This article will cover three aspects of the essence of Transformer, the principles of Transformer, and the applications of Transformer, helping you understand Transformer (overall architecture & three types of attention layers) in one article.
1. Essence of Transformer
The origin of Transformer:The Google Brain translation team proposed a novel simple network architecture called Transformer, which is completely based on the attention mechanism, discarding recurrent and convolutional operations.

Attention mechanism is all you need
The mainstream sequence transformation model RNN:Before the emergence of Transformer, mainstream sequence transformation models were based on complex recurrent neural networks (RNN), consisting of an encoder and a decoder. The best-performing models at that time connected the encoder and decoder through the attention mechanism.
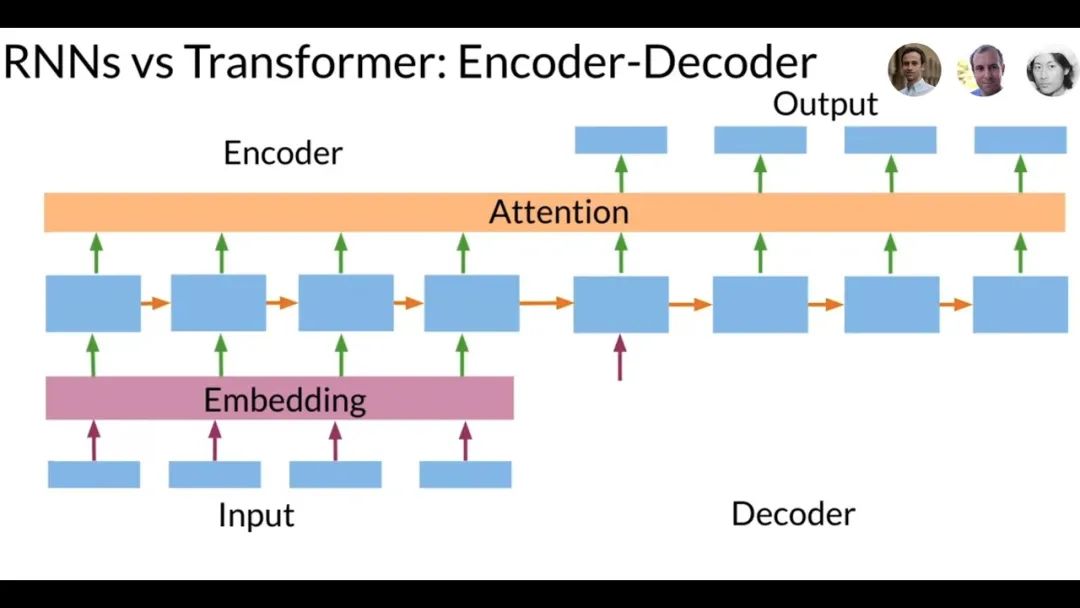
Transformer vs RNN
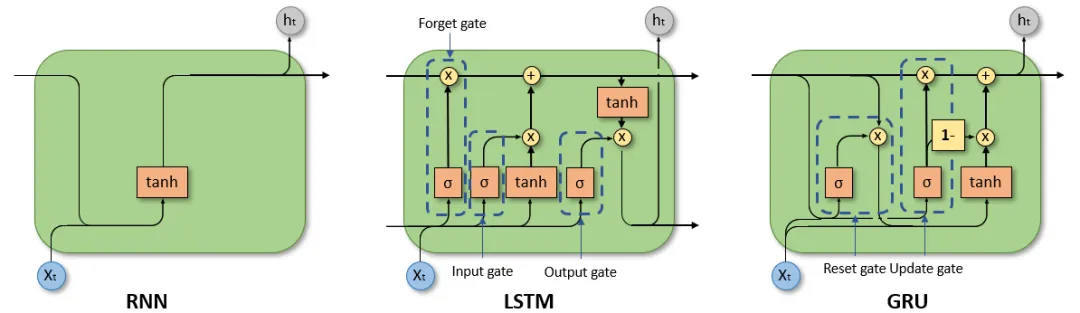
RNN LSTM GRU
<strong><span><strong><span><strong><span><strong><span>x1, x2, x3, x4</span></strong></span></strong></span></strong></span></strong> into a single vector <strong><span><strong><span><strong><span><strong><span>c</span></strong></span></strong></span></strong></span></strong>, which may result in information loss. This is because all information is compressed into this single vector, increasing the risk of information loss. It is also complex for the decoder to extract information from this vector.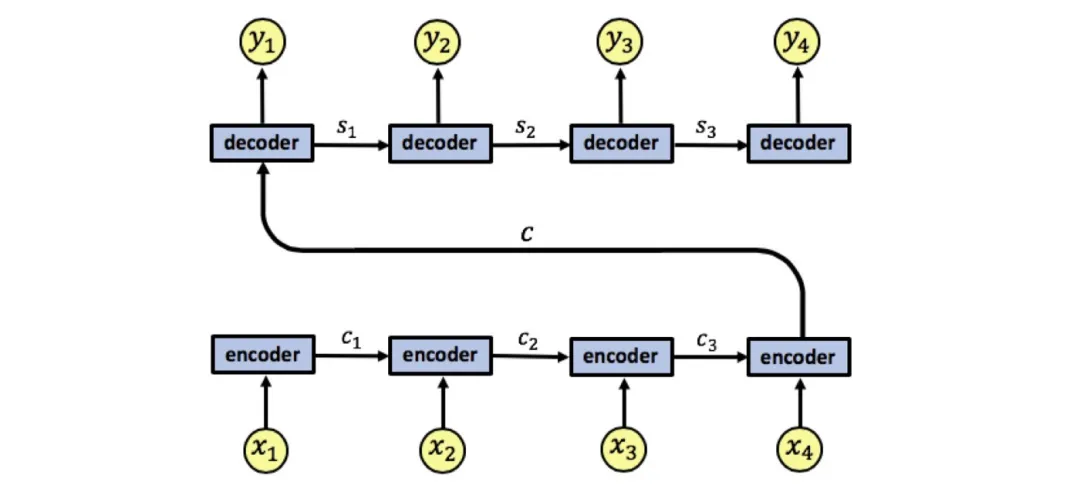
RNN encoder-decoder architecture
Attention mechanism:A mechanism that allows the model to focus on key parts while processing information, ignoring irrelevant information, thus improving processing efficiency and accuracy. It mimics the selective attention characteristics of human visual processing.


Q, K, V:The attention mechanism calculates attention scores (vector dot products and adjustments) by matching keys (K) with queries (Q), converting the scores into weights, and then weighting the value (V) matrix to obtain the final attention vector.
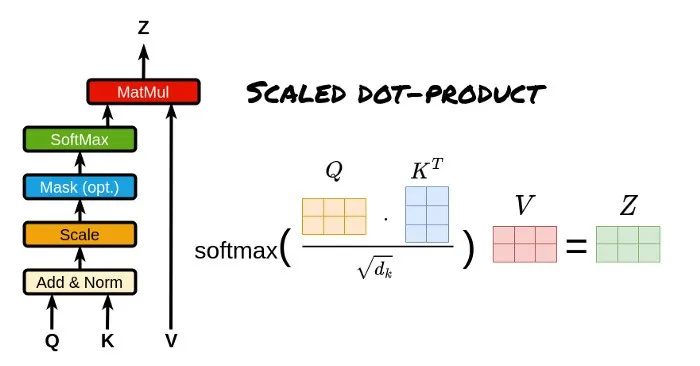
Calculating attention scores using Q, K, V

-
Advantage 1: Handling long sequence data.Transformer uses self-attention mechanisms to simultaneously process all positions in the sequence, capturing long-distance dependencies, thus understanding the meaning of the text more accurately. In contrast, RNN models are limited by their recurrent structure and find it difficult to handle long sequence data.
