
©PaperWeekly Original · Author|Su Jianlin
School|Zhuiyi Technology
Research Direction|NLP, Neural Networks



Model Compression
In simple terms, model compression is about “simplifying a large model to obtain a smaller model with faster inference speed.” Of course, generally speaking, model compression comes with certain sacrifices, such as the most obvious drop in final evaluation metrics. After all, free lunches that are “better and faster” are rare, so the premise for choosing model compression is to allow for a certain degree of accuracy loss.
Additionally, the speedup from model compression usually only manifests during the prediction phase; in other words, it often requires longer training times. So, if your bottleneck is training time, then model compression may not be suitable for you.
The reason model compression takes longer is that it requires “first training a large model and then compressing it to a small model.” Readers may wonder: why not directly train a small model? The answer is that many experiments have shown that training a large model first and then compressing it usually yields better final accuracy than directly training a small model.
1.2 Common Techniques
Common model compression techniques can be divided into two main categories: 1) directly simplifying a large model to obtain a small model; 2) retraining a small model using a large model. Both methods require first training a reasonably effective large model, followed by subsequent operations.
The representative methods of the first category are pruning and quantization.
Pruning, as the name suggests, attempts to remove some components of the original large model to transform it into a smaller model while keeping the model’s performance within an acceptable range;
As for quantization, it refers to changing the numerical format of the model without altering its structure, while not significantly degrading performance. Typically, models are built and trained using float32, but switching to float16 can speed up inference and reduce memory usage. If further converted to 8-bit integers or even 2-bit integers (binary), the speedup and memory savings will be even more pronounced.
The representative method of the second category is distillation. The basic idea of distillation is to use the output of the large model as labels for training the small model. For classification problems, the actual labels are in one-hot format, while the output of the large model (e.g., logits) contains richer signals, allowing the small model to learn better features.

