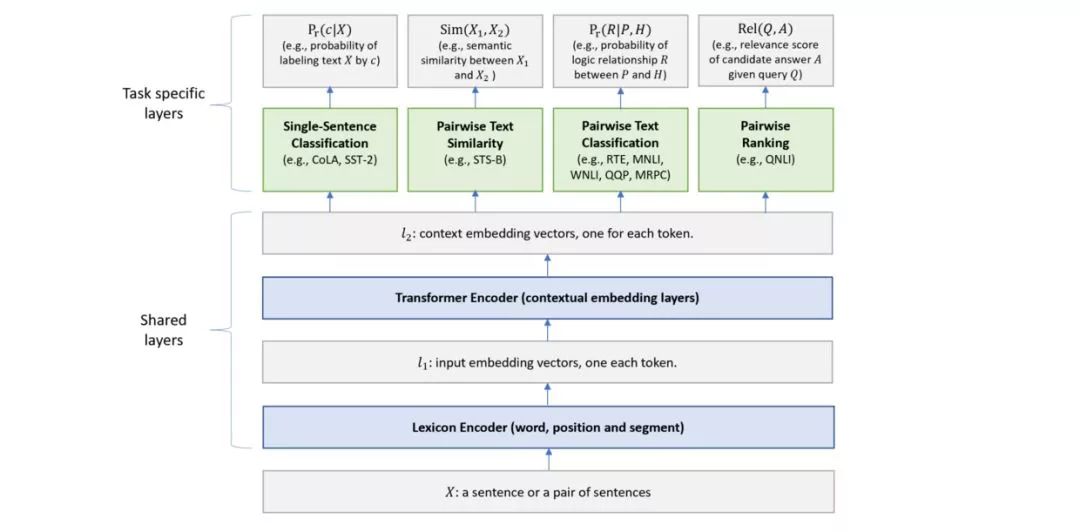
Multi-Task Deep Neural Networks for Natural Language Understanding
This paper from Microsoft, MTDNN, first pre-trains, then fine-tunes tasks from the GLUE dataset simultaneously, ultimately discovering that multi-tasking aids performance.
For detailed training methods, please refer to the paper.
Fancy Fine-Tuning Methods
This section will introduce some papers that use methods different from the standard fine-tuning methods mentioned above, hence the name fancy.
Fine-tune BERT for Extractive Summarization
This paper applies BERT for extractive text summarization, mainly selecting sentences from the text as the final summary. The biggest challenge is how to obtain the vector for each sentence, and then use that vector for binary classification to determine whether to keep or discard.
However, the original BERT model can only generate single sentence vectors or sentence pair vectors.
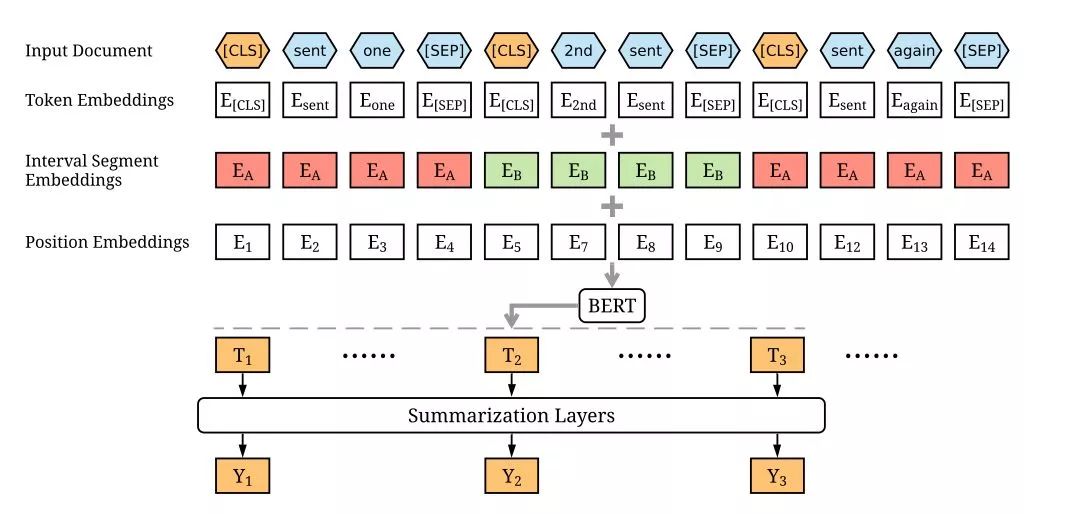
Thus, the authors’ first improvement is to simply add [CLS] and [SEP] before each sentence in the document and feed it into BERT, where each [CLS] corresponds to the position of each sentence’s vector.
