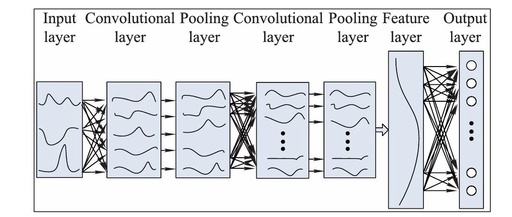
TensorFlow Lite Empowers Product Implementation

By / Development Technology Promotion Engineer Khanh LeViet TensorFlow Lite (tensorflow.google.cn/lite) is the official framework for running TensorFlow model inference on edge devices. TensorFlow Lite is deployed on over 4 billion edge devices worldwide and supports IoT devices and microcontrollers based on Android, iOS, and Linux. Since the initial release of TensorFlow Lite at the … Read more