-
Advantage 2: Achieving parallel computation.Since RNN models need to process each element in the sequence sequentially, their computation speed is significantly limited. In contrast, Transformer models can process the entire sequence simultaneously, greatly improving computational efficiency.
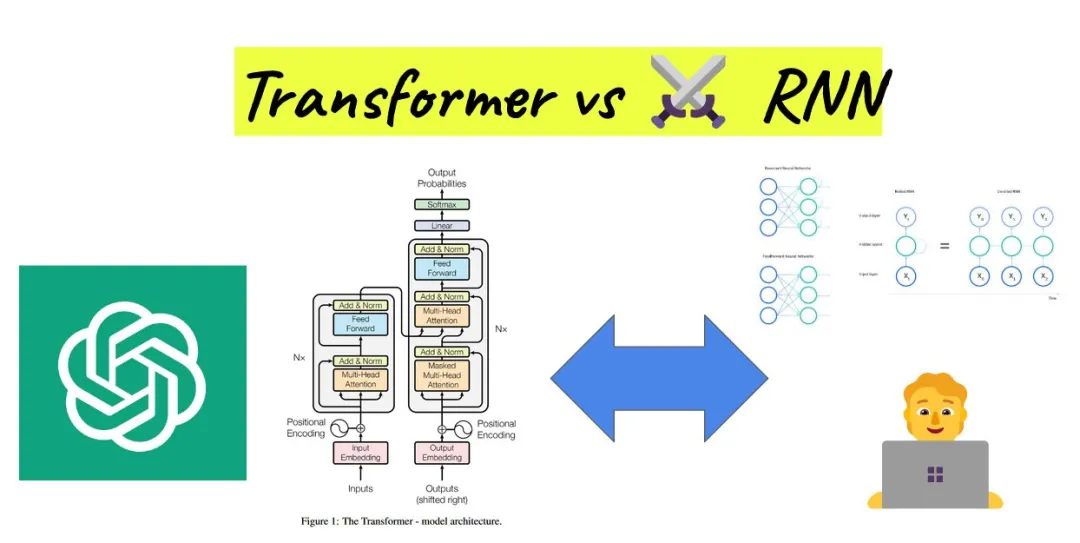
2. Principles of Transformer
The core idea of this architecture is to encode the input sequence into a fixed-size vector representation, and then use this vector to generate the output sequence.
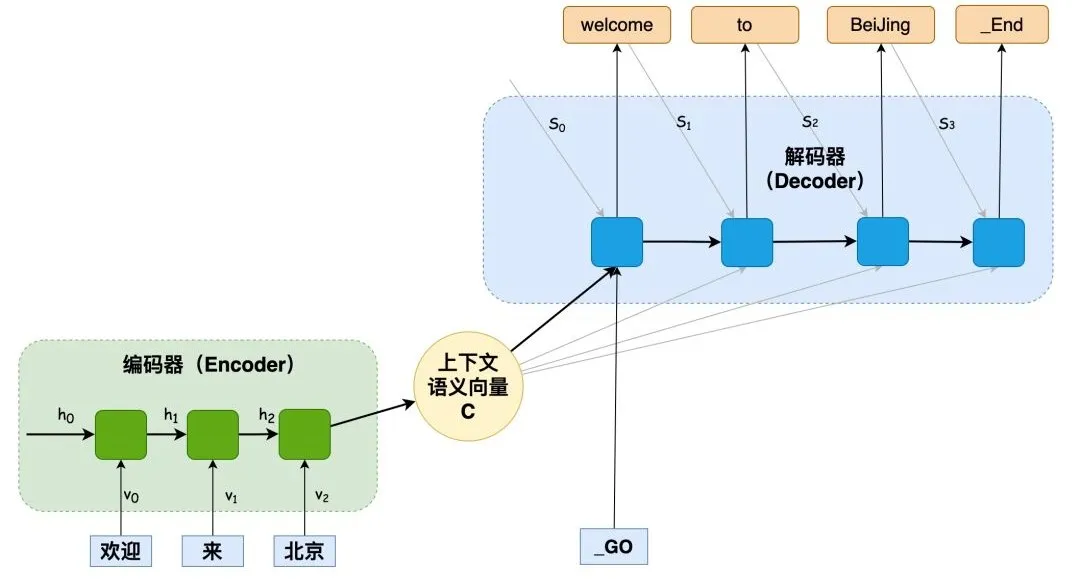
