
-
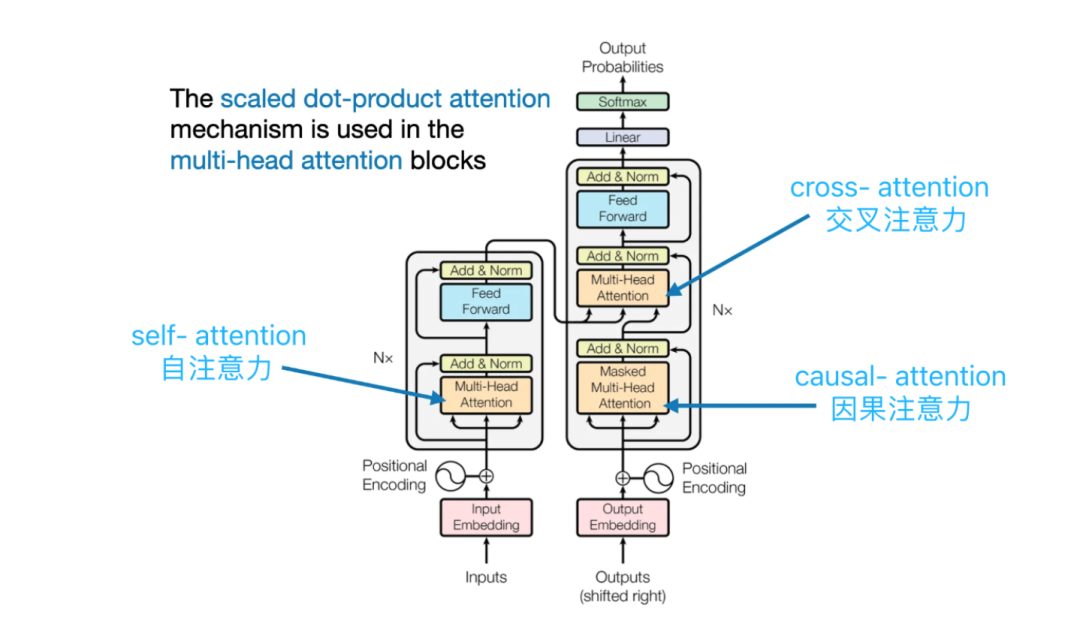
In the “encoder-decoder attention” layer, queries come from the previous layer of the decoder, while memory keys and values come from the output of the encoder. This allows each position in the decoder to attend to all positions in the input sequence. This mimics the typical encoder-decoder attention mechanism in sequence-to-sequence models.
-
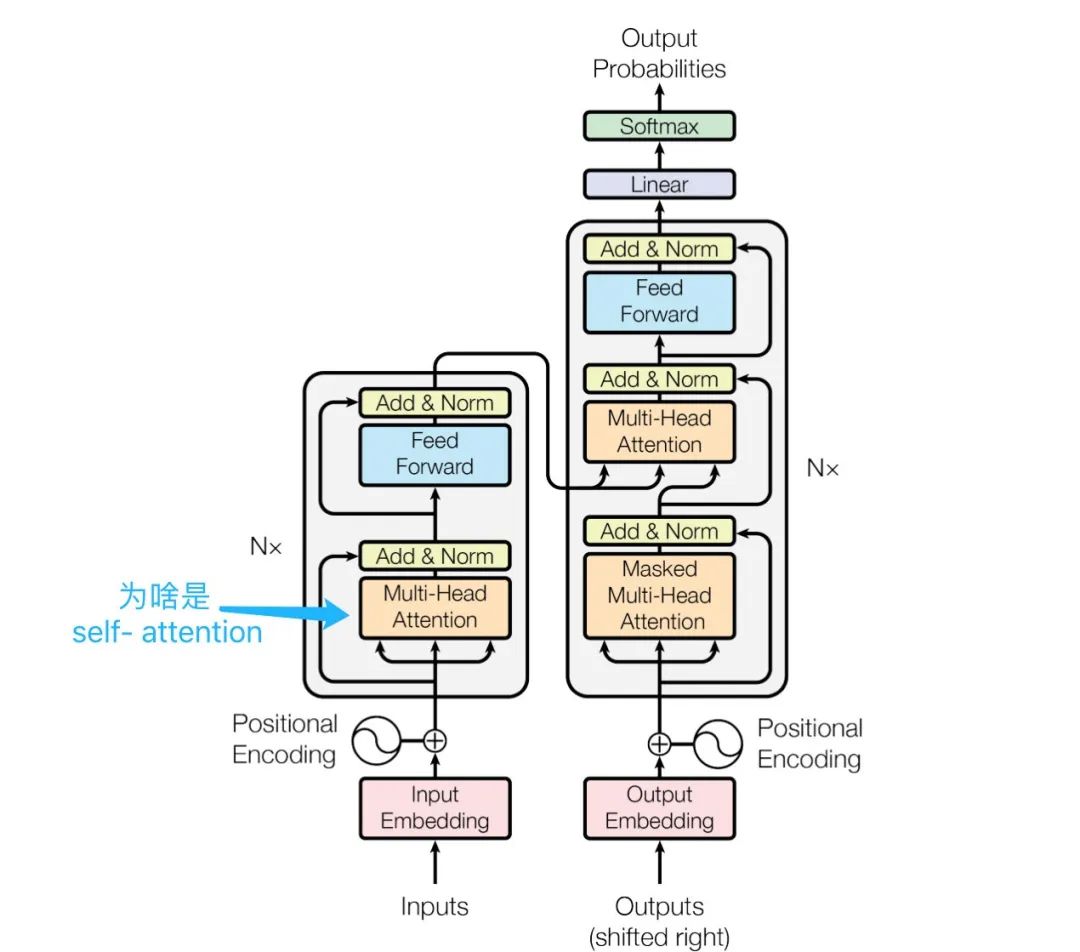
The encoder contains a self-attention layer. In the self-attention layer, all keys, values, and queries come from the same place, i.e., the output of the previous layer of the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
-
Similarly, the self-attention layer in the decoder allows each position in the decoder to attend to all positions in the decoder, including that position itself. We need to prevent information from flowing leftward in the decoder to maintain the autoregressive property. We achieve this by masking all values corresponding to illegal connections in the softmax input (setting them to -∞).
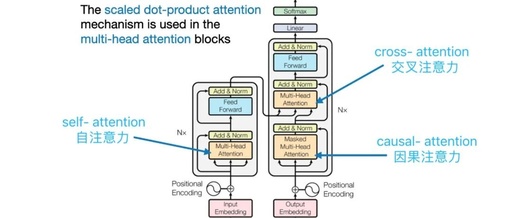
This article will cover Self Attention、Cross Attention、Causal Attention three aspects, helping you understand the three attention mechanisms in Transformer at a glance. (Every article’s standard opening must not be less; no matter how hard or tiring life is, the sense of ritual cannot be lacking.)
