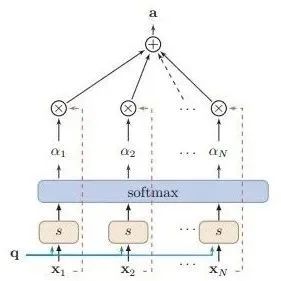
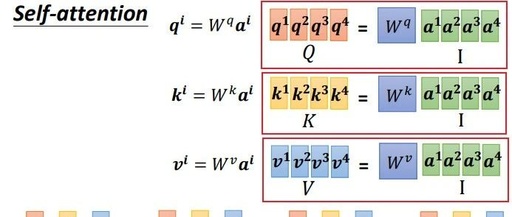
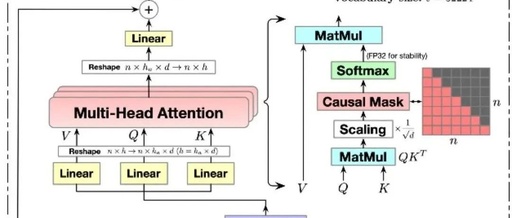
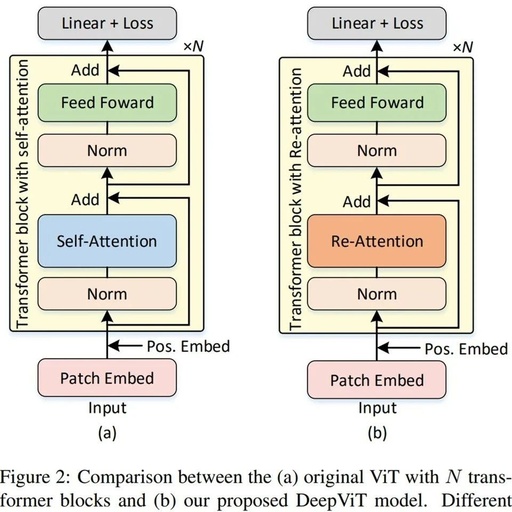
Re-Attention Mechanism in Transformers: Enhancing Performance
Click above toJoin the Computer Vision Alliance for more insights For academic sharing only, does not represent the stance of this public account, contact for removal if infringing Reprinted from: Machine Heart Recommended AI Doctor’s Notes Series Zhuhua Zhou’s “Machine Learning” hand-pushed notes have officially been open-sourced! Printable version with PDF download link attached CNN … Read more