Theseus
The compression method to be introduced in this article is called “BERT-of-Theseus,” which belongs to the second category mentioned above. In other words, it also retrains a small model using a large model, but it is designed based on the replaceability of modules.
2.1 Core Idea
Let’s give a practical analogy:
Suppose we have two teams, A and B, each with five members. Team A is a star team with exceptional strength; Team B is a rookie team that needs training. To train Team B, we select one member from Team B to replace one member from Team A, and then let this “4+1” team A continuously practice and compete. After some time, the newly added member will improve, and this “4+1” team will possess strength close to the original Team A.
Returning to the compression of BERT, let’s assume we have a 6-layer BERT model. We directly fine-tune it on downstream tasks, achieving a reasonably good model, which we call Predecessor.
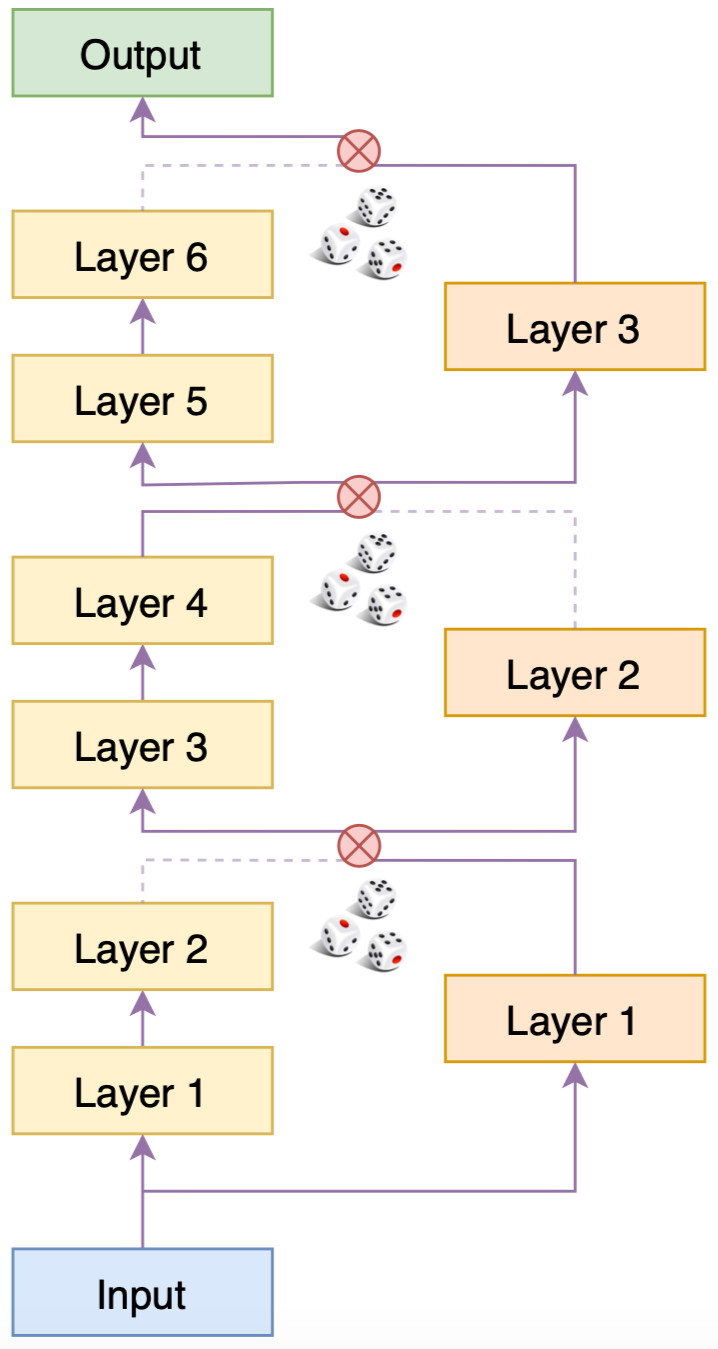
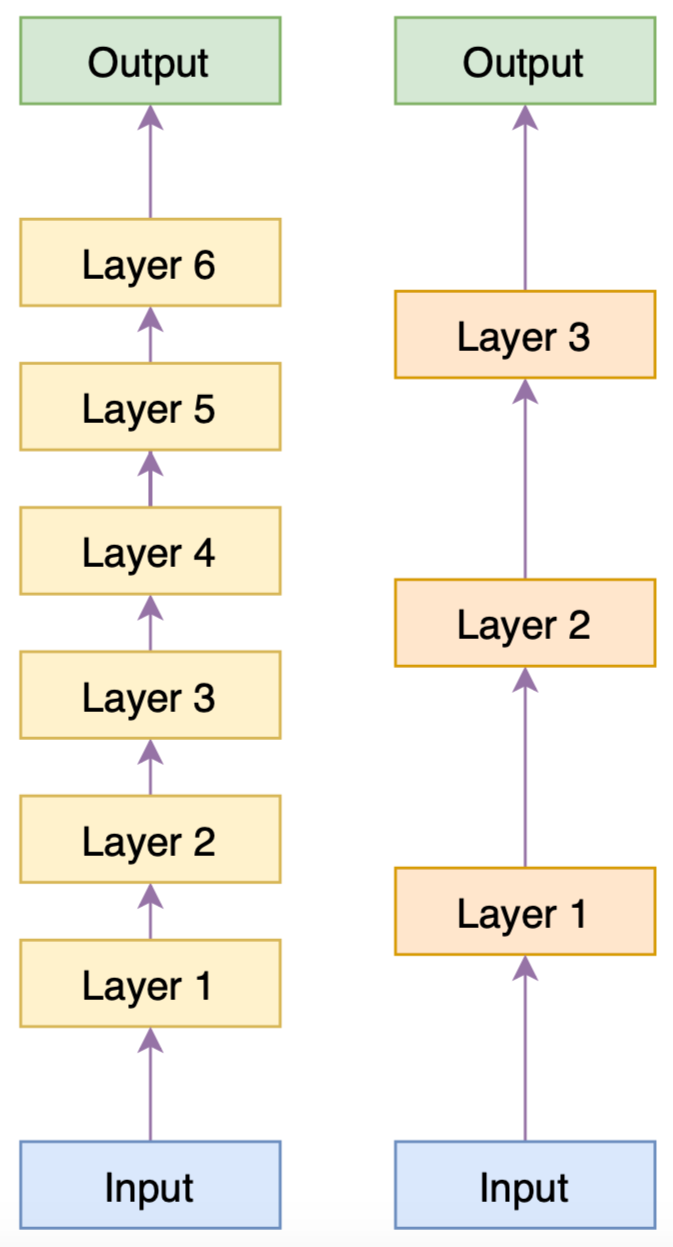
In the entire process of BERT-of-Theseus, the weights of the Predecessor are fixed. The 6-layer Predecessor is divided into 3 modules, corresponding one-to-one with the 3-layer Successor model. During training, the corresponding modules of the Predecessor are randomly replaced with those of the Successor, and then fine-tuned directly using the optimization objective of the downstream task (only training the layers of the Successor).