Three Attention Mechanisms in Transformer
1. Self Attention
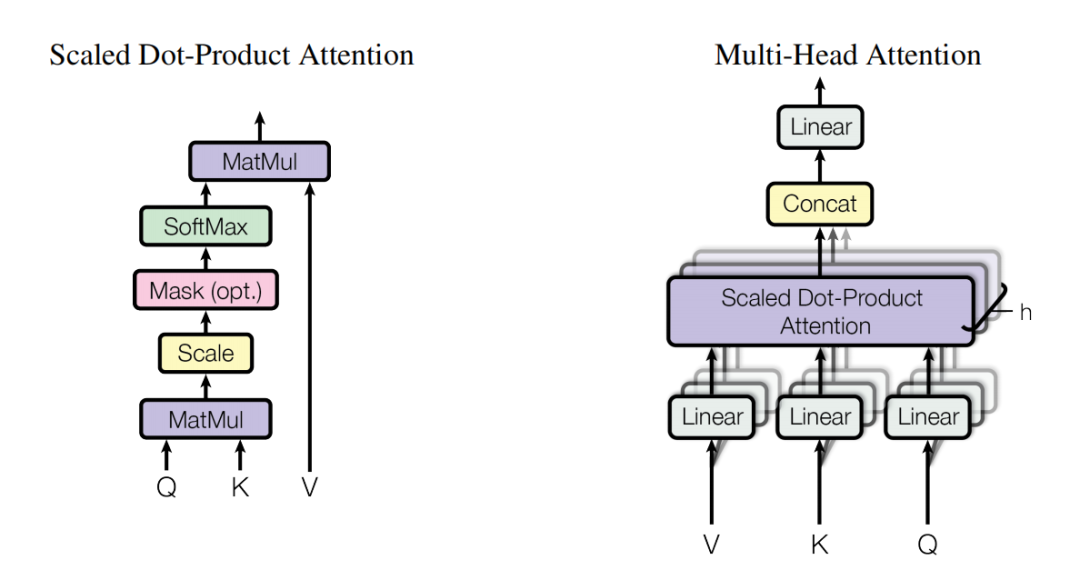
Scaled Dot-Product Attention and Multi-Head Attention
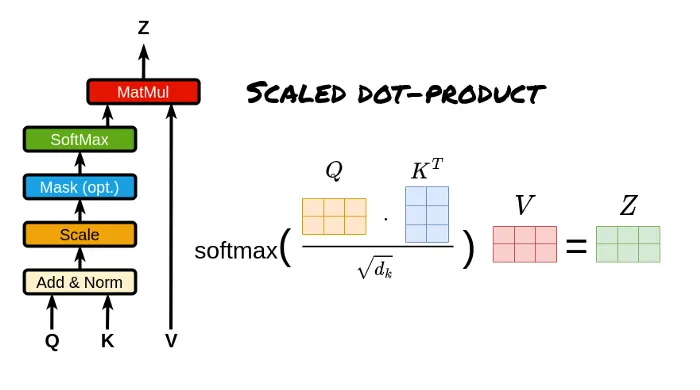
Self Attention:For the same sequence, the attention scores are calculated using scaled dot-product attention, and the value vectors are weighted and summed to obtain the weighted representation of each position in the input sequence.
It expresses an attention mechanism, how to use scaled dot-product attention to calculate the attention scores for the same sequence, thus obtaining the attention weights for each position in the same sequence.
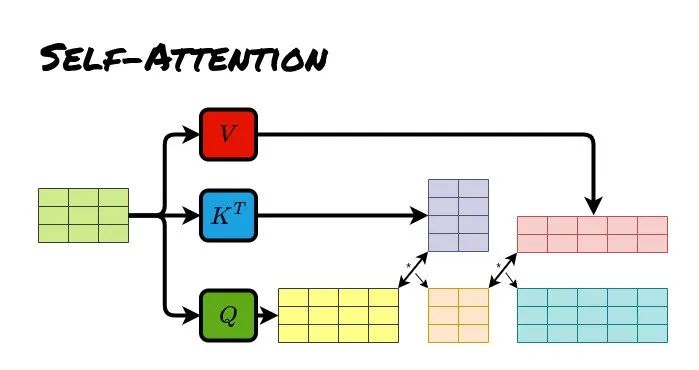
Self Attention
It emphasizes a practical method; in practice, we do not use a single dimension to execute a single attention function, but instead calculate with h=8 heads separately and then take a weighted average to avoid errors from individual calculations.
