Big Data Digest authorized reprint from Data Pie
Compiled by:Sun Siqi, Cheng Yu, Gan Zhe, Liu Jingjing
In the past year, there have been many breakthrough advancements in the research of language models, such as GPT, which generates sentences that are convincingly realistic [1]; BERT, XLNet, RoBERTa [2,3,4], etc., have swept various NLP rankings as feature extractors. However, the parameter counts of these models are also astonishing, with BERT-base having 109 million parameters and BERT-large reaching 330 million parameters, resulting in excessively slow model runtime. To improve model runtime, this paper first proposes a new Knowledge Distillation [5] method to compress the model, saving runtime and memory without losing too much accuracy. The article was published in EMNLP 2019.
“Patient Knowledge Distillation” Model
Specifically, for sentence classification tasks, when a regular knowledge distillation model is used for model compression, it often loses a lot of accuracy. The reason is that the student model only learns the probability distribution predicted by the teacher model and completely ignores the representations of the intermediate hidden layers.
Just like when a teacher teaches a student, if the student only remembers the final answer but completely neglects the intermediate process, the probability of the student model making mistakes when encountering new problems is higher. Based on this assumption, the paper proposes a loss function that brings the hidden layer representations of the student model closer to those of the teacher model, thus enhancing the generalization ability of the student model. This model is referred to as the “Patient Knowledge Distillation” model (PKD).
Since the predictions for sentence classification problems are based on the feature representation of the [CLS] character, such as adding two fully connected layers on top of this feature, the researchers proposed a new loss function that allows the model to learn the feature representation of the [CLS] character simultaneously:
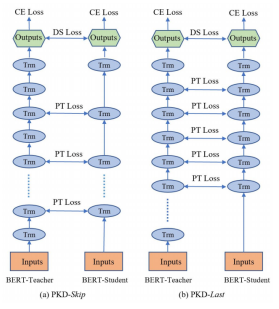
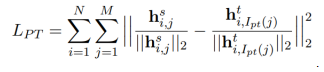 Where M is the number of layers in the student model (e.g., 3, 6), N is the number of layers in the teacher model (e.g., 12, 24), h is the representation of [CLS] in the model’s hidden layers, and i, j indicate the correspondence between student-teacher hidden layers, as shown in the figure below. For example, for a 6-layer student model learning from a 12-layer teacher model, the student model can learn the representations of the teacher model’s hidden layers (2,4,6,8,10) (left PKD-skip), or the representations of the last few layers of the teacher model (7,8,9,10,11, right PKD-last). The last layer is skipped because it directly learns the predicted probabilities from the teacher model, thus omitting the learning of the last hidden layer.
Where M is the number of layers in the student model (e.g., 3, 6), N is the number of layers in the teacher model (e.g., 12, 24), h is the representation of [CLS] in the model’s hidden layers, and i, j indicate the correspondence between student-teacher hidden layers, as shown in the figure below. For example, for a 6-layer student model learning from a 12-layer teacher model, the student model can learn the representations of the teacher model’s hidden layers (2,4,6,8,10) (left PKD-skip), or the representations of the last few layers of the teacher model (7,8,9,10,11, right PKD-last). The last layer is skipped because it directly learns the predicted probabilities from the teacher model, thus omitting the learning of the last hidden layer.
Validating the Hypothesis
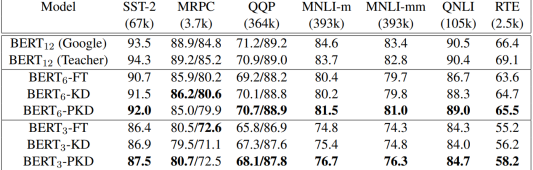
The researchers compared the proposed model with model fine-tuning and normal knowledge distillation on 7 benchmark datasets for sentence classification. When distilling a 12-layer teacher model to a 6-layer or 3-layer student model, PKD generally outperformed both baseline models in most cases. Furthermore, on five datasets, SST-2 (compared to the teacher model -2.3% accuracy), QQP (-0.1%), MNLI-m (-2.2%), MNLI-mm (-1.8%), and QNLI (-1.4%) performed close to the teacher model. Specific results can be found in Figure 1. This further validates the researchers’ hypothesis that student models learning hidden layer representations will outperform those that only learn the teacher’s predicted probabilities.
Figure 1
In terms of speed, the 6-layer transformer model can nearly double the inference speed, reducing the total parameter count by 1.64 times; while the 3-layer transformer model can increase speed by 3.73 times, reducing the total parameters by 2.4 times. Specific results can be found in Figure 2.
Figure 2
-
Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI Blog 1.8 (2019).
-
Devlin, Jacob, et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
-
Yang, Zhilin, et al. “XLNet: Generalized Autoregressive Pretraining for Language Understanding.” arXiv preprint arXiv:1906.08237 (2019).
-
Liu, Yinhan, et al. “RoBERTa: A robustly optimized BERT pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
-
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
Siqi Sun: is a Research SDE at Microsoft. He is currently working on commonsense reasoning and knowledge graph-related projects. Prior to joining Microsoft, he was a PhD student in computer science at TTI Chicago, and before that, he was an undergraduate student from the School of Mathematics at Fudan University.
Yu Cheng: is a senior researcher at Microsoft. His research is about deep learning in general, with specific interests in model compression, deep generative models, and adversarial learning. He is also interested in solving real-world problems in computer vision and natural language processing. Yu received his Ph.D. from Northwestern University in 2015 and his bachelor’s from Tsinghua University in 2010. Before joining Microsoft, he spent three years as a Research Staff Member at IBM Research/MIT-IBM Watson AI Lab.
Zhe Gan: is a senior researcher at Microsoft, primarily working on generative models, visual QA/dialog, machine reading comprehension (MRC), and natural language generation (NLG). He also has broad interests in various machine learning and NLP topics. Zhe received his PhD degree from Duke University in Spring 2018. Before that, he received his Master’s and Bachelor’s degree from Peking University in 2013 and 2010, respectively.
Jingjing (JJ) Liu: is a Principal Research Manager at Microsoft, leading a research team in NLP and Computer Vision. Her current research interests include Machine Reading Comprehension, Commonsense Reasoning, Visual QA/Dialog, and Text-to-Image Generation. She received her PhD degree in Computer Science from MIT EECS in 2011. She also holds an MBA degree from Judge Business School at the University of Cambridge. Before joining MSR, Dr. Liu was the Director of Product at Mobvoi Inc and a Research Scientist at MIT CSAIL.
The code has been open-sourced at:
https://github.com/intersun/PKD-for-BERT-Model-Compression
Intern/Full-Time Editor Journalist Recruitment
Join us to experience every detail of a professional technology media’s writing, grow with a group of the best people in the most promising industry. Located at Tsinghua East Gate, Beijing, reply with “Recruitment” on the Big Data Digest homepage dialogue page for details. Please send your resume directly to [email protected]
People who click “Looking” have become more attractive!