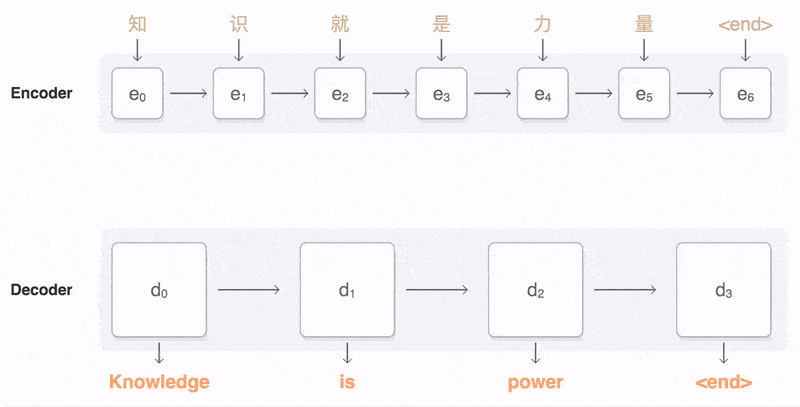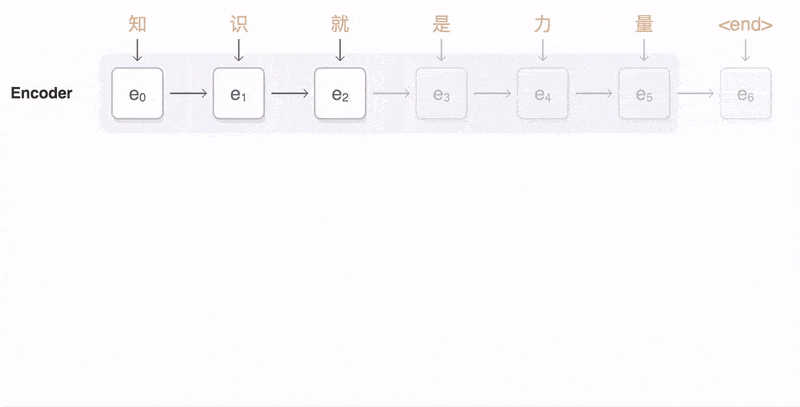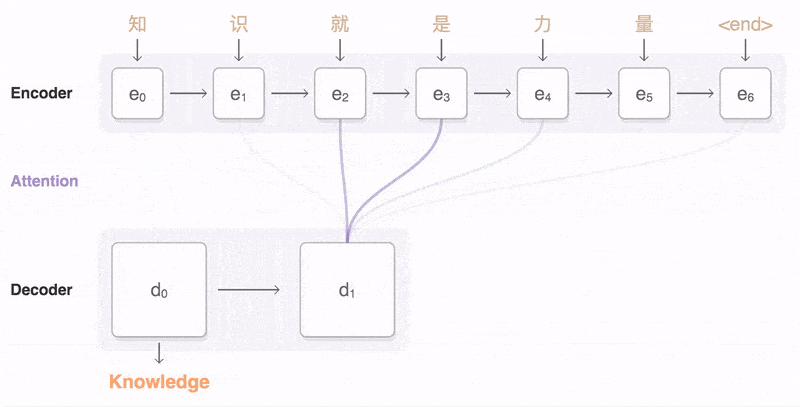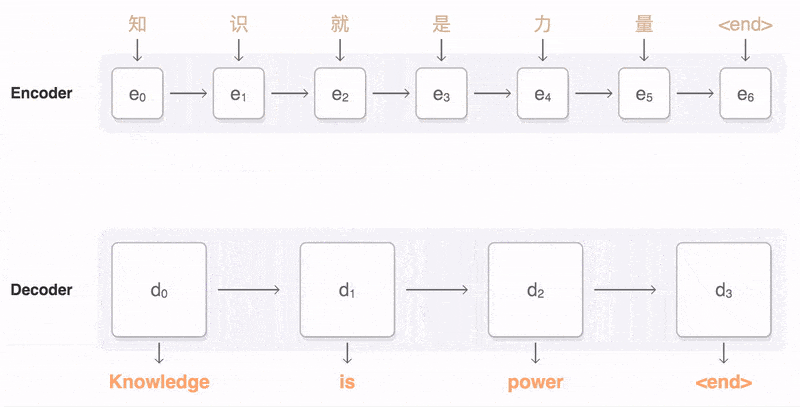
Machine translation
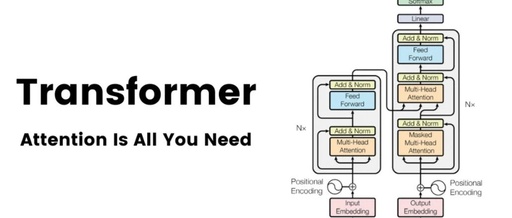
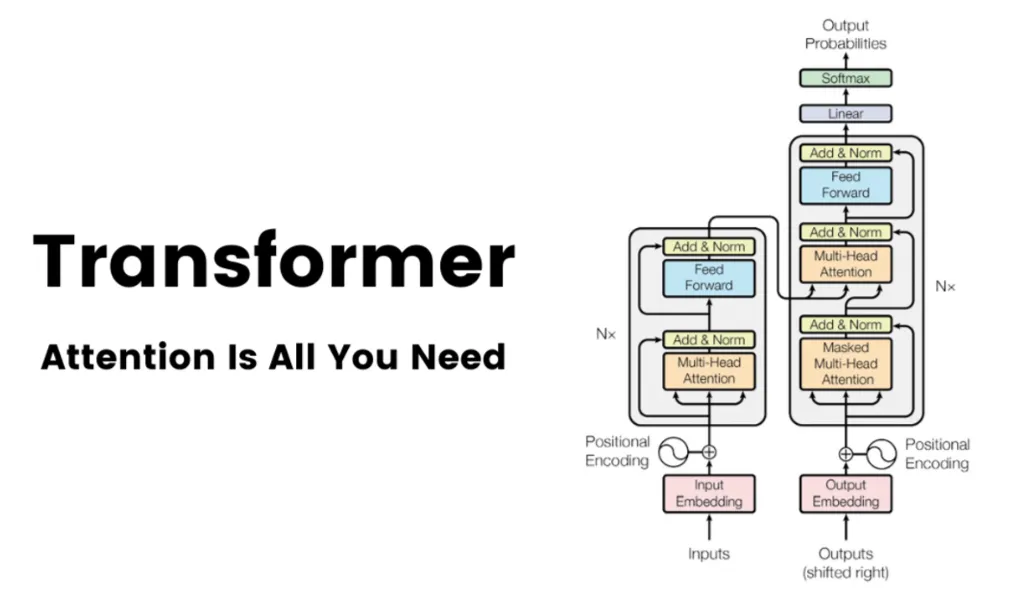
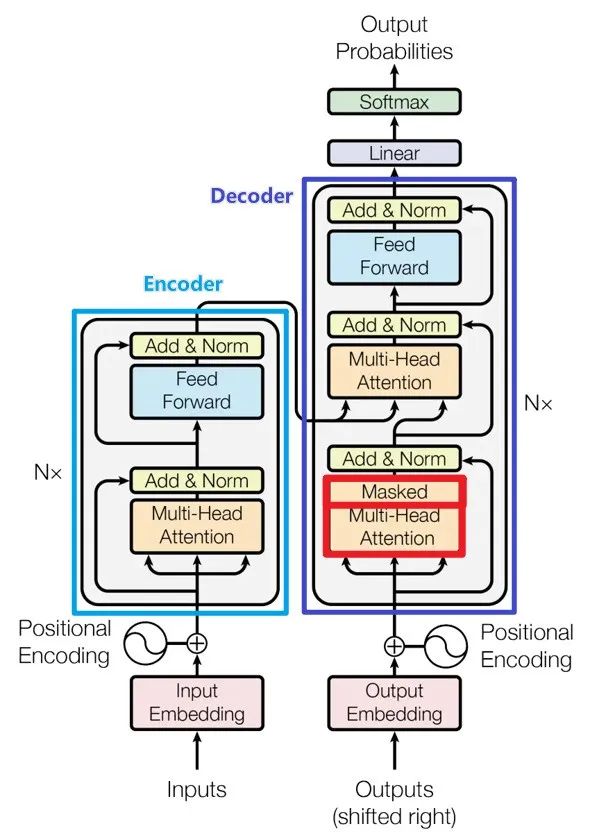
Architecture of Transformer:Transformer also follows the encoder-decoder overall architecture, using stacked self-attention mechanisms and position-wise fully connected layers, used for the encoder and decoder, as shown in the left and right parts of the diagram.