To further increase interaction between sentences, the authors add a Transformer Summarization Layer on top of BERT, inputting only each [CLS] vector, and finally outputting a prediction of whether to keep the current sentence, during fine-tuning.
Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence

This paper was included in NAACL2019.
It is used for aspect-based sentiment analysis (ABSA) tasks, mainly by constructing auxiliary sentences to convert the ABSA task into a sentence pair classification task. The method is surprisingly simple yet effective, reminiscent of the early unsupervised GPT2.
Although the fine-tuning process is similar to the sentence pair classification in the standard methods, the method of constructing the second sentence is unique, hence the fancy classification.
The specific approach is to take the original sentence as the first sentence for BERT and then artificially construct the second sentence in four different scenarios (assuming the aspect in the sentence is marked with [ASP] and its corresponding classification is [C]):
-
QA-M: Add “what do you think of the [C] of [ASP]?” at the end of the sentence.
-
NLI-M: Append a sentence like “[ASP]-[C]” at the end.
-
QA-B: Add an affirmative sentence like “the polarity of the aspect [C] of [ASP] is positive” at the end, converting it into a binary classification task.
-
NLI-B: Similarly, directly add the label “[ASP]-[C]-positive” after the constructed sentence.
Then, fine-tune using these methods on BERT for sentence pair classification and compare results. The results show various strengths across different evaluation metrics, as detailed in the paper.
Conditional BERT Contextual Augmentation
This paper is interesting because, unlike previous papers that modify word vectors, it modifies segment vectors.
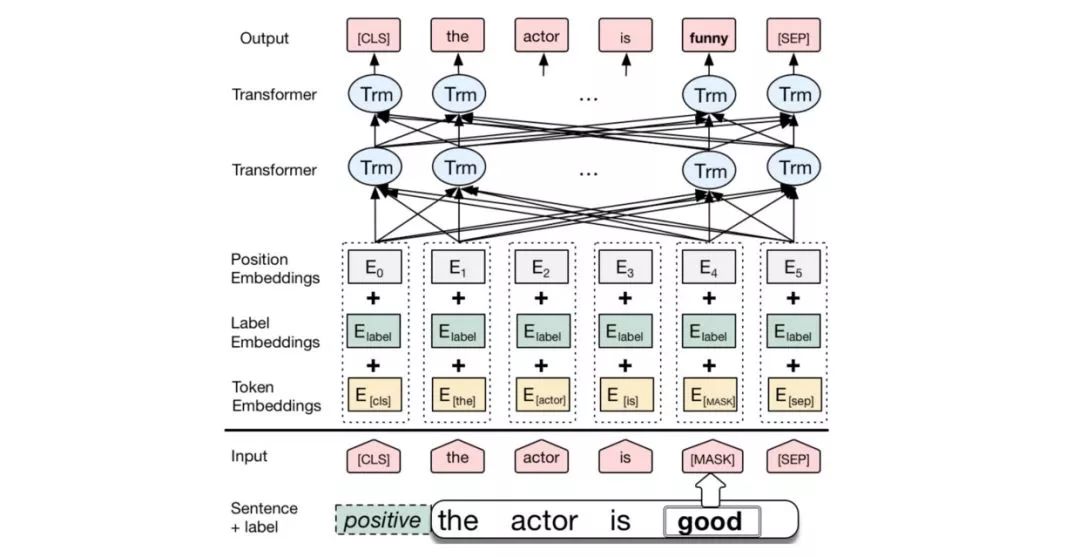
The authors replace the original segment vectors of BERT with label vectors and use a single sentence classification task for fine-tuning. For example, they can use labels like positive or negative from sentiment recognition as labels.
Finally, by replacing the positive vectors with negative ones, or vice versa, they output prediction results for data augmentation, allowing it to only replace the most emotionally charged parts while keeping the overall structure unchanged. This research is also related to style transfer in text.
VideoBERT: A Joint Model for Video and Language Representation Learning
Finally, let’s showcase this paper from Google, which I consider the best.
This paper fine-tunes BERT for video and language multimodal learning, learning the connections between vision and language.
The data utilized cooking videos from YouTube (because language and actions are more closely aligned), where the text information is automatically generated using ASR (Automatic Speech Recognition), and video features are represented using Vector Quantization.
It is particularly noteworthy that this is all unsupervised.
