Big Data Digest and Baidu NLP Jointly Produced
Big Data Digest and Baidu NLP Jointly Produced
Author: Damien Sileo
Translators: Zhang Chi, Yi Hang, Long Xin Chen
BERT is a natural language processing model recently proposed by Google, which performs exceptionally well in many tasks such as question answering, natural language inference, and paraphrasing, and it is open-source. Therefore, it is very popular in the community.
The following figure shows the changes in GLUE benchmark scores (average scores across different NLP evaluation tasks) for different models.
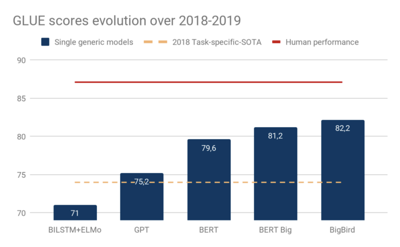
Although it is still unclear whether all GLUE tasks are meaningful, general models based on the Transformer encoder (Open-GPT, BERT, BigBird) have narrowed the gap between task-specific models and humans within a year.
However, as Yoav Goldberg mentioned, we do not fully understand how Transformer models encode sentences:
Transformers differ from RNN models in that they rely solely on attention mechanisms. In addition to the absolute position embeddings of each word, there are no explicit word order markers. This reliance on attention may lead Transformer models to perform poorly on syntax-sensitive tasks compared to RNN (LSTM) models — because RNN models are trained directly based on word order and explicitly track the state of sentences.
Some articles have delved deeply into the technical details of BERT. Here, we will try to propose some new perspectives and hypotheses to explain BERT’s powerful capabilities.
A Framework for Language Understanding: Syntactic Parsing/Semantic Composition
The way humans understand language has long been a philosophical question. In the 20th century, two complementary principles elucidated this issue:
The “principle of semantic compositionality” states that the meaning of compound words comes from the meanings of individual words and how these words are combined. According to this principle, the meaning of the noun phrase “carnivorous plants” can be derived from the meanings of the words “carnivorous” and “plant”.
Another principle is the “hierarchical structure of language”. It indicates that sentences can be decomposed into simpler structures — such as clauses — through syntactic parsing. Clauses can further be broken down into verb phrases and noun phrases, etc.
The hierarchical structure of syntactic parsing and recursion is an attractive method for extracting meaning from constituents until reaching the sentence level. Considering the sentence “Bart watched a squirrel with binoculars”, a good syntactic parsing would return the following syntactic parse tree:
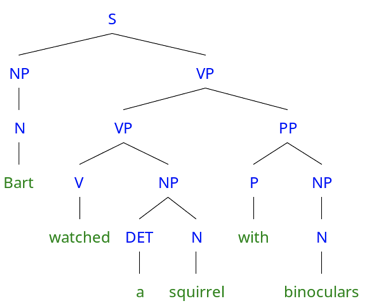
The syntactic parse tree based on the structure for “Bart watched a squirrel with binoculars”
The meaning of this sentence can be derived through successive semantic compositions (composing the semantics of “a” and “squirrel”, then “watched” and “a squirrel”, then “watched a squirrel” and “with binoculars”), until the meaning of the sentence is fully obtained.
A vector space can be used to represent a word, phrase, and other constituents. The process of semantic composition can be constructed as a function f, where f combines the semantics of (“a”,”squirrel”) into a meaningful vector representing “a squirrel” = f(“a”,”squirrel”).
Related Links:
http://csli-lilt.stanford.edu/ojs/index.php/LiLT/article/view/6
However, both semantic composition and syntactic parsing are challenging tasks, and they require each other.
Clearly, semantic composition relies on the results of syntactic parsing to determine what should be semantically composed. But even with the correct input, semantic composition is a difficult problem. For instance, the meaning of adjectives can vary with different words: the color of “white wine” is actually yellow, but a white cat is indeed white. This phenomenon is known as co-composition.
Related Links:
http://gl-tutorials.org/wp-content/uploads/2017/07/Pustejovsky-Cocompositionality-2012.pdf
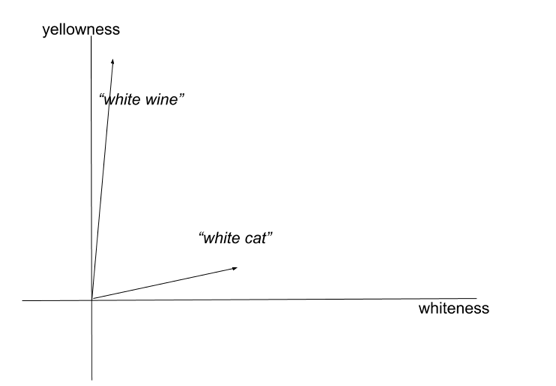
The representations of “white wine” and “white cat” in a two-dimensional semantic space (the dimension of the space is color)
For semantic composition, a broader context is also needed. For example, the semantics of the word “green light” depends on the context. “Green light” can mean authorization or an actual green light. Some idioms require experiential memory rather than simple combination. Therefore, performing semantic composition in vector space requires powerful nonlinear functions, such as deep neural networks, which also have memory capabilities.
Related Links:
https://arxiv.org/abs/1706.05394
Conversely, for some specific situations to work, syntactic parsing operations may require semantic composition. Consider the syntactic parse tree of the same sentence “Bart watched a squirrel with binoculars”.
Another structure-based syntactic parse tree of “Bart watched a squirrel with binoculars”
Although it is grammatically valid, the syntactic parsing operation leads to a distorted translation of the sentence, “Bart watches (with his bare eyes) a squirrel holding binoculars”.
Thus, some semantic composition of words is needed to determine that “the squirrel holding binoculars” is impossible! Generally, before obtaining the correct structure of the sentence, some disambiguation operations and integration of background knowledge are necessary. But this operation can also be accomplished through some forms of syntactic parsing and semantic composition.
Some models attempt to apply syntactic parsing and semantic composition operations simultaneously in practice.
Related Links:
https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf
However, they rely on restricted manually annotated standard syntactic parse tree setups, and their performance has not been better than some simpler models.
How BERT Achieves Syntactic Parsing/Semantic Composition Operations
We hypothesize that the Transformer innovatively relies on these two operations (syntactic parsing/semantic composition): since semantic composition requires syntactic parsing, and syntactic parsing requires semantic composition, the Transformer iteratively employs steps of syntactic parsing and semantic composition to resolve their interdependence.
In fact, the Transformer consists of several stacked layers (also called blocks). Each block consists of an attention layer and a nonlinear function applied to each input element.
We attempt to demonstrate the connection between these components of the Transformer and the framework of syntactic parsing/semantic composition:

A view of continuous syntactic parsing and semantic composition steps
Considering Attention as a Syntactic Parsing Step
In BERT, an attention mechanism allows each element in the input sequence (e.g., elements composed of words or subwords) to focus on other elements.
For explanatory purposes, we delve into the attention heads using the visualization tools employed in this article (https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73) and validate our hypotheses on the pre-trained BERT model. In the explanation of the attention head below, the word “it” engages with all other elements, appearing to pay attention to the words “street” and “animal”.

Visualizing attention values on attention head 1 of layer 0, focusing on “it”
BERT uses 12 independent attention mechanisms for each layer. Thus, in each layer, each token can focus on 12 different aspects of other tokens. Since Transformers use many different attention heads (12 * 12 = 144 for the base BERT model), each head can focus on different types of constituent combinations.
We have ignored the attention values associated with the “[CLS]” and “[SEP]” tokens. We tried several sentences and found it difficult not to over-interpret their results. So feel free to test our hypotheses with a few sentences in this colab notebook. Please note that in the diagram, the left sequence “attends” to the right sequence.
Related Links:
https://colab.research.google.com/drive/1Nlhh2vwlQdKleNMqpmLDBsAwrv_7NnrB
Attention values in head 1 of layer 2 seem to generate components based on relevance.

Visualizing attention values on head 1 of layer 2
Interestingly, in layer 3, head 9 seems to show higher-level constituents: some tokens attend to the same center words (if, keep, have).

Visualizing attention values in head 11 of layer 3, where some tokens appear to attend to specific center words (e.g., have, keep)
In layer 5, the matching performed by head 6 seems to focus on specific combinations, especially those involving verbs. Special tokens like [SEP] appear to indicate no match. This allows the attention heads to detect specific structures suitable for that semantic composition. Such consistent structures can be used for semantic composition functions.