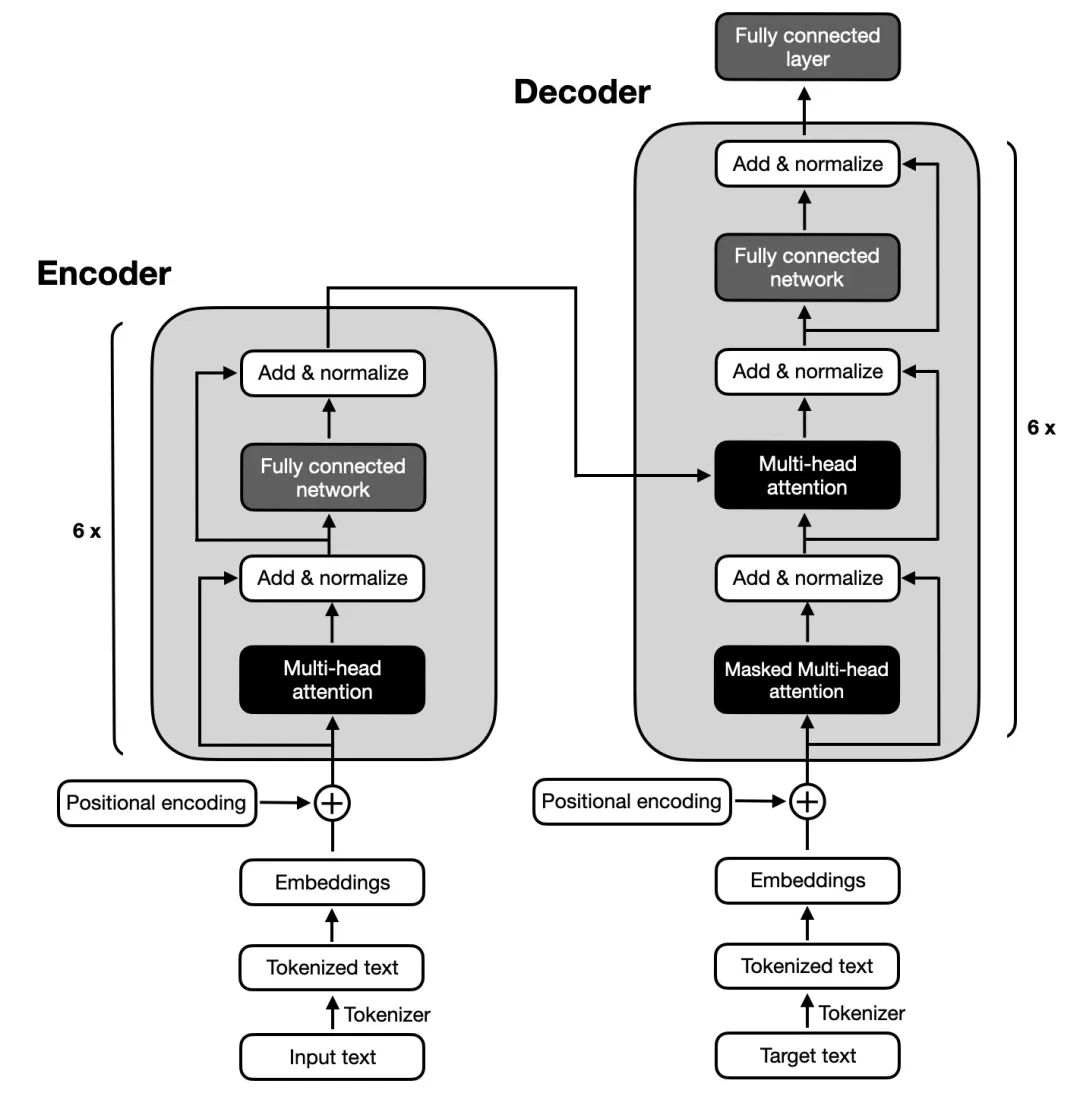
Architecture of Transformer
-
Encoder::The encoder of Transformer consists of 6 identical layers, each layer includes two sub-layers: a multi-head self-attention layer and a position-wise feedforward neural network. After each sub-layer, residual connections and layer normalization operations, collectively referred to as Add&Norm, are used. This structure helps the encoder capture dependencies at all positions in the input sequence.
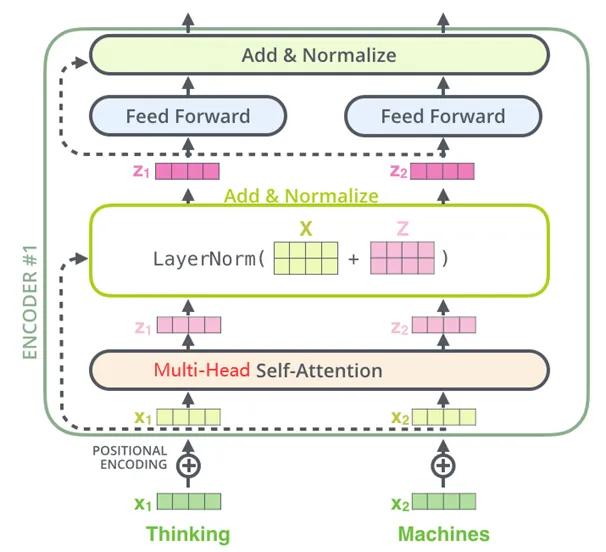
-
Decoder::The decoder of Transformer consists of 6 identical layers, each layer contains three sub-layers: a masked self-attention layer, an encoder-decoder attention layer, and a position-wise feedforward neural network. Each sub-layer has a residual connection and layer normalization operation after it, referred to as Add&Norm. This structure ensures that the decoder can consider previous outputs when generating sequences, avoiding the influence of future information.
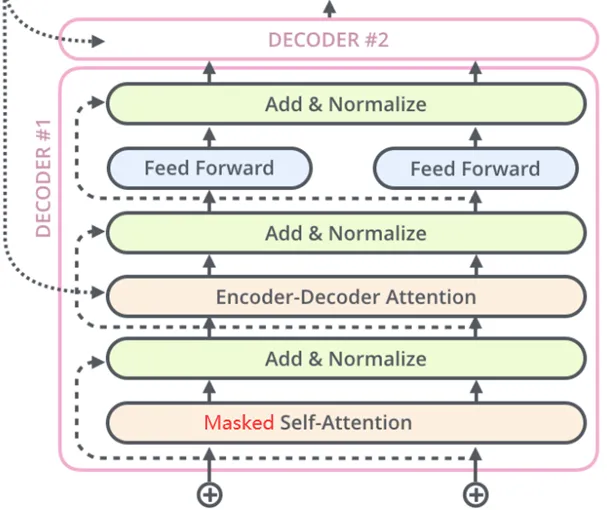
Essential differences between encoder and decoder
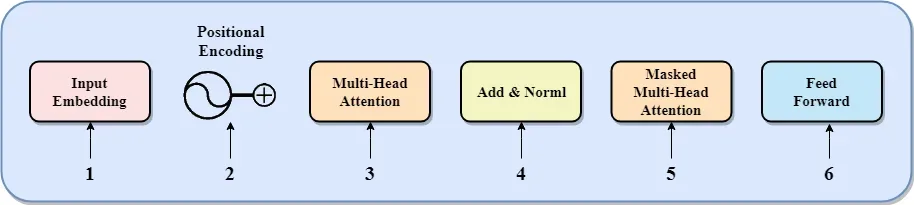
Core components of Transformer
-
Input embedding: Converts the input text into vectors for the model to process.
-
Position encoding: Adds positional information to the input vectors, as Transformer processes data in parallel without relying on order.
-
Multi-head attention: Allows the model to focus on different parts of the input sequence simultaneously, capturing complex dependencies.
-
Residual connections and layer normalization: Helps the model train better by adding cross-layer connections and normalizing outputs, preventing gradient issues.
-
Masked multi-head attention: Ensures that the model relies only on known information when generating text, not future content.
-
Feedforward network: Performs nonlinear transformations on the input to extract higher-level features.