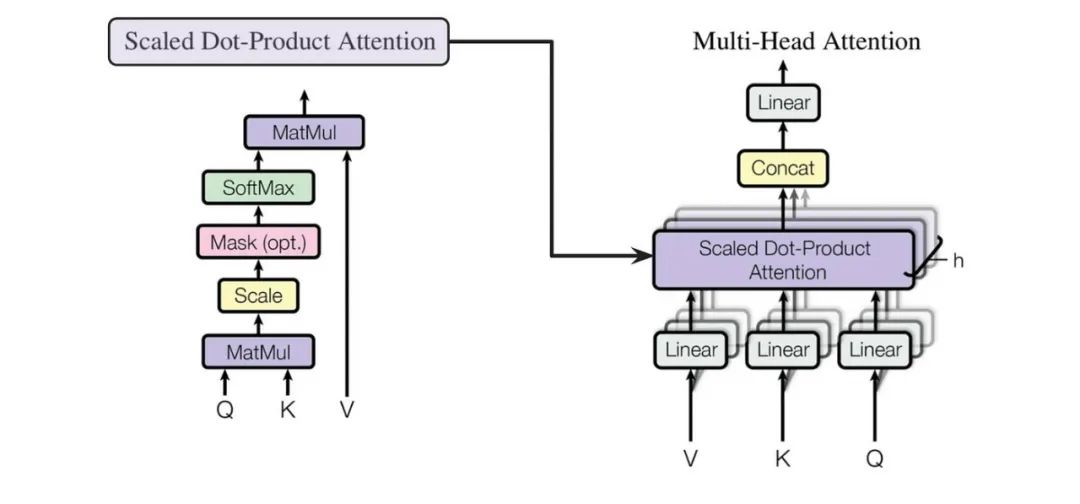
Multi-Head Attention (Multi-Head Attention)
Question Answer:Scaled Dot-Product Attention, Self Attention, and Multi-Head Attention actually refer to the same thing, explaining from different dimensions how to obtain the attention weights for each position in the same sequence. The diagram labeled Multi-Head Attention emphasizes the need for multiple heads to calculate attention weights.
The first attention in Transformer (Self Attention) A more rigorous description should be: the input sequence of the encoder calculates attention weights through Multi-Head Self Attention.
2. Cross Attention
Question 2: The encoder clearly states Multi-Head Attention in the diagram, so why is it called Cross Attention?
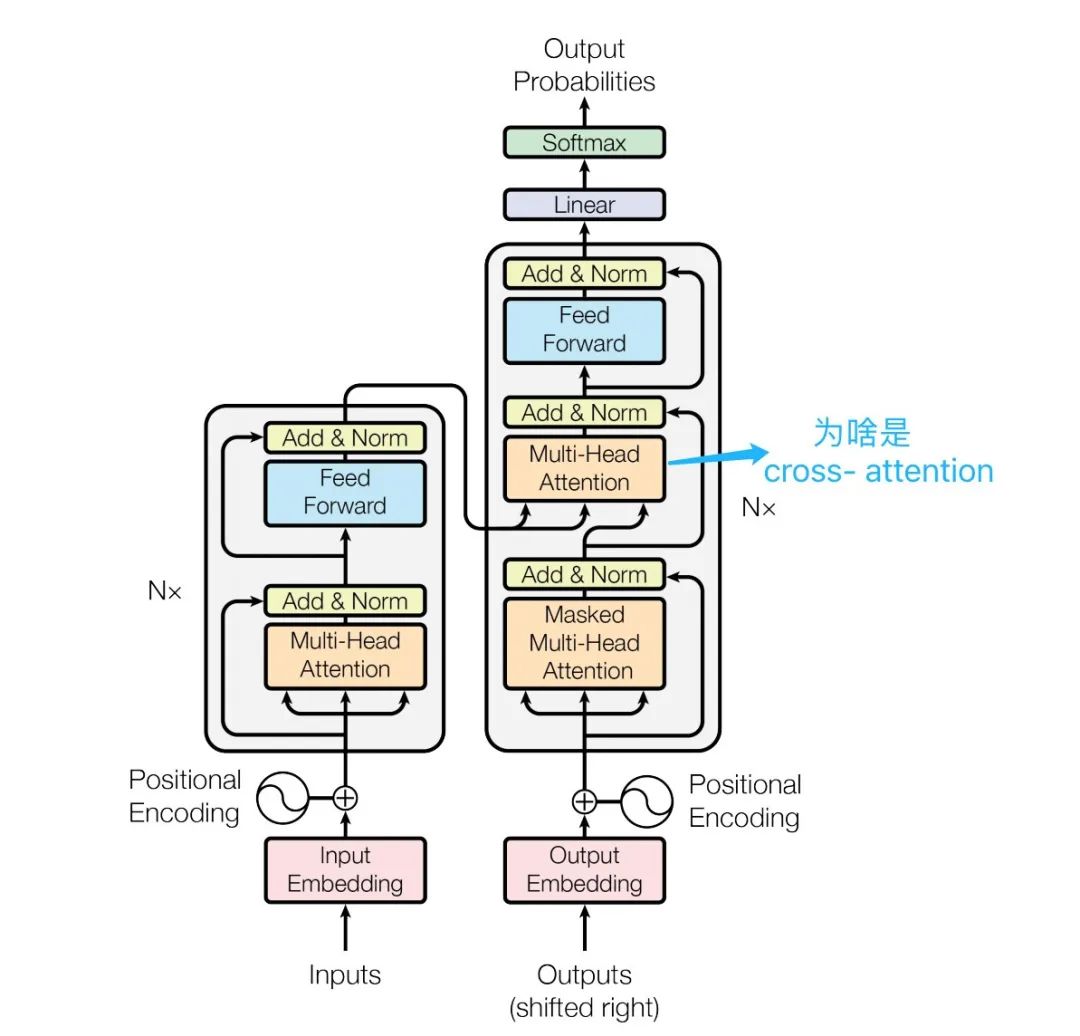
Cross Attention of Encoder-Decoder
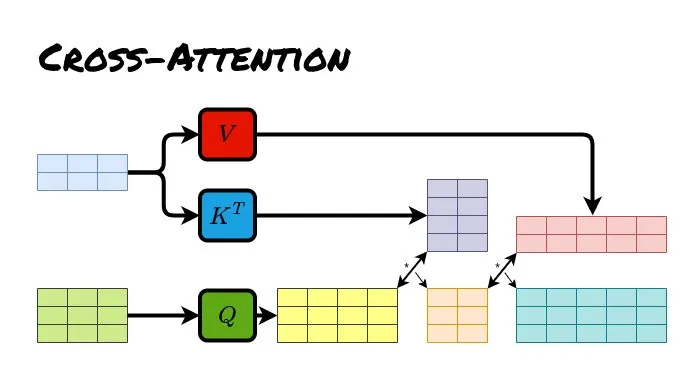
Cross Attention (Cross Attention)
-
Input Source:
-
Cross Attention: Comes from two different sequences, one from the encoder and one from the decoder
-
Self Attention: Comes from the same sequence of the encoder
-
Implementation Goal:
-
Cross Attention: The decoder sequence serves as the query (Q), while the encoder sequence provides keys (K) and values (V), used for attention transfer between the two different sequences of encoder-decoder. -
Self Attention: Queries (Q), keys (K), and values (V) all come from the same sequence of the encoder, achieving attention calculation within the encoder sequence.
Question Answer:Cross Attention and Multi-Head Attention actually refer to the same thing, explaining from different dimensions how to achieve attention transfer between two different sequences. The diagram labeled Multi-Head Attention emphasizes the need for multiple heads to perform attention transfer calculations.
The second attention in Transformer (Cross Attention) A more rigorous description should be: the two sequences of encoder-decoder perform attention transfer through Multi-Head Cross Attention.
Question 3: The encoder clearly states Masked Multi-Head Attention in the diagram, so why is it called Causal Attention?