Visualizing attention values in head 6 of layer 5, focusing more on combinations (we, have), (if, we), (keep, up), (get, angry)
A series of attention layers can represent parse trees as shown below:
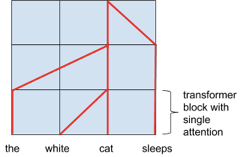
How several attention layers represent as tree structures
When examining BERT’s attention heads, we did not find such clear tree structures. However, Transformers may still represent them.
We noted that because encoding is performed simultaneously across all layers, it is challenging to accurately interpret what BERT is doing. Analysis of a specified layer only makes sense concerning its next and previous layers. Syntactic parsing is also distributed across attention heads.
The following diagram shows how BERT’s attention looks more practical in the case of two attention heads:
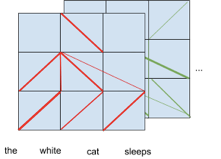
A More Practical Display of Attention Values in BERT
However, as we have seen before, syntactic parse trees are a high-level representation that may be based on more complex “root-stem” structures. For instance, we may need to identify what a pronoun refers to in order to encode the input (coreference resolution). In other cases, disambiguation may also require the full context.
Surprisingly, we found that one attention head (head 0 of layer 6) seems to actually perform coreference resolution.
Related Links:
https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73
Some attention heads seem to provide full context information for every word (head 0 of layer 0).
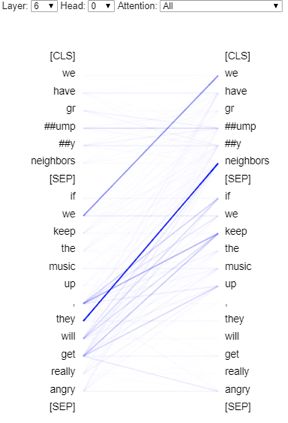
Coreference resolution occurring in head 0 of layer 6

Each word attends to all other words in the sentence. This may allow for a rough context to be established for each word.
Semantic Composition Phase
In each layer, the outputs of all attention heads are concatenated and fed into a neural network capable of representing complex nonlinear functions (necessary for semantic composition).
Relying on the structured input from attention heads, this neural network can perform various semantic compositions. In the previously shown layer 5, head 6 can guide the model to perform the following semantic compositions: (we, have), (if, we), (keep, up), (get, angry). The model can nonlinearly combine them and return a representation of semantic composition. Thus, multiple attention heads can serve as tools for auxiliary semantic composition.
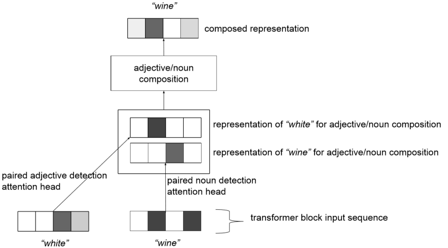
How attention heads assist in specific semantic composition, such as adjective/noun semantic composition
Although we did not find attention heads consistently focusing on combinations like adjective/noun, there may be some commonalities between verb/adverb semantic compositions and other semantic compositions derived by the model.
There are many possible relevant semantic compositions (word-subword, adjective-noun, verb-preposition, clause-clause). Furthermore, we can view disambiguation as the process of semantically composing an ambiguous word (e.g., bank) with its contextually related words (e.g., river or cashier). During semantic composition, background common sense knowledge related to the given context can also be integrated. This disambiguation may also occur at other levels (e.g., sentence level, clause level).

As a disambiguation of semantic composition
Additionally, semantic composition may also involve reasoning about word order. It has been suggested that position encodings may be insufficient to correctly encode the order of words; however, position encodings are designed to encode each token’s rough, fine, and possibly precise positions. (Position encodings are vectors averaged with input embeddings to generate representations that are position-aware for each token in the input sequence). Therefore, based on two position encodings, nonlinear compositions can theoretically perform some relational reasoning based on the relative positions of words.
We hypothesize that the semantic composition phase also plays an important role in BERT’s natural language understanding: it does not rely solely on attention.
Conclusion
We have proposed insights into the inductive biases of Transformers. But our interpretation holds an optimistic view of the functionality of Transformers. As a reminder, LSTMs have shown the ability to implicitly handle tree structures and semantic compositions. Since LSTMs still have some limitations, partly due to vanishing gradients, further research is needed to clarify the limitations of Transformers.
Citations:
Bowman, S., Manning, C. and Potts, C. (2015). Tree-structured composition in neural networks without tree-structured architectures.
Hochreiter, S. (1998). The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 06(02), pp.107-116.
Tai, K., Socher, R. and Manning, C. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks.
Related Reports:
https://medium.com/synapse-dev/understanding-bert-transformer-attention-isnt-all-you-need-5839ebd396db
Intern/Full-time Editor Recruitment
Join us and experience every detail of writing for a professional tech media. Grow with a group of the best people around the world in the most promising industry. Located at Tsinghua East Gate, Beijing, reply on the Big Data Digest homepage dialogue page with “Recruitment” to learn more. Please send your resume directly to [email protected]
Volunteer Introduction
Reply with “Volunteer” to join us