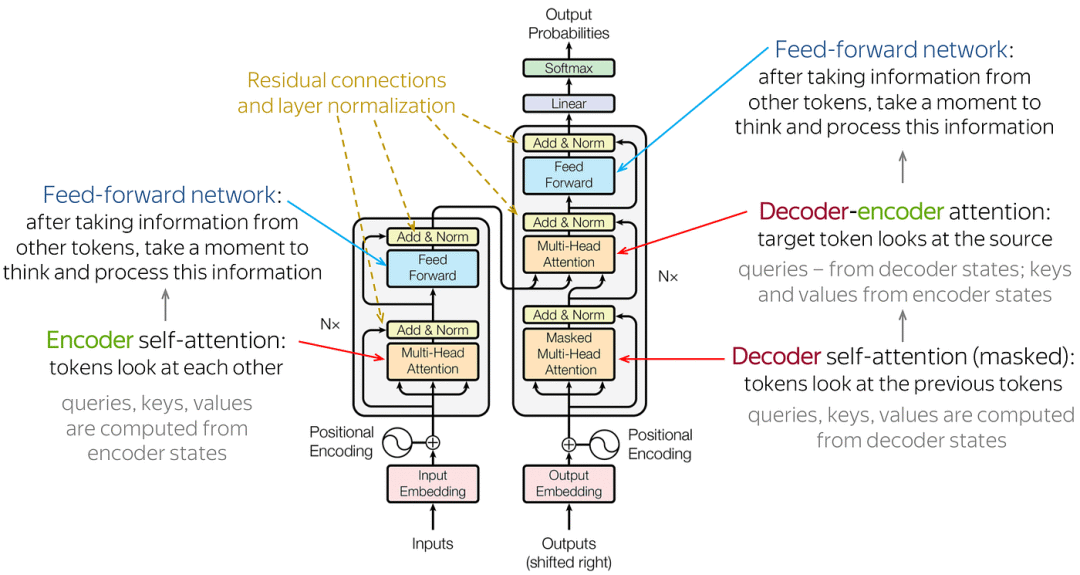
Core components of Transformer
Three types of attention layers in Transformer:In the Transformer architecture, there are three different attention layers (Self Attention, Cross Attention, Causal Attention).
-
Self Attention layer in the encoder:The input sequence of the encoder calculates attention weights through Multi-Head Self Attention.
-
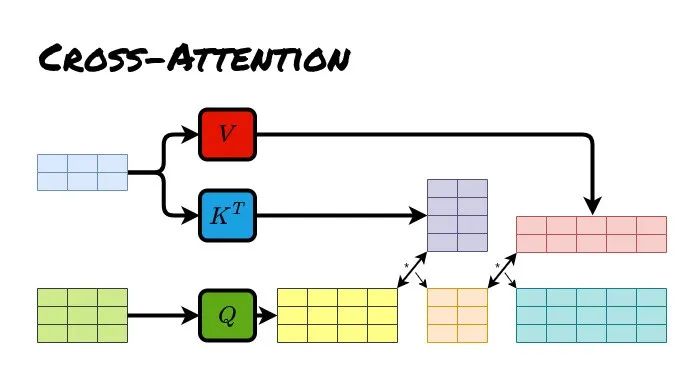
Cross Attention layer in the decoder:The encoder-decoder sequences transfer attention through Multi-Head Cross Attention.
-
Causal Attention layer in the decoder:The single sequence of the decoder calculates attention using Multi-Head Causal Self Attention
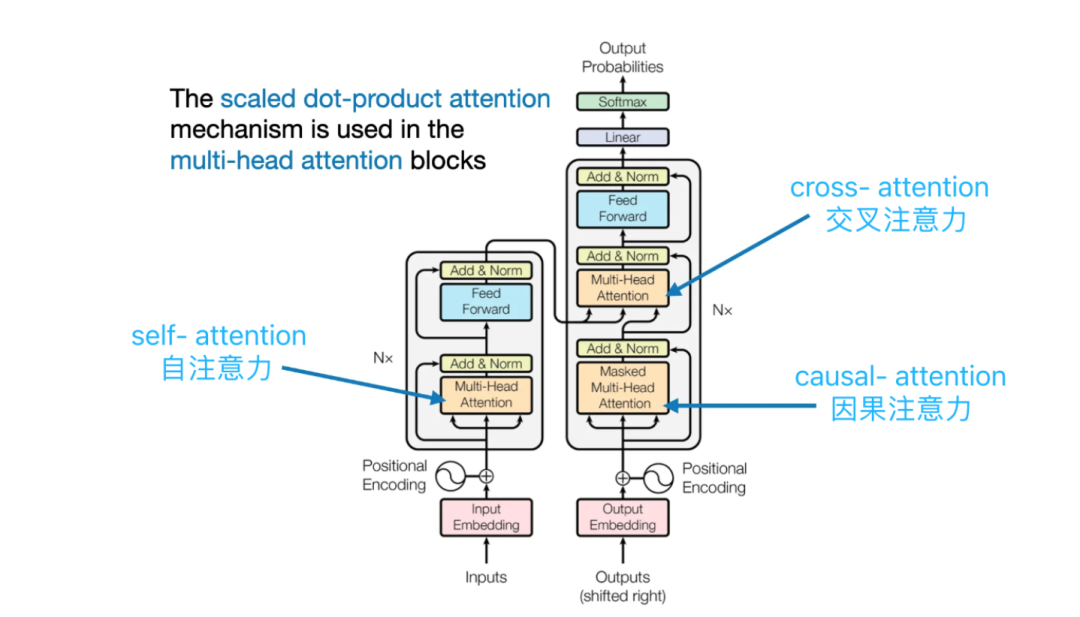
Three types of attention layers in Transformer
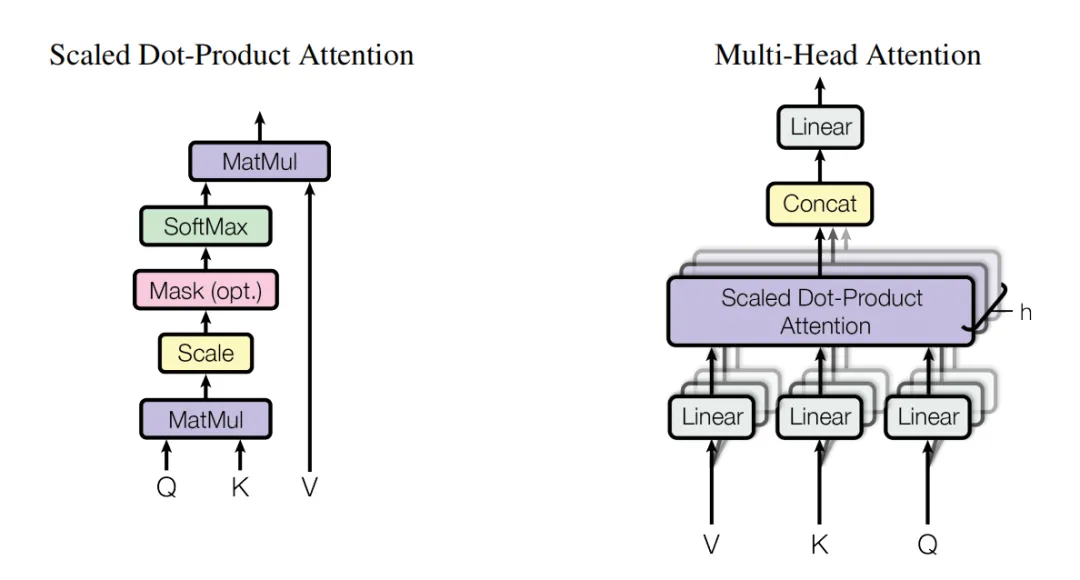
Scaled Dot-Product Attention and Multi-Head Attention
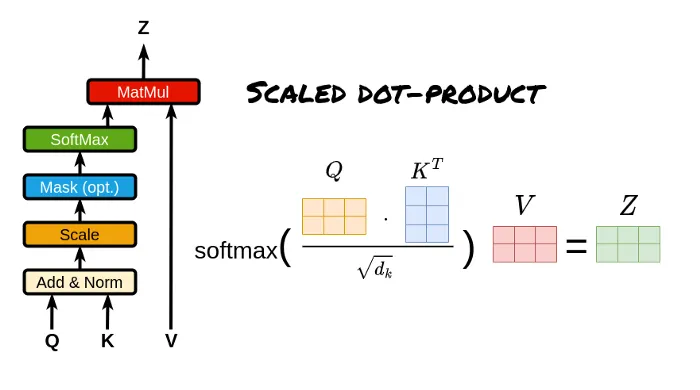
Self Attention:For the same sequence,attention scores are calculated using scaled dot-product attention,and the value vectors are weighted and summed to obtain the weighted representation of each position in the input sequence.