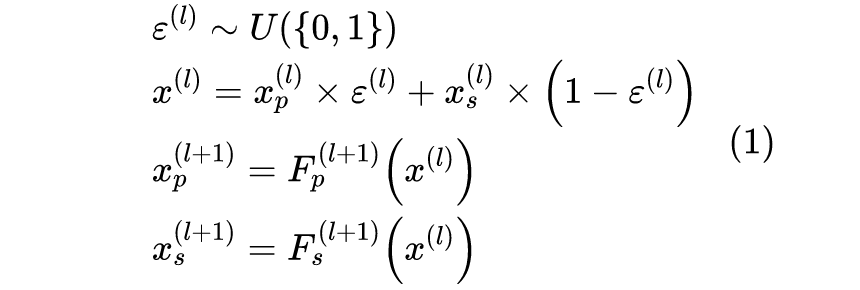
2.3 Method Analysis
What advantages does BERT-of-Theseus have compared to distillation? First of all, since it can be published, its effectiveness should be at least comparable, so we will not compare effectiveness, but rather the methods themselves. Clearly, the main feature of BERT-of-Theseus is: simplicity.
As mentioned earlier, distillation often requires matching intermediate layer outputs, which involves many training objectives: downstream task loss, intermediate layer output loss, correlation matrix loss, attention matrix loss, etc. Just thinking about balancing these losses can be a headache.
In contrast, BERT-of-Theseus directly enforces that the Successor has outputs similar to the Predecessor through the replacement operation, and the final training objective is only the downstream task loss, which is undeniably simple.
Moreover, BERT-of-Theseus has a special advantage: many distillation methods need to operate simultaneously during both pre-training and fine-tuning phases to achieve significant results, while BERT-of-Theseus directly acts on fine-tuning for downstream tasks, achieving comparable results. This advantage is not reflected in the algorithm but is an experimental conclusion.
Formally, the random replacement idea of BERT-of-Theseus is somewhat similar to data augmentation schemes like SamplePairing and mixup in images (refer to “From SamplePairing to mixup: The Magic of Regularization” [4]), both of which involve randomly sampling two objects and weighted summation to enhance the original model; it also resembles the progressive training scheme of PGGAN [5], which achieves a transition between two models through a certain degree of mixing.

Brother Qiu Zhenyu also shared his explanation [6] and a TensorFlow implementation based on the original BERT: qiufengyuyi/bert-of-theseus-tf [7]. Of course, since I decided to write this introduction, I cannot miss a Keras implementation based on bert4keras:
https://github.com/bojone/bert-of-theseus
This is probably the most concise and readable implementation of BERT-of-Theseus, bar none.

It can be seen that compared to directly fine-tuning the first few layers, BERT-of-Theseus indeed brings a certain performance improvement. For the random zeroing scheme, aside from equal probability selection of 0/1, the original paper also tried other strategies with slight improvements; however, they introduced extra hyperparameters, so I did not experiment further. Interested readers can modify and try it themselves.
Additionally, regarding distillation, if the Successor has the same structure as the Predecessor (same model distillation), then generally speaking, the final performance of the Successor is often better than that of the Predecessor. Does BERT-of-Theseus have this characteristic?


References

[1] https://github.com/bojone/bert4keras
[2] https://arxiv.org/abs/2002.11794
[3] https://www.zhihu.com/question/303922732
[4] https://kexue.fm/archives/5693
[5] https://arxiv.org/abs/1710.10196
[6] https://zhuanlan.zhihu.com/p/112787764
[7] https://github.com/qiufengyuyi/bert-of-theseus-tf
Further Reading




#Submission Channel#
Make Your Paper Seen by More People
How can high-quality content reach readers more quickly, reducing the cost of finding quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly may serve as a bridge, facilitating the collision of scholars and academic inspiration from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university laboratories or individuals to share various high-quality content on our platform, whether it be latest paper interpretations, learning insights, or technical content. Our sole purpose is to make knowledge truly flow.
📝 Submission Standards:
• The manuscript must be an original personal work, and the author’s personal information (name + school/work unit + education/position + research direction) must be specified in the submission.
• If the article is not a first publication, please remind us during submission and attach all published links.
• PaperWeekly assumes every article is a first publication and will add an “original” label.
📬 Submission Email:
• Submission Email: [email protected]
• All images for the article should be sent separately as attachments.
• Please leave immediate contact information (WeChat or phone) so that we can communicate with the author during editing and publishing.
🔍
Now, you can also find us on “Zhihu”
Search for “PaperWeekly” on Zhihu’s homepage
Click “Follow” to subscribe to our column!
About PaperWeekly
PaperWeekly is an academic platform that recommends, interprets, discusses, and reports on cutting-edge AI research papers. If you study or work in the AI field, feel free to click “Group Chat” in the background of our official account, and our assistant will bring you into the PaperWeekly group chat.