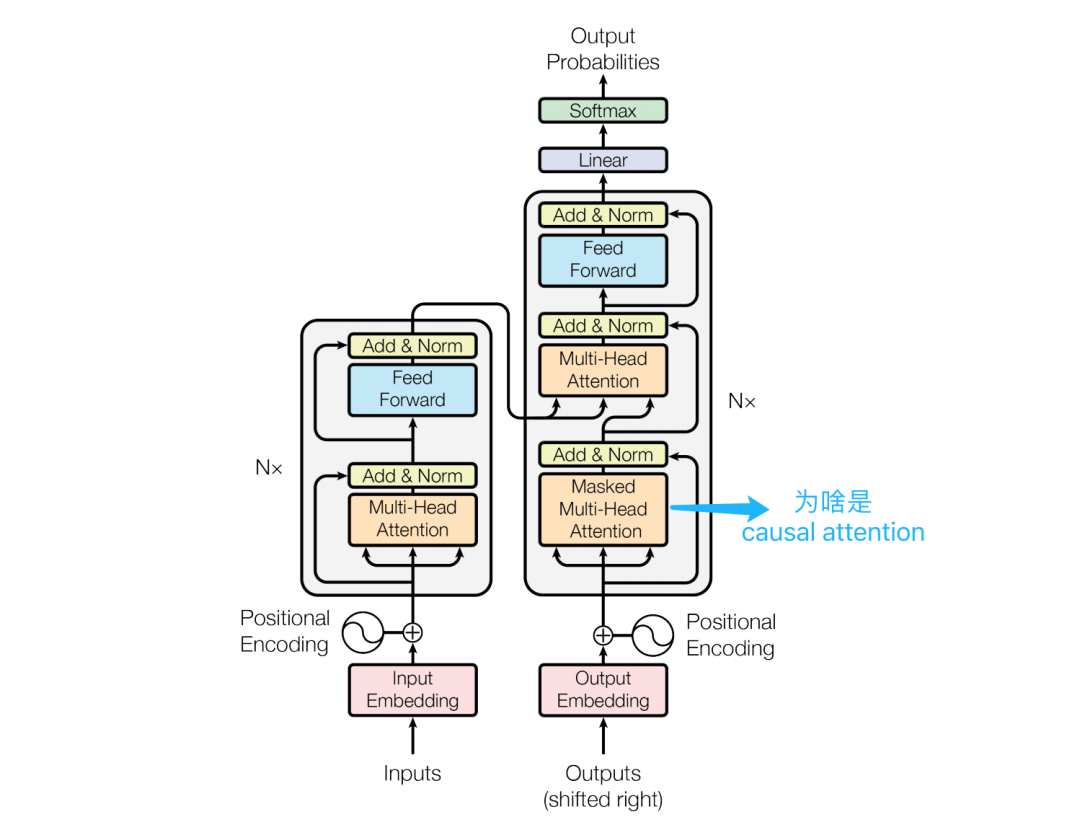
Causal Attention of Decoder
Predict The Next Word( Predicting the Next Word): The model usually needs to predict the next word based on the words that have already been generated. This characteristic requires the model not to “see” future information when making predictions, to avoid predictions being influenced by future information.
