
Baido NLP Column
Author: Baido NLP
Introduction
In recent years, we have been deeply engaged in the integration of neural network models with NLP tasks, achieving significant progress in various areas such as syntactic analysis, semantic similarity computation, and chat generation. In search engines, semantic similarity features have also become one of the most important features in relevance ranking systems. As models become more complex, evolving from the initial Bag of Words (BOW) model to Convolutional Neural Networks (CNN) that model short-distance dependencies, Recurrent Neural Networks (RNN) that model long-distance dependencies, and Matrix Matching Neural Networks (MM-DNN) based on word-to-word matching matrices, the requirements for industrial applications have increased. Due to the complexity of language, diverse expressions, and widespread applications, we have introduced more NLP features into DNN models, such as binary structure features based on t-statistics and word collocation structure features based on dependency analysis techniques.
More complex models, stronger features, and larger datasets pose higher requirements for industrial applications. Effectively controlling memory usage, reducing computational load, and lowering power consumption are critical issues facing the development of deep neural network models. The research on compression algorithms not only enhances the scalability of models but also opens up broader application scenarios and immense imaginative space.
At Baido, taking the search scenario as an example, the scale of neural network parameters used for relevance ranking reaches hundreds of millions, while online environments have strict requirements for computational resources, making model expansion challenging. Therefore, we have introduced model compression algorithms such as Log Domain Quantization, Multi-Level Product Quantization, and various Sub-Random Hashing, which have been practically verified to achieve a compression ratio of up to 1/8. Moreover, these methods have excellent generality and can be applied to various neural network application scenarios.
Log Domain Quantization Compression
For NLP tasks, many existing deep neural network models apply dictionaries with millions of words, with the parameters of the embedding layer accounting for the majority of the entire model. Thus, to address the memory consumption of the model, we start with the embedding layer. Figure 1 shows the value distribution of the parameters in the embedding layer of the convolutional neural network model used for the relevance ranking system:
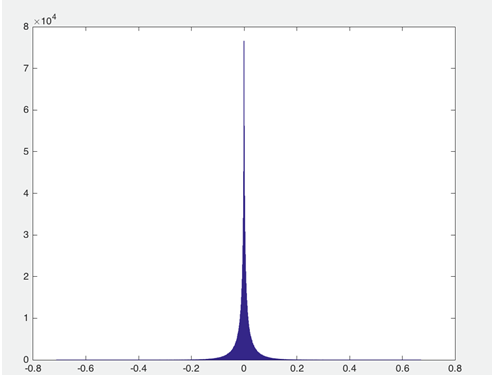
Figure 1. Parameter Value Distribution of the Embedding Layer
From the distribution chart above, we can see the following characteristics of the data distribution:
1. The range of parameter values is large;
2. The vast majority of parameters are concentrated in a small area, presenting a peak distribution centered around 0.
We need to quantize the parameters shown in Figure 1 to achieve the compression goal. Here, quantization refers to the process of approximating continuous values (or a large number of possible discrete values) to a limited number (or fewer) of discrete values. If we choose the entire value range and take several quantization points on average, it will result in only a few quantization points within the value range that accounts for the majority of the parameters. If we narrow the quantization range, it will lead to the loss of some important parameters, which will significantly impact the results. Therefore, we need to find a method to select quantization points that: on one hand maintains the upper limit of the original model’s value range, allowing for the pruning of parameters near 0; on the other hand, selects quantization points denser in areas where parameter distribution is more concentrated.
