Simplifying Transformer Structure for Lightweight CLIP Training on RTX 3090

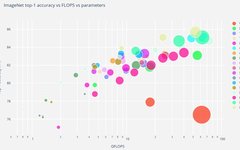
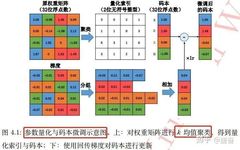
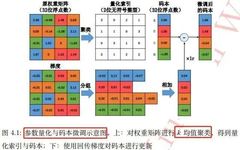
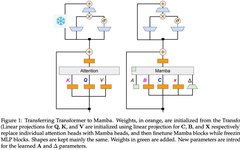
Contrastive Language-Image Pre-training (CLIP) has gained wide attention for its excellent zero-shot performance and outstanding transferability. However, training such large models typically requires substantial computation and storage, posing a barrier for general users with consumer-grade computers. To address this observation, this paper explores how to achieve competitive performance using only an Nvidia RTX 3090 GPU … Read more