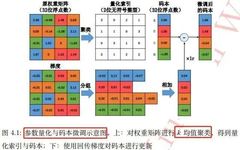
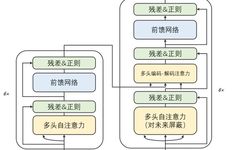
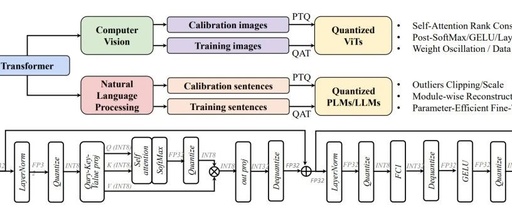
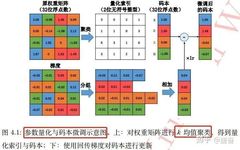
Summary of Convolutional Neural Network Compression Methods
Click on the above “Beginner Learning Vision”, choose to add Star Mark or Top. Important content delivered at the first time For academic sharing only, does not represent the position of this public account, contact for deletion if infringing Reprinted from: Author | Tang Fen@Zhihu Source | https://zhuanlan.zhihu.com/p/359627280 Editor | Jishi Platform We know that … Read more