
On July 18th from 13:30 to 16:30, Professor Fabian M. Suchanek, founder of the YAGO knowledge base and a professor at Télécom Paris, delivered the second report related to the knowledge base for this summer school via remote access, focusing on deep natural language processing. The report detailed the applications of deep learning in natural language processing and was divided into three main parts: Perceptron, Word Vectorization (Word2Vec), and Knowledge Base Representation.

First, he discussed the perceptron. Its essence is a computational structure born to mimic the process by which human brain neurons process information. This simple computational unit, which consists of linear computation and an activation function, possesses tremendous power; theoretically, stacking perceptrons can fit any complex function, making it a universal approximator.
Next, Professor Fabian talked about Word Vectorization (Word2Vec), which is one of the methods for generating word vectors, transforming words into “computable” and “structured” vectors. In simple terms, Word2Vec is the process of mapping sparse word vectors in one-hot encoding format to a dense vector in multiple dimensions (usually in the hundreds) using a layer of neural networks. Word2Vec has two important models: the CBOW model and the Skip-gram model. The input for CBOW is the context, and the output is the target word, predicting the target word based on the context. Skip-gram, on the other hand, has the input and output reversed; it uses the target word as input and the context as output. Word2Vec considers the contextual environment, resulting in better performance with fewer dimensions, thus being faster and more versatile, widely used in various natural language processing tasks. However, its drawback is that due to the one-to-one relationship between words and vectors, it cannot resolve the problem of polysemy. Word2Vec is a static representation method; although it is highly versatile, it cannot be dynamically optimized for specific tasks. Furthermore, through the transformation from words to vectors, Word2Vec supports various operations based on vectors. As shown in Figure 1, the word “king” frequently appears alongside “queen,” while “man” often appears with “woman.” Through Word2Vec analysis, it can be observed that the vector representing “king” has a simple relationship with the vectors representing “queen,” “man,” and “woman”: king = queen – woman + man.
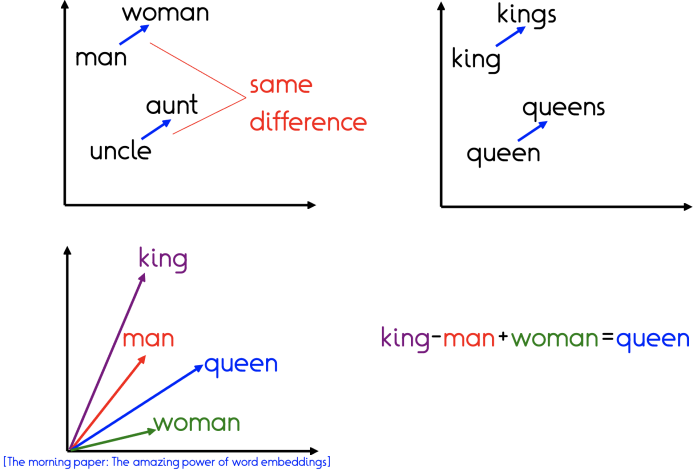
Figure 1 Application of Word2Vec
Next, Professor Fabian introduced Knowledge Base Representation, focusing on the TransE model. Representation learning originated from the Word2Vec model and toolkit proposed by Mikolov et al. in 2013, which has gained widespread attention in the field of natural language processing. Using this model, Mikolov et al. discovered the phenomenon of translational invariance in the word vector space (Figure 2). Inspired by this translational invariance, Bordes et al. proposed the TransE model, treating the relationships in the knowledge base as some form of translational vector between entities. For each fact triplet (head entity, relationship, tail entity), the TransE model represents entities and relationships in the same space, where the relationship vector can be viewed as a translation between the head entity vector and the tail entity vector, i.e., head entity vector + relationship vector ≈ tail entity vector. For example, for the given facts (Jiang Wen, wife, Zhou Yun) and (Feng Xiaogang, wife, Xu Fan), we can derive: Jiang Wen + wife ≈ Zhou Yun and Feng Xiaogang + wife ≈ Xu Fan, and through translational invariance, we can also obtain: Zhou Yun – Jiang Wen ≈ Xu Fan – Feng Xiaogang, indicating that the vector representations of the two facts share the same relationship.

Figure 2 Vector Translation Relationships in TransE: Head Entity Vector + Relationship Vector ≈ Tail Entity Vector
During the report, there were multiple interactions between the teacher and students with Professor Fabian. Teacher Lu Xuesong asked about the perceptron, specifically regarding the difference between training data and input when optimizing the perceptron. When discussing support vector machines and kernel functions, the enthusiastic interaction between Professor Fabian and the students deepened their understanding. Additionally, students showed particular interest in the combination of natural language processing and deep learning in the education sector, engaging in discussions on whether it is feasible to mine mathematical logic from natural language using deep learning. After the lecture, Professor Fabian patiently answered many questions from the students.
Speaker Biography

Fabian M. Suchanek
Fabian M. Suchanek is a full professor at Télécom Paris. He developed the YAGO knowledge base, one of the largest public general knowledge bases. For this, he received the SIGMOD Dissertation Award and the 10-Year Test of Time Award at the WWW Conference (WWW 2018). Professor Fabian’s research interests include information extraction, automated reasoning, and knowledge bases. He has published about 90 academic papers in fields such as ISWC, VLDB, SIGMOD, WWW, CIKM, ICDE, and SIGIR, with his works being cited over 10,000 times.
Written by | Tang Moming
Typeset by | Sun Jiabo

School of Data Science and Engineering, East China Normal University
