
Selected from arXiv
Authors: Chenguang Wang, Mu Li, Alexander J. Smola
Compiled by Machine Heart
Participation: Panda
BERT and GPT-2 are currently the two most advanced models in the field of NLP, both adopting a Transformer-based architecture. A recent paper from Amazon Web Services proposed several new improvements to Transformers, including architectural enhancements, leveraging prior knowledge, and a new architecture search method that can yield more efficient language models.

Transformers outperform RNN-based models in computational efficiency. Recent findings with GPT and BERT have shown that when using large-scale pre-trained language models, Transformers can efficiently handle various NLP tasks. Surprisingly, these Transformer architectures are suboptimal for the language models themselves. In Transformers, neither self-attention nor positional encoding can integrate the word-level sequential context that is crucial for language modeling.
This paper explores efficient Transformer architectures for language models, including the addition of extra LSTM layers to capture sequential context while maintaining computational efficiency. We propose Coordinate Architecture Search (CAS), which can find efficient architectures through iterative optimization of the model. Experimental results on PTB, WikiText-2, and WikiText-103 show that CAS achieves a perplexity between 20.42 and 34.11 on all tasks, improving perplexity by an average of 12.0 compared to the previous best LSTM methods.
Introduction
Modeling sequential context in language is key to the success of many NLP tasks. Recurrent Neural Networks (RNNs) can memorize sequential context in carefully designed units. However, the sequential nature of these models makes their computational cost high, making it difficult to scale them for large corpora.
The Transformer architecture uses self-attention and point-wise fully connected layers instead of RNN units; these layers are highly parallelizable, thus reducing computational costs. Coupled with positional encoding, Transformers can derive long-range dependencies through vague relative token positions. This results in coarse-grained sentence-level sequential representations. Recent research findings with GPT (or GPT-2) and BERT show that representations learned on large-scale language modeling datasets can effectively optimize sentence-level tasks (such as the GLUE benchmark) and can also optimize token-level tasks that do not rely on word order dependencies in the context (such as question answering and named entity recognition).
Despite the fact that both GPT and BERT use language models for pre-training, they have not achieved the current best in language modeling. The goal of a language model is to predict the next word based on previous context, which requires fine-grained contextual word order information. Existing self-attention and positional encoding in Transformer architectures do not effectively model this information.
The second challenge (and opportunity) arises from the fact that we often have the opportunity to obtain models pre-trained on related but not identical tasks. For example, neither GPT nor BERT has been fine-tuned for WikiText, nor have they been directly aimed at minimizing perplexity. In fact, these architectures may even have no direct utility: BERT provides an estimate of p(w_i | context) rather than p(w_i | history). This indicates that for the network space that can be derived from these tasks (and adapted), we need to design algorithms that can systematically explore them. This generalizes to the problem of using pre-trained word embeddings for related tasks, except that we are not dealing with vectors here, but entire networks.
Finally, the architecture search problem itself has received significant attention. However, the cost of the dataset required to train a single model for GPT or BERT can exceed $10,000, making it impractical to perform complete model exploration through complete retraining. In contrast, we propose a far more constrained (and economical) method to investigate how to optimize a trained architecture, thereby achieving architecture search. This cost is much lower. Our pragmatic approach can enhance the current best performance on language modeling problems. We have the following contributions:
-
We propose a Transformer architecture for language models. Adding LSTM layers after all Transformer modules is effective (this is a result of the search algorithm). This can capture fine-grained word-level sequential context.
-
We describe an efficient search process: Coordinate Architecture Search (CAS). This algorithm can randomly generate variants of Transformer architectures based on the currently found best architecture. Due to this greedy nature, CAS is simpler and faster than previous architecture search algorithms.
-
We demonstrate how to integrate a large amount of prior knowledge using GPT or BERT. The cost of obtaining this information using brute-force architecture search would be extremely high.
Contributions 2 and 3 are general and can be used in many cases outside the NLP field. Contribution 1 should be more specific to language. We evaluated CAS on three commonly used language modeling datasets: PTB, WikiText-2, and WikiText-103. Compared to the current best LSTM-based language model AWD-LSTM-MoS, the BERT-based CAS achieved an average gain of 12.0 in perplexity.