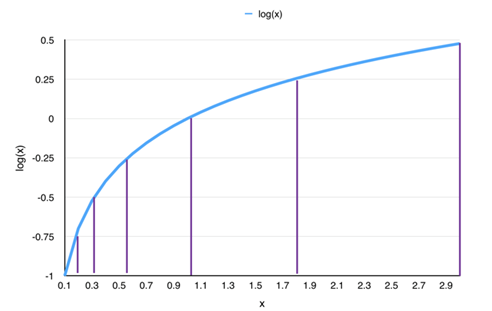
Figure 2. Log Quantization Curve
We choose to select quantization points in the Log domain to meet the above two requirements. From Figure 2, it can be seen that by averaging the quantization points in the Log domain, these points are mapped to the original parameter space, and the closer the quantization points are to 0, the denser they will be. The specific algorithm is as follows: first, based on the number of quantization bits (denoted as b in this article, meaning the final number of quantization points is 2b), we take the corresponding number of quantization points from large to small; then, we retain the upper limit of the original model’s value range and prune parameters near 0. Log domain quantization compression is highly effective, with the advantage that it can achieve lossless compression with a quantization bit count of 8, which means the embedding space of the deep neural network model is quantized into only 28=256 discrete values; the original model does not need to be retrained.
Using this method, we achieved a 1/4 lossless compression of the deep neural network semantic model in Baido search, ensuring that the online model’s expressive capability remains unchanged and the application effect is consistent, while reducing the memory usage of all online models by 75%.
Multi-Level Product Quantization Compression
To achieve greater compression rates with quantization methods, we explored product quantization compression. Here, the product refers to the Cartesian product, meaning decomposing the embedding vector according to the Cartesian product and quantizing the decomposed vectors separately. Unlike Log domain quantization compression, product quantization compression mainly varies in the quantization unit: the former’s quantization unit is a number, while the latter’s quantization unit is a vector. Figure 3 shows an example where the dimension of the decomposed vectors is set to 4, and these 4-dimensional decomposed vectors are quantized using K-means clustering (assuming the quantization bit count is b, then K in K-means is 2b), and only the cluster center IDs need to be stored for these 4-dimensional vectors to achieve compression.
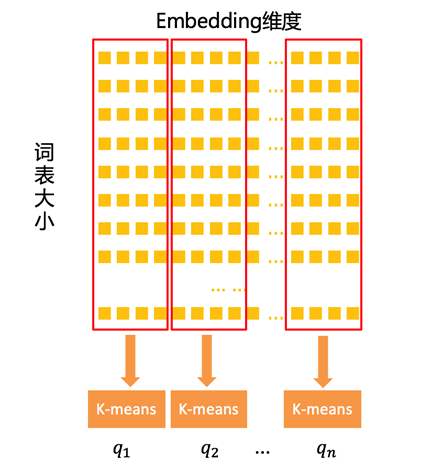
Figure 3. Product Quantization Compression Diagram
Based on experiments with Baido’s deep neural network model, we analyzed and reached several conclusions:
1. A quantization vector dimension of 1 can achieve 1/4 lossless compression;
2. A quantization vector dimension of 2 can achieve 1/5 lossless compression;
3. When the quantization dimension is fixed, a larger quantization bit count results in a lower compression rate and better model performance;
4. With a fixed compression rate, as the quantization dimension increases, the compression effect first increases and then decreases, achieving the best effect at 2 dimensions.
It can be seen that using the product quantization strategy alone can achieve a maximum of 1/5 lossless compression, which does not significantly improve upon Log domain quantization compression.
To further enhance the compression effect, we introduced multi-level product quantization compression. Based on the importance of words in the vocabulary, we applied different parameters for product quantization. Important words have a lower compression rate, using product quantization with a dimension of 1 and a quantization bit count of 8; less important words use parameters with a higher compression rate, such as a dimension of 2 and a quantization bit count of 8; and the least important words use parameters with the highest compression rate, such as a dimension of 4 and a quantization bit count of 12. This multi-level division is obtained through fully automated optimization. In the application of Baido’s deep neural network semantic model, we achieved a 1/8 lossless compression through multi-level product quantization, and the original model does not need to be retrained, making it convenient to use.