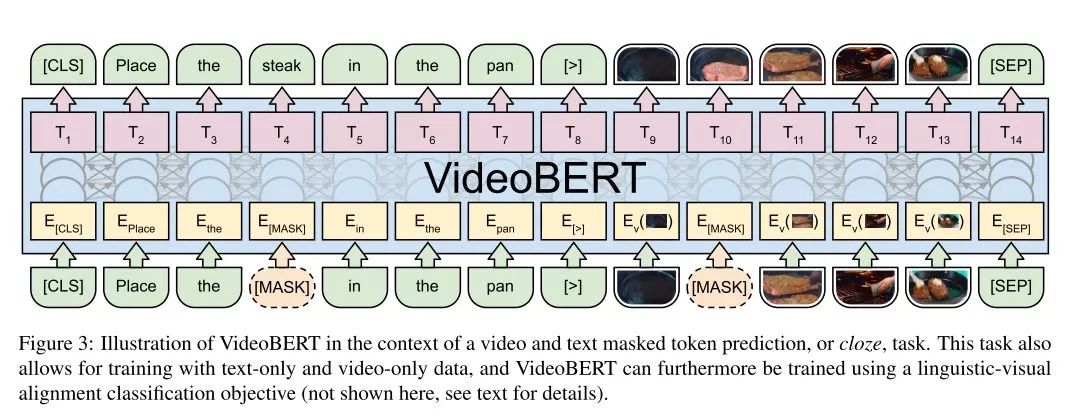
First, the text obtained from ASR serves as the first sentence input to BERT; then, the video feature vectors are tokenized to serve as the second sentence; finally, the original [CLS] is used to determine whether the text and video are consistent.
For the specific process of extracting video features, the S3D model is used (see Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification, recommended reading) to extract video features, which are 1024 dimensions.
Then, hierarchical clustering is used to tokenize these features, totaling 12^4=20736 tokens, which are added as new words to the vocabulary. Finally, similar to BERT pre-training, some tokens (both text and video tokens) are randomly masked, and the masked parts and whether the sentences correspond are predicted, during fine-tuning.
When used, the following two examples can illustrate this.
-
Image classification. The second sentence input is video information, and the first sentence is “now let me show you how to [MASK] the [MASK]”, allowing it to directly obtain the actions and objects in the video at the [MASK] position (amazing!).
-
Subtitle generation. Similar to the first case, but the second sentence uses “now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK].” Then, the obtained vectors at the [MASK] positions are concatenated with the video information vectors for the next step of subtitle generation.
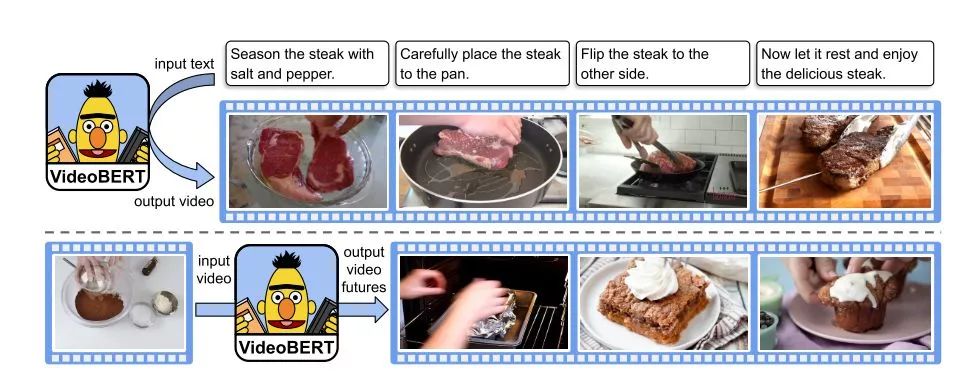
In summary, this is truly a fancy piece of research.
Bonus
In addition to all the fine-tuning methods mentioned above, I would like to mention one fine-tuning method that does not appear as a standalone paper but is mentioned in a section of a large batch training BERT paper.
The problem in the paper is that, to speed up training, a technique was used to divide training into two phases. In the first phase, training was done with a batch size of 64k at a length of 256; in the second phase, training was done with a batch size of 32k at a length of 512.
The second phase can also be seen as a form of fine-tuning, specifically fine-tuning the position vectors that have not been utilized in the previous papers. It can be viewed as pre-training on only 256 position vectors and then expanding to 512 positions for fine-tuning. Therefore, some fine-tuning techniques were also used in it, such as a re-warmup process in the second phase.
Intern/Full-time Editor Journalist Recruitment
Join us to personally experience every detail of writing for a professional technology media outlet, growing alongside a group of the best people in the most promising industry. Located in Beijing, at the East Gate of Tsinghua University, reply with “Recruitment” on the Big Data Digest homepage chat page for details. Please send your resume directly to [email protected]