Transformers for Language Models
Our Transformer architecture is based on GPT and BERT. We will reuse the weights pre-trained in GPT and BERT to optimize the language model. We will modify and retrain the weights and networks used in GPT and BERT to adapt to the language modeling task.
GPT and BERT
GPT uses a variant of the Transformer architecture, specifically a language model based on a multi-layer Transformer decoder. Its original paper provides a pre-trained architecture with only 12 layers of Transformer decoders. Each module has a hidden size of 768 and 12 self-attention heads. The weights are trained on BooksCorpus. This allows it to generate p(wi | history), one word at a time.
BERT is a multi-layer bidirectional Transformer encoder. Its original paper provides two BERT structures: BERT-Base and BERT-Large. BERT-Base consists of 12 layers of bidirectional Transformer encoder modules, with a hidden size of 768 and 12 self-attention heads. BERT-Large contains 24 layers of bidirectional Transformer encoder modules, with a hidden size of 1024 and 16 self-attention heads. The weights are trained on BooksCorpus and English Wikipedia. Unless otherwise specified, when we refer to BERT, we mean BERT-Base.
What is the relationship between GPT and BERT? The two models use almost the same architecture. In fact, GPT and BERT-Base even use the same number of layers and dimensions. The only difference is that BERT is bidirectional as it attempts to fill in a single word based on context, while GPT uses masked self-attention heads.
Tuning GPT and BERT for Subword Language Models
GPT requires only minor modifications unless we want to explore different architectures. After all, it has already been trained as a language model. At a minimum, during fine-tuning, we can add a linear layer whose hidden size equals the vocabulary size. These weights are adjusted and fed into softmax, generating a probability distribution for the target word over the vocabulary. Masked self-attention ensures that only causal information flow occurs.
Recall BERT’s goals: masked language modeling and next sentence prediction. The masked language model uses bidirectional contextual information and randomly masks certain tokens during training. It attempts to infer the “identity” of the masked words based on this. Unfortunately, estimating 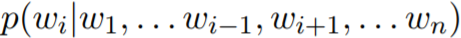 does not contribute to building an efficient text generator. We need to design a Gibbs sampler to sample
does not contribute to building an efficient text generator. We need to design a Gibbs sampler to sample 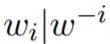 , i.e., given the context
, i.e., given the context 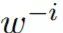 , iteratively and repeatedly sample w_i across all i to directly utilize this variant.
, iteratively and repeatedly sample w_i across all i to directly utilize this variant.
The next sentence prediction goal is to capture the binary relationship between two sentences. To reiterate, this cannot be directly used for language modeling. Therefore, we removed this goal and replaced it with a log-likelihood measure during fine-tuning. Similar to GPT, we add an output linear layer and replace self-attention heads with masked self-attention to prevent information from flowing left.
Note that the pre-trained weights of GPT and BERT will be reused during the fine-tuning of the language model to save the cost of full retraining. Thus, we are performing language modeling at the subword level, as both GPT and BERT use subword tokenization.
Fine-tuning Transformer Weights
GPT and BERT will adjust their respective model weights for the tasks mentioned earlier. For example, BERT does not use windowing by default. It is reasonable to adjust weights when fine-tuning for language modeling. However, updating all weights may lead to overfitting, as datasets like WikiText or Penn Tree Bank are an order of magnitude smaller than the data used to train GPT and BERT.
To address this issue, we propose to update only a portion of the layer weights during fine-tuning. Since both GPT and BERT have 12 Transformer modules, each containing a self-attention and a point-wise fully connected layer, it is challenging to simply select which parameters should be fixed. Thus, we turn to automatically search for the most effective subset of layers for the language modeling task. The search algorithm will be introduced later.
Adding an LSTM
The positional encoding achieved through Fourier bases in Transformers can only provide vague relative positional information, forcing layers to recreate trigonometry for specific words at each layer. This becomes problematic because language models require strong word-level contextual information to predict the next word. RNNs can explicitly model this sequential information. Therefore, we propose adding LSTM layers to the Transformer architecture.