Multi-Seed Random Hashing Compression
So far, multi-level product quantization can achieve 1/8 lossless compression. Are there compression algorithms with greater compression rates that can support ultra-large-scale DNN models? Multi-seed random hashing is such a compression algorithm: it can configure any compression rate within a lossless or acceptable lossy range, making it suitable for different application scenarios. Figure 4 illustrates this:
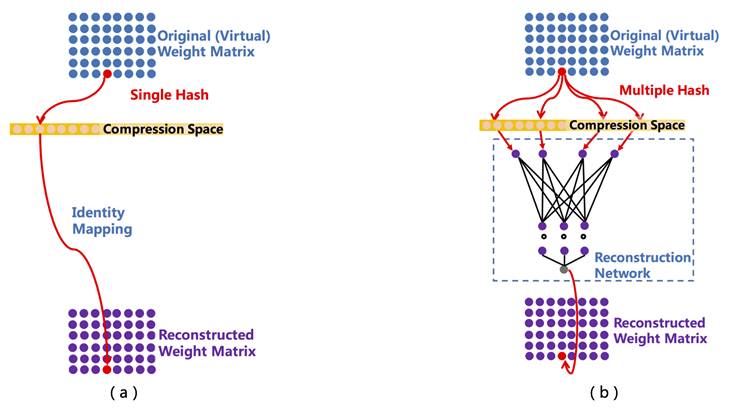
Figure 4. a) Single Seed Random Hashing Compression Algorithm; b) Multi-Seed Random Hashing Compression Algorithm
Figure 4-a) is the “Compressing Neural Networks with the Hashing Trick” published by Wenlin Chen at ICML 2015, where the main idea is to connect the original space and the compressed space through a single-seed random hashing function and to achieve any configured compression rate by setting the size of the compressed space. However, in this method, the compression rate is directly proportional to the conflict rate (where conflict refers to different points in the original embedding space falling into the same position in the compressed space), and a high conflict rate can lead to loss of effectiveness. Figure 4-b) is the multi-seed random hashing compression algorithm proposed to reduce the conflict rate. Its process is as follows: for a parameter to be decompressed, first obtain multiple random hash values based on its position, map them to the user-configured compressed space, and extract the corresponding hash values as input for the lightweight reconstruction neural network (shown in the dashed box of Figure 4-b), whose output is the reconstructed parameter value. Compared to the single-seed random hashing compression algorithm, the multi-seed random hashing compression algorithm has a lower conflict rate and achieves a higher compression rate in multiple tasks without loss of effectiveness.
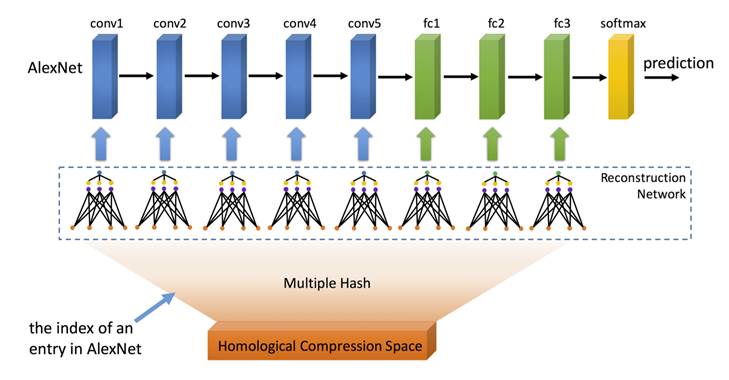
Figure 5. Homogeneous Multi-Seed Random Hashing Compression Algorithm
Furthermore, we extended the multi-seed random hashing compression algorithm to other neural network layers, such as convolutional layers and fully connected layers. However, this raises a question: how to set the compression rates for different layers? To solve this problem, we proposed the homogeneous compression algorithm, as shown in Figure 5, where all layers of the deep neural network share a common compression space, while different layers have their own lightweight reconstruction neural networks. This approach not only facilitates the setting of a unified compression rate but also experimental results indicate better compression effects. Figure 6 shows the error rate under different compression rates when the network size is fixed, demonstrating that with different datasets and models of varying depths, the homogeneous multi-seed random hashing compression algorithm (HMRH) exhibits a lower error rate compared to the single-seed random hashing compression algorithm (HashedNets) at the same compression rate.