Expresses an attention mechanism, how to use scaled dot-product attention to calculate attention scores for the same sequence, thus obtaining the attention weights for each position in the same sequence.
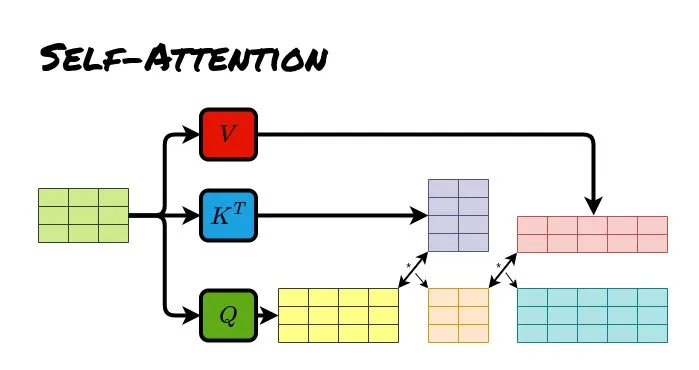
Self Attention (Self Attention)
Emphasizes a practical approach; in practice, we do not use a single dimension to perform a single attention function, but instead calculate using h=8 heads separately, then take a weighted averageto avoid errors from single calculations.
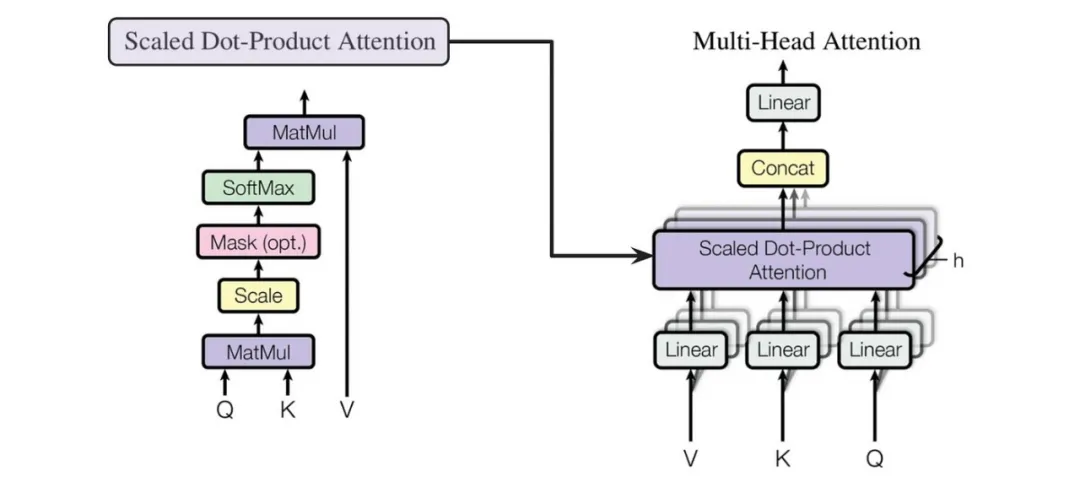
Multi-Head Attention (Multi-Head Attention)
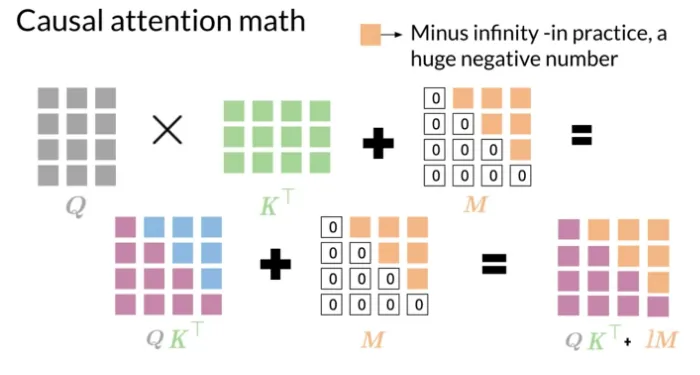
Causal Attention::To ensure that the model relies only on previous input information when generating sequences, and not on future information. Causal Attention achieves this by masking future positions, allowing the model to see only the current position and its previous inputs when predicting an output for a certain position.
