Attention Mechanism Bug: Softmax as the Culprit Affecting All Transformers
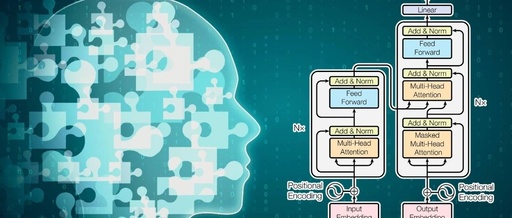
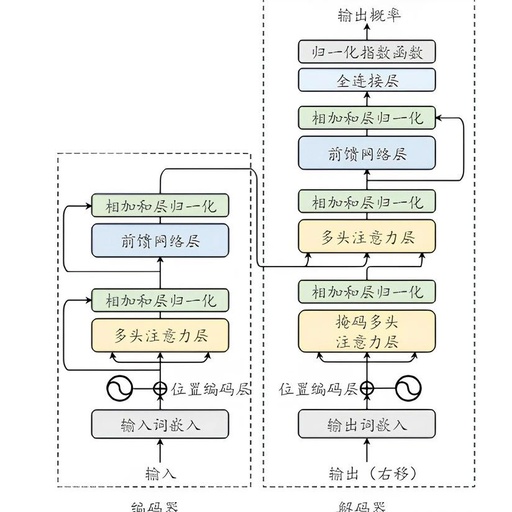
“I found a bug in the attention formula, and no one has noticed it for eight years. All Transformer models, including GPT and LLaMA, are affected.” Recently, a statistical engineer named Evan Miller has stirred up a storm in the AI field with his statement. We know that the attention formula in machine learning is … Read more