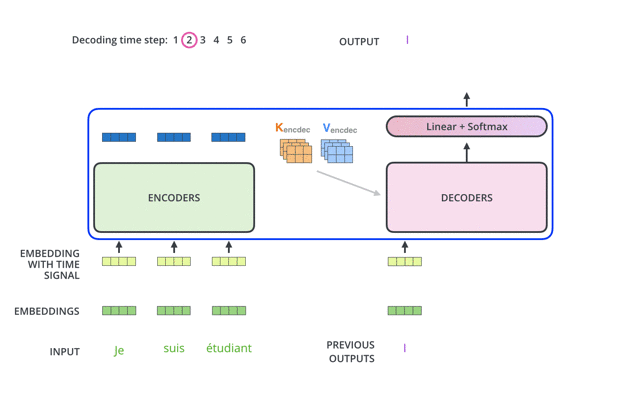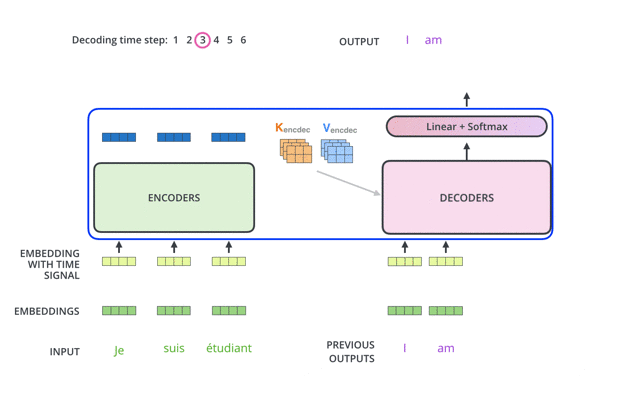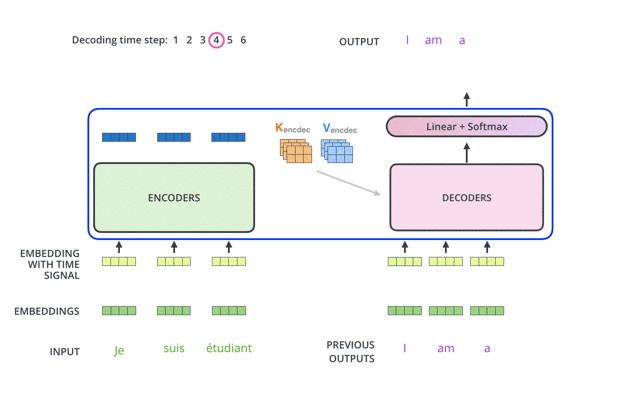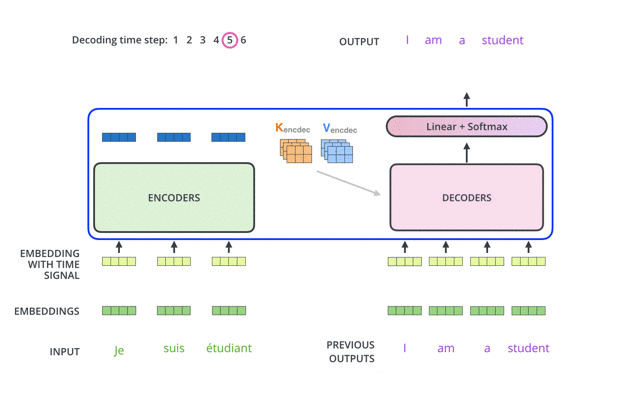
Predicting the Next Word
Masked Language Model(Masked Language Model): Masking some words to help the model learn to predict the masked words, thereby helping the model learn language patterns.
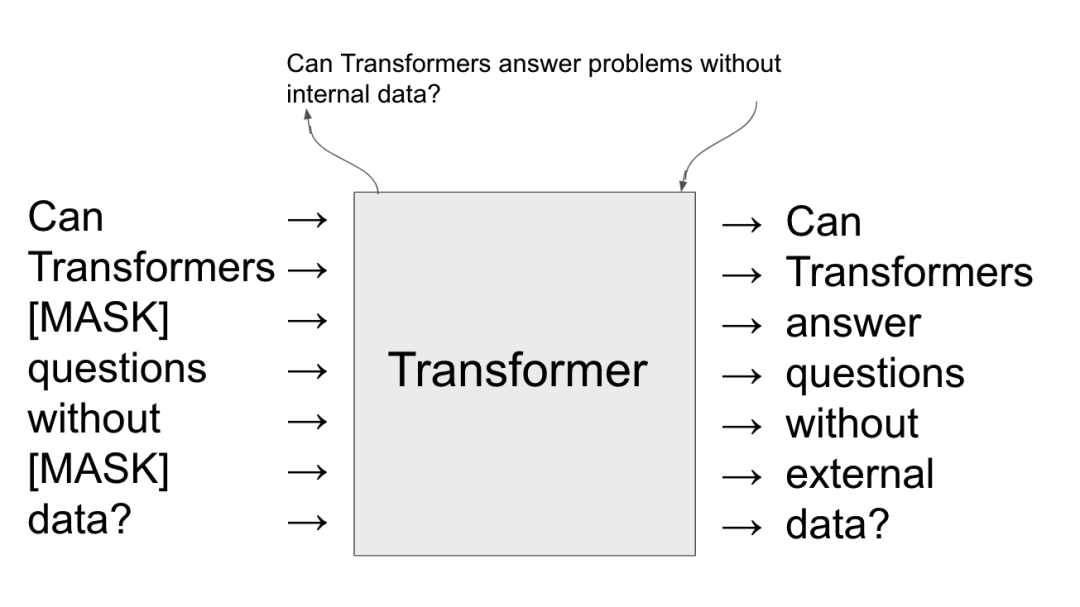
Masked Language Model
Autoregressive(Autoregressive): When generating a certain word in a sequence, the decoder considers all previously generated words, including the current word being generated. To maintain the autoregressive property, that is, the model can only predict based on already generated information when generating a sequence, we need to prevent information from flowing leftward in the decoder. In other words, when the decoder is generating the t-th word, it should not see future information (i.e., the t+1, t+2,… positions).
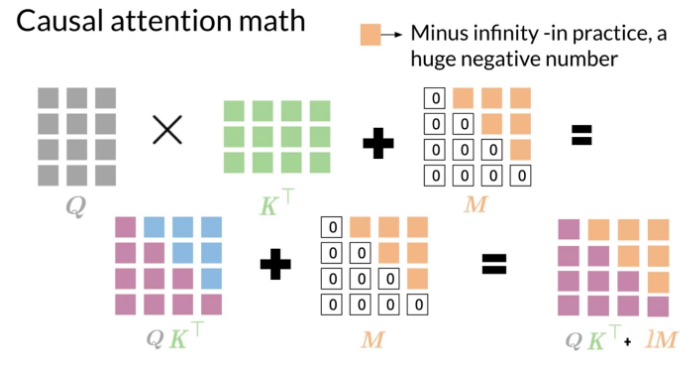
