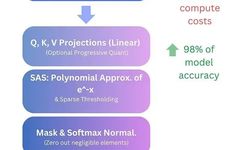
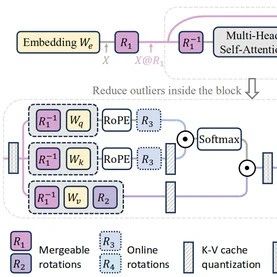
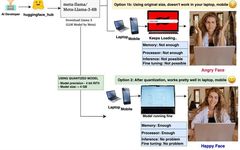
Why Large Models Need Quantization and How to Quantize
MLNLP community is a well-known machine learning and natural language processing community, covering both domestic and international NLP master’s and doctoral students, university teachers, and corporate researchers. The Vision of the Community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners. Reproduced … Read more