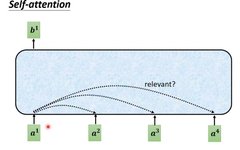
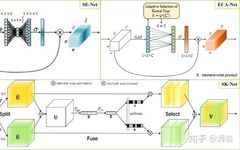
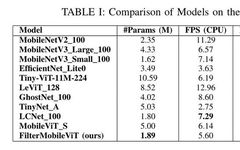
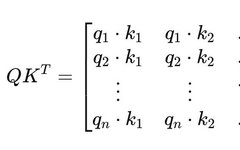Three Steps to Large Kernel Attention: Tsinghua’s VAN Surpasses SOTA ViT and CNN

Source: Machine Heart This article is approximately 2774 words long and is recommended to be read in 13 minutes. This article introduces a novel large kernel attention module proposed by researchers from Tsinghua University and Nankai University, and constructs a new neural network named VAN that outperforms SOTA visual transformers based on LKA. As a … Read more