Theoretically, we can add LSTM layers at any position, even interleaving them with Transformers. However, LSTMs significantly impact computational efficiency as they do not support parallel computation. Our reasoning is akin to the design philosophy of SRU (Simple Recurrent Unit (Lei et al., 2018)). Therefore, we propose to add an LSTM layer either before all base Transformer modules or after them. For the former, we directly add the LSTM layer after the embedding layer and remove positional and segment embeddings, as we believe the LSTM layer can encode sufficient sequential information. For the latter, we insert an LSTM layer between the last Transformer module and the output linear layer. We identify this as the best position for the LSTM through automatic search.
Coordinate Architecture Search
Now that we have the basic components, let’s review the network transformations proposed to obtain a well-performing architecture and the associated search process.
Network Transformations
We have proposed several ways to alter the network, which we refer to as: AddLinear, AddLSTM, FixSubset. Among them, AddLinear is to add a linear output layer, AddLSTM is to add an LSTM layer, and FixSubset is to fix a portion of the Transformer module weights.
Sampling Candidates for Search
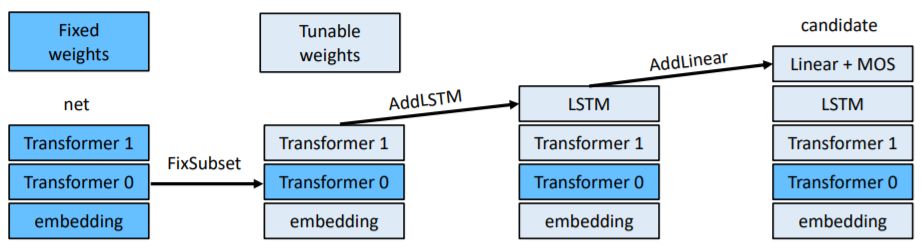
Figure 1: Sampling candidates for search. In the figure, net refers to the base architecture, and candidate is the architecture returned in the next step. Transformers, Embeddings, LSTM, and Linear are various transformations. The lighter-colored modules are variable, while the darker modules are fixed. See Algorithm 1.

Algorithm 1: Sampling candidates for search
Coordinate Architecture Search

Figure 2: Coordinate Architecture Search. net_best refers to the best architecture from the i-th step of the search. We sample search candidates and retain the one that performs best. Our metric is perplexity (Val PPL) on the target dataset after fine-tuning. See Algorithm 2.

Algorithm 2: Coordinate Architecture Search
Experiments
To demonstrate the effectiveness of the Transformer architecture found using coordinate search, we conducted experiments on the WikiText and Penn TreeBank datasets. We also provided comparisons with other existing neural search strategies. The results are shown in Table 1 and Figure 3.
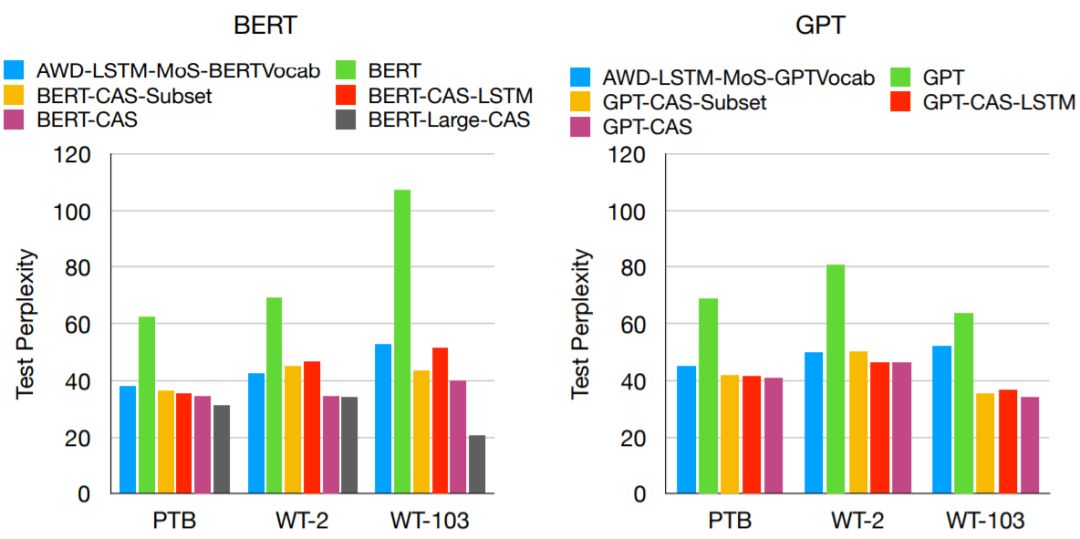
Table 1: Performance of Coordinate Architecture Search (CAS). Val and Test refer to validation and test perplexity, respectively.