Causal Attention (Causal Attention): To ensure the model only relies on previous input information when generating sequences and is not influenced by future information. Causal Attention achieves this by masking (masking) future positions, allowing the model to see only the current position and previous inputs when predicting the output of a certain position.
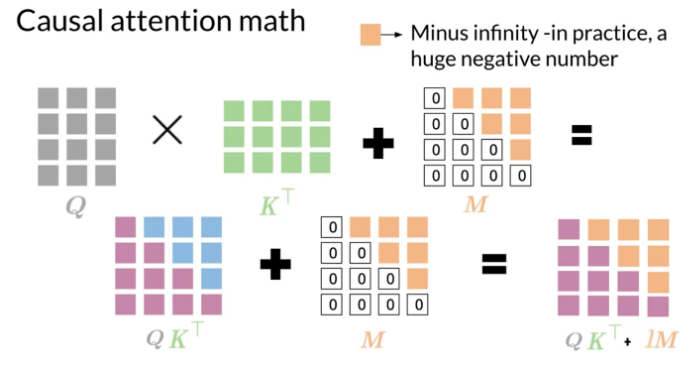
Causal Attention (Causal Attention)
Question Answer:Causal Attention and Masked Multi-Head Attention actually refer to the same thing, how Self Attention in the decoder combines with Causal Attention to maintain autoregressive properties.
Masked Multi-Head Attention emphasizes the use of multiple independent attention heads, each of which can learn different attention weights, thereby enhancing the model’s representation ability. Causal Attention emphasizes that the model can only rely on already generated information when making predictions and cannot see future information.
The third attention in Transformer (Causal Attention) A more rigorous description should be: the single sequence of the decoder calculates attention through Multi-Head Causal Self Attention (Multi-Head Causal Self Attention).