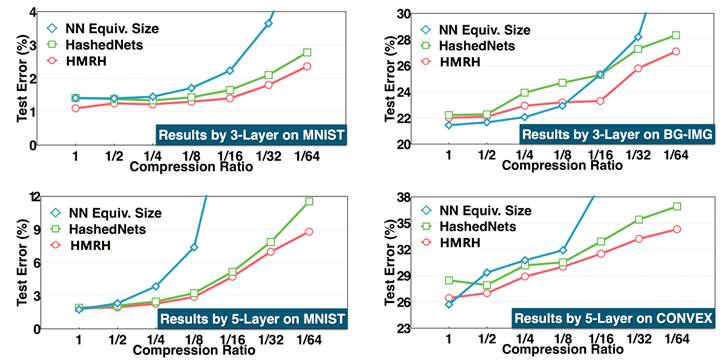
Figure 6. Error Rate at Different Compression Rates with Fixed Network Size
The multi-seed random hashing compression algorithm can be combined with the previously mentioned two compression algorithms to achieve greater lossless compression.
Conclusion
Thus, we have introduced three DNN model compression algorithms, each with its own advantages suitable for different application scenarios:
-
The Log Domain Quantization Compression Algorithm can achieve 1/4 lossless compression, has universality, and does not require retraining of the original model, making it convenient to use.
-
The Multi-Level Product Quantization Compression Algorithm further achieves a 1/8 lossless compression rate, allocating different compression rates for product quantization based on the importance of embeddings, making it suitable for DNN models with distinguishable embedding layers. Similarly, the original model does not require retraining, making it convenient to use.
-
The Multi-Seed Random Hashing Compression Algorithm can configure any compression rate and needs to be trained with the model. It can be combined with Log Domain Quantization Compression to achieve a greater compression rate, thus supporting ultra-large-scale DNN models. For instance, if we give 7.2 billion people a 128-dimensional embedding, it would require about 3.4T of memory for floating-point storage, which is a huge memory cost and difficult to deploy in a typical single-machine environment. If the multi-seed random hashing compression algorithm is set to a 25-fold compression rate, combined with Log Domain Quantization, it can achieve a 100-fold reduction in memory usage to 34G, making it deployable in a typical single-machine environment. Even within an acceptable range of lossy effects, setting a larger compression rate can further compress it to under 1G, supporting embedded application scenarios.
In addition to memory compression, we have also done a lot of work in reducing CPU/GPU computation for deep neural network models, one typical work being the pruning algorithm. The idea is to dynamically prune unimportant connection points and edges, making the matrix multiplication calculations sparse, thus improving forward computation speed. Due to space constraints, we will not discuss the relevant optimization methods in detail here, but interested readers can further contact us for discussion.
Baido NLP Column Extended Reading:
-
Baido NLP | Neural Network Semantic Matching Technology
-
Baido NLP | Intelligent Writing Robot: Not Competing with Humans, We Just Want Human-Machine Collaboration
-
Baido NLP | Automatic Poetry Writing vs. Ancient Poets: A Deep Dive into Baido’s “Poetry Writing for You” Technology
-
Exclusive Interview with Baido Vice President Wang Haifeng: The Road of NLP is Still Long
The “Baido NLP” column mainly focuses on the development process of Baido’s natural language processing technology, reporting cutting-edge information and dynamics, sharing industry insights and deep thoughts from technical experts.

© This article is part of the Machine Heart column, please contact this public account for authorization to reproduce.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submission or Seeking Coverage: [email protected]
Advertising & Business Cooperation: [email protected]
Click to read the original text, view the Machine Heart official website↓↓↓