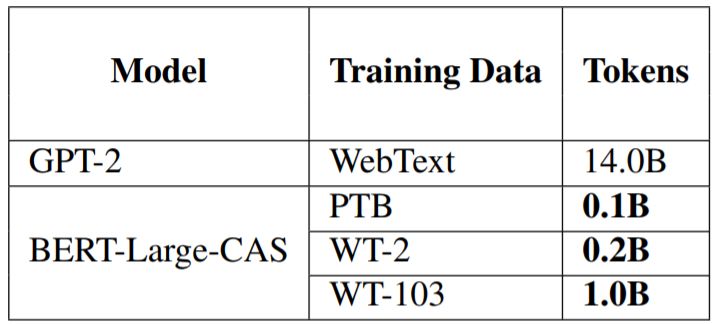
Figure 3: Comparison of CAS with other models in terms of test perplexity (the left figure shows results using the BERT pre-trained model; the right figure shows results using the GPT pre-trained model). “Subset” refers to variants without LSTM, while “LSTM” corresponds to models that do not update the Transformer modules.
Additionally, we also performed ablation experiments, which confirmed our intuition that we first need to preserve coarse-grained representations using fixed subsets of weights, and then use LSTMs to model word order dependencies.
Finally, we compared the newly proposed model with the current best language model GPT-2, with comparison metrics divided into three dimensions: results, parameter scale, and training data scale. The results are shown in Tables 6 and 7. It can be seen that in terms of parameters, our BERT-Large-CAS is more efficient than GPT-2 on PTB and WT-103, while its performance on WT-2 is worse than GPT-2, which we speculate may be due to the very small scale of WT-2. In terms of training data, BERT-Large-CAS can achieve comparable results with significantly less data.
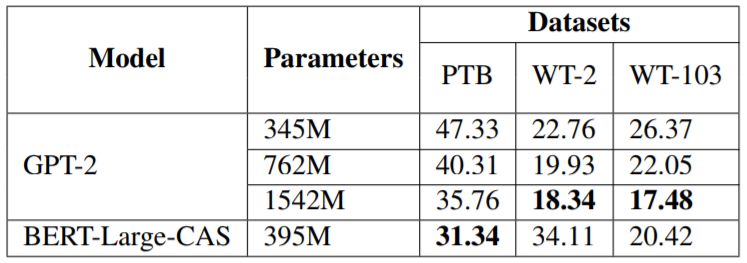
Table 6: Comparison of model parameter scale and results. The GPT-2 model size and results are from Radford et al., 2019
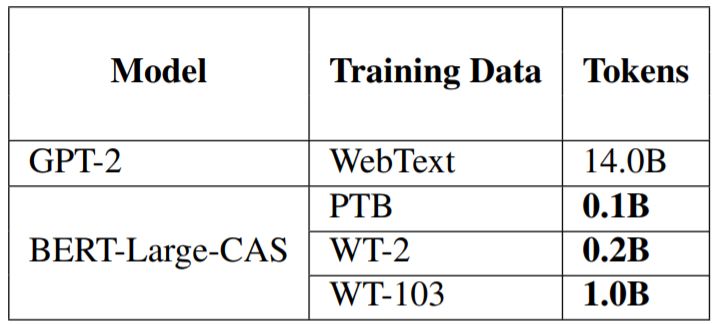
Table 7: Comparison of training dataset sizes with GPT-2 
This article is compiled by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time reporters/interns): [email protected]
Submissions or inquiries: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]