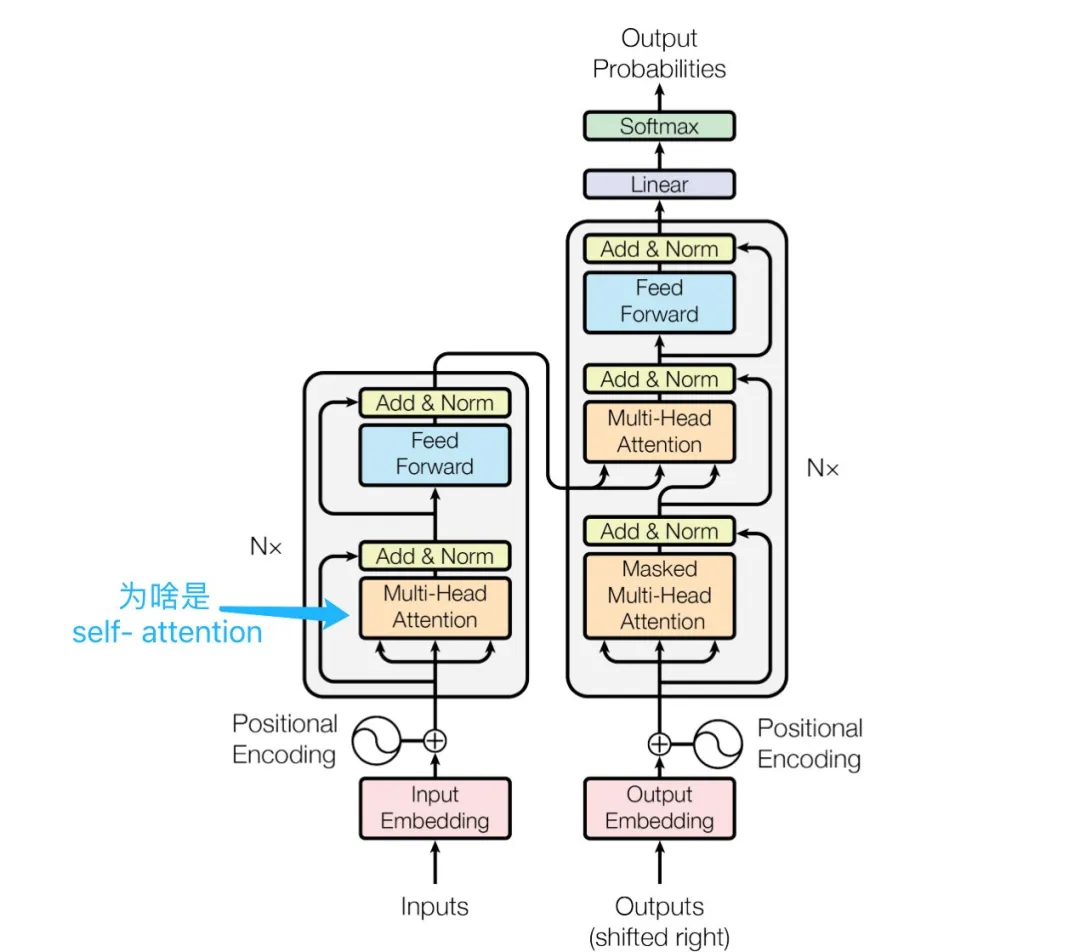
Question 2:In the diagram, the encoder also states Multi-Head Attention, how can it be called Cross Attention?
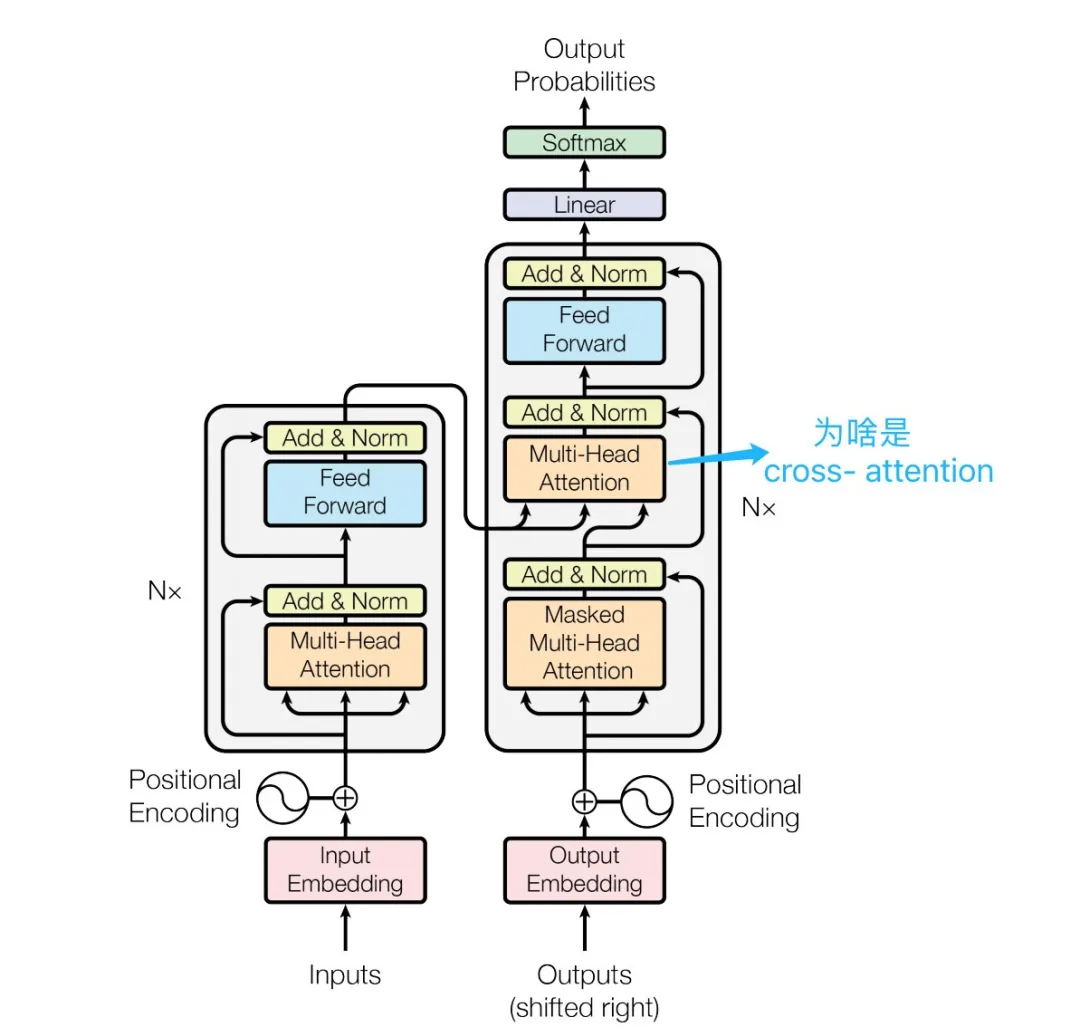
Cross Attention of encoder-decoder
Question 3:In the diagram, the encoder clearly states Masked Multi-Head Attention, how can it be called Causal Attention?
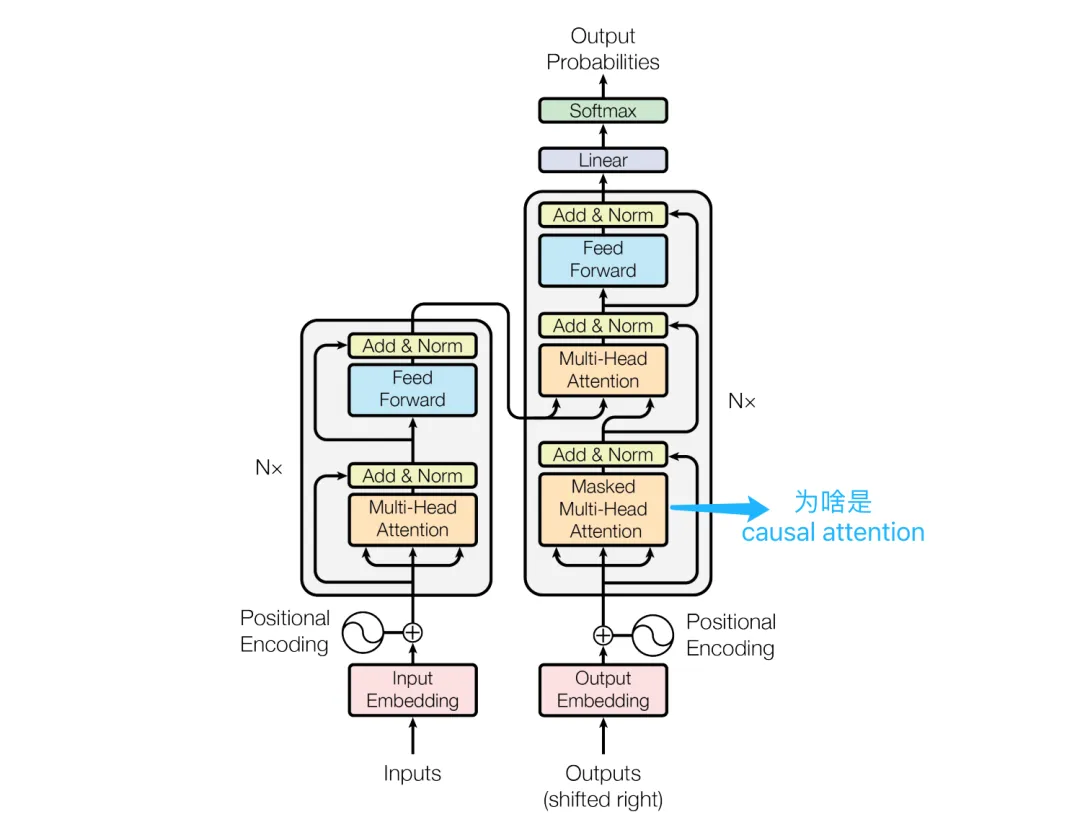
Decoder’s Causal Attention
Answer to Question 3Causal Attention and Masked Multi-Head Attention actually refer to the same thing, explaining how Self Attention in the decoder combines with Causal Attention to maintain autoregressive properties.
Masked Multi-Head Attention emphasizesthe use of multiple independent attention heads, each of which can learn different attention weights, thus enhancing the model’s representation ability. Causal Attention emphasizes that the model can only rely on already generated information when making predictions and cannot see future information.
Learn more about the three attention mechanisms in Transformer:
3. Applications of Transformer
Applications of Transformer in NLP:Due to the powerful performance of Transformer, Transformer models and their variants have been widely used in various natural language processing tasks such as machine translation, text summarization, question answering systems, etc.
-
Transformer:Vaswani et al. first proposed a Transformer based on attention mechanisms for machine translation and English syntactic structure parsing tasks.
-
BERT:Devlin et al. introduced a new language representation model BERT, which considers the context of each word. Since it is bidirectional, it pre-trained a Transformer on unlabeled text. When BERT was released, it achieved state-of-the-art performance on 11 NLP tasks.
-
GPT:Brown et al. pre-trained a large model based on Transformer called GPT-3 with 175 billion parameters on a dataset containing 45TB of compressed plain text data. It achieved powerful performance on various types of downstream natural language tasks without any fine-tuning.
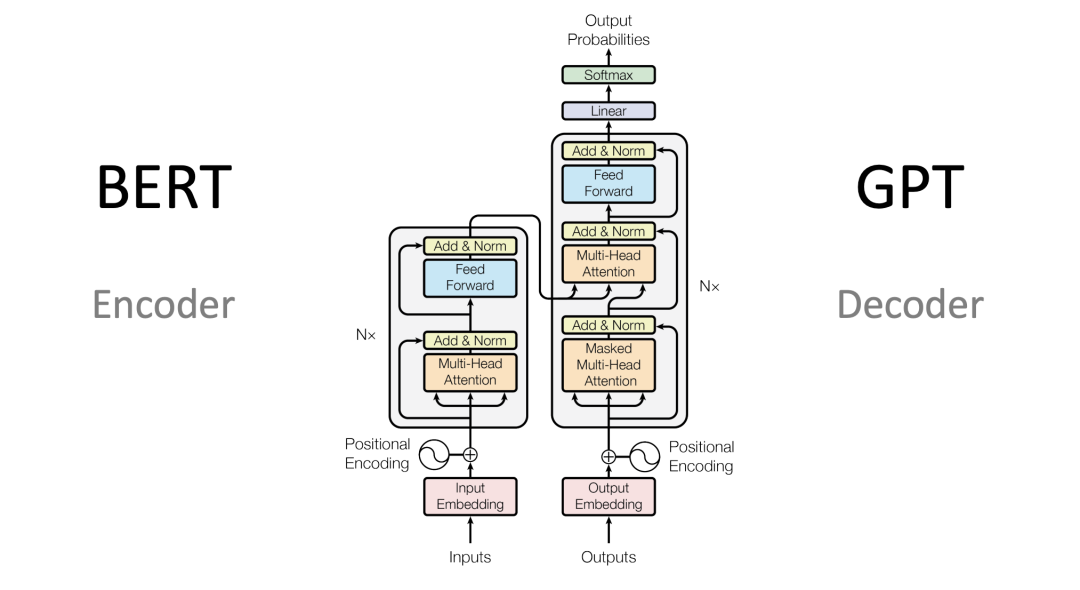
-
ViT uses the self-attention mechanism from the Transformer model to model the features of images, which differs from CNNs that extract local features of images through convolutional and pooling layers.
-
ViT’s main body block structure is based on the Transformer Encoder structure, including the Multi-head Attention structure.
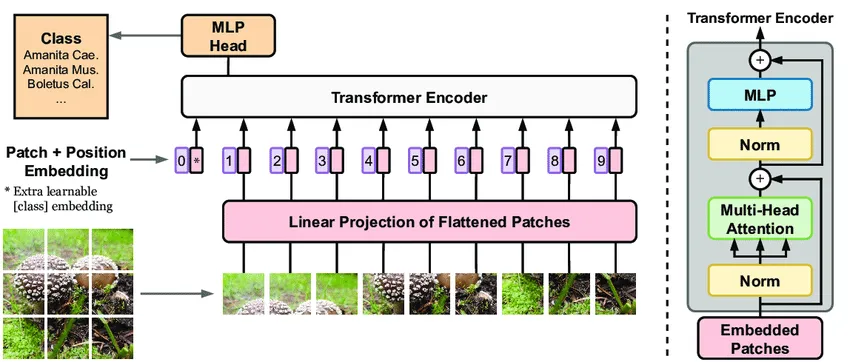
Vision Transformer
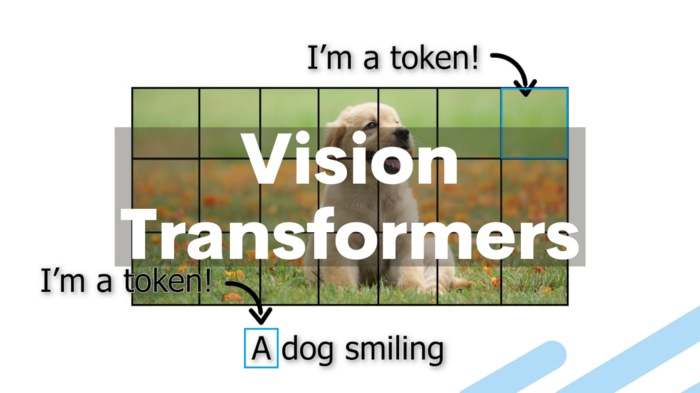
Workflow of ViT:Splits images into fixed-size patches, converts them into Patch Embeddings, adds positional encoding information, processes these embeddings through a Transformer encoder containing multi-head self-attention and feedforward neural networks, and finally uses classification tokens for tasks such as image classification.

Learn more about ViT (Vision Transformer):