
Approximately 3500 words, recommended reading time 10 minutes.
Today, we will explore the core technologies behind large models!
1. Transformer
The Transformer model is undoubtedly the solid foundation of large language models, ushering in a new era in deep learning. In the early stages, Recurrent Neural Networks (RNNs) were the core means of handling sequential data. Although RNNs and their variants showed exceptional performance in certain tasks, they often fell into the traps of gradient vanishing and model degradation when faced with long sequences, making them difficult to tackle. To overcome this technical bottleneck, the Transformer model emerged, shining like dawn’s light, illuminating the path ahead.
Subsequently, in 2020, OpenAI proposed the famous “scaling law,” which profoundly revealed the astonishing exponential growth relationship between model performance and the number of parameters, data volume, and training duration. Against this backdrop, researchers shifted their focus to the foundations of large language models, with models like GPT and BERT based on Transformers achieving remarkable success in the field of natural language processing, shining like brilliant stars in the sky of artificial intelligence.

Model Principles:
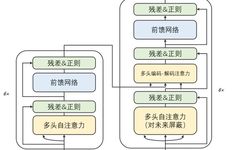
The Transformer model consists of an encoder and a decoder, stacked with multiple layers, including self-attention sublayers and linear feedforward neural network sublayers. The self-attention sublayer generates unique representations of input sequence positions, while the linear feedforward network generates rich representations. Both the encoder and decoder include positional encoding layers to capture positional information.
Model Training:
The training of the Transformer model relies on backpropagation and optimization algorithms (such as stochastic gradient descent). This involves calculating the gradient of the loss function and adjusting weights to minimize the loss. To improve speed and generalization capability, regularization and ensemble learning strategies are employed.
Advantages:
-
Solves the problems of gradient vanishing and model degradation, capturing long-term dependencies. -
Strong parallel computing capability, supporting GPU acceleration. -
Excels in tasks such as machine translation, text classification, and speech recognition.
Disadvantages:
-
High computational resource requirements. -
Sensitive to initial weights, may lead to unstable training or overfitting. -
Limited in handling ultra-long sequences.
Application Scenarios:
Widely used in the field of natural language processing, such as machine translation, text classification, and generation. It is also applied in image recognition and speech recognition.
Python Example Code (Simplified):
import torch
self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
batch_size, tgt_len, tgt_vocab_size = tgt.size(0), tgt.size(1), self.decoder.out_features
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
target_input = tgt[:, :-1].contiguous().view(batch_size * tgt_len, -1)
output2 = self.transformer_decoder(target_input, output).view(batch_size, tgt_len, -1)
prediction = self.decoder(output2).view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * - (torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# Hyperparameters
d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward = 512, 8, 6, 6, 2048
# Instantiate model
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
# Randomly generate data
src, tgt = torch.randn(10, 32, 512), torch.randn(10, 32, 512)
# Forward pass
prediction, predictions = model(src, tgt)
print(prediction)2. Pre-training Techniques
GPT can be seen as a pre-training paradigm based on the Transformer architecture, learning general features through large-scale pre-training data, widely applied in computer vision, natural language processing, and other fields.
Core Principle: Large model pre-training techniques extract language knowledge and semantic information from massive data. During the pre-training phase, the model learns text patterns using self-attention mechanisms; in the fine-tuning phase, it adapts to specific task requirements through supervised learning.
Training Process: Includes data collection and preprocessing, model selection, pre-training, and fine-tuning. Pre-training uses unlabeled data to learn language structures and semantics; fine-tuning adjusts model parameters using labeled data for specific tasks.
Role of Pre-training Techniques: Enhances performance by learning more language knowledge to improve accuracy, generalization ability, and robustness; accelerates training by providing accurate initial weights, avoiding gradient issues, saving time and resources; improves generalization ability, reducing overfitting risks, adapting to different tasks and domains.
3. RLHF
This method ingeniously uses human judgment as a reward signal to guide model behavior, allowing the model to learn and internalize behavior patterns that align more closely with human values. In RLHF, human feedback is crucial; it not only provides direct feedback on model behavior but also helps the model continuously optimize its decision-making process.
The training process of RLHF consists of a series of carefully designed steps, including selecting and loading pre-trained models, supervised fine-tuning, training reward models, and proximal policy optimization. These steps are like finely crafted procedures, aimed at enabling the model to learn how to accurately adjust its behavior based on human feedback, thus making its outputs more aligned with human expectations and standards.
In the vast realm of large model technology, RLHF plays a pivotal role. It not only enhances the performance and reliability of models but also promotes the alignment of models with ethical and human values. Through the perfect combination of reinforcement learning and human feedback, RLHF enables models to better understand and adapt to the specific requirements of tasks while effectively reducing erroneous decisions caused by environmental noise or data bias. Additionally, RLHF ensures that the model’s behavior always adheres to human ethical standards, avoiding any inappropriate outputs or decisions.
4. Model Compression
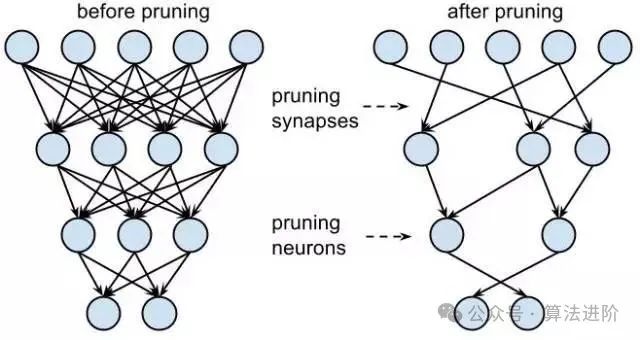
Large model compression techniques, such as weight pruning, quantization, and knowledge distillation, not only significantly reduce the model size but also demonstrate excellent performance optimization effects. The positive impacts of its practical applications mainly include the following aspects:
-
Reducing Storage and Computational Burden:Model compression techniques effectively reduce the required storage space and computational resources, making models easier to deploy on various constrained devices while significantly improving inference speed, providing users with a smoother experience.
-
Improving Deployment Efficiency and Convenience:Simplified models exhibit greater adaptability in cross-device deployment and integration, reducing deployment difficulty and costs, further broadening the application scope of deep learning technologies across various fields.
-
Precisely Maintaining Model Performance:Through carefully designed compression algorithms and training strategies, model performance can be effectively maintained during the compression process. This makes model compression an efficient and practical optimization method that ensures performance is not compromised while reducing resource demands.
The core goal of model compression technology is to reduce model size while maintaining performance, adapting to the limitations of different computing devices and improving deployment speed. The main technical means include:
-
Weight Pruning:By accurately identifying and removing unimportant weights in the model, the redundancy of the model is effectively reduced, making it more compact and efficient.
-
Quantization Techniques:Converting originally used high-precision floating-point parameters to fixed-point or low-precision floating-point numbers, thereby significantly reducing model volume and lowering storage and computational costs.
-
Knowledge Distillation:Using a large teacher model to impart knowledge and experience to a smaller student model, allowing the student to maintain performance while significantly reducing model size, achieving efficient knowledge transfer and model optimization.
5. Multimodal Fusion
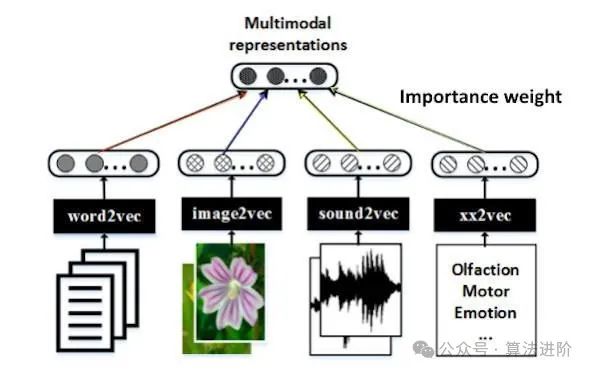
The multimodal fusion technology of large models greatly enhances the model’s perception and understanding capabilities by effectively integrating data from various modalities, thereby significantly improving its performance and broadening its application scope. This technology plays a crucial role in multiple fields:
-
Optimizing Model Performance:Multimodal fusion technology allows models to gain a deeper understanding of the connotations of input data, significantly enhancing their performance. Whether in image classification, speech recognition, or sentiment analysis, this advantage is fully realized. -
Enhancing Robustness:Multimodal data possesses stronger resistance to interference, effectively countering various noise and disturbance factors. The application of multimodal fusion technology enables models to acquire information from different angles, further enhancing their ability to withstand noise and disturbances, ensuring stable data output. -
Expanding Application Scenarios:This technology provides the possibility for models to handle more complex and diverse tasks, enabling them to deal with a wider variety of data types. For instance, in the intelligent customer service field, multimodal fusion technology allows customer service systems to process both text and voice inputs simultaneously, providing users with a more natural and smooth interactive experience.
Multimodal fusion technology captures information comprehensively and accurately by integrating data from different modalities, such as text, images, and audio. The key lies in the rich complementary information contained between different modalities; by fusing this information, models can achieve a more comprehensive understanding of the data’s connotation, thereby enhancing their perception and understanding capabilities.
During the fusion process, several key stages are involved, including data preprocessing, feature extraction, and fusion algorithms. First, in the data preprocessing stage, data is cleaned, labeled, and aligned to ensure quality and consistency. Then, feature extraction techniques, such as Convolutional Neural Networks (CNNs) for image features and Recurrent Neural Networks (RNNs) for text features, are used to extract key information from different modalities. Finally, effective fusion algorithms are employed to integrate these features, generating more comprehensive and accurate feature representations, further enhancing model performance and application capabilities.
6. Money is All You Need!

Ultimately, financial capability is the core driving force behind large model training! The training and operation