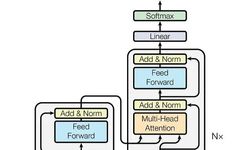
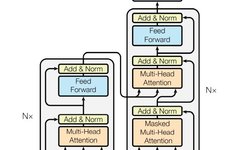
Efficient Additive Attention for Mobile Vision Applications

Click the above “Beginner’s Guide to Vision” and choose to add “Star” or “Pin“ Important insights delivered at the first moment Scan the QR code below to join the cutting-edge academic paper exchange group!Get the latest top conference/journal paper idea interpretations and PDF interpretations!And materials from beginner to advanced in CV, and the most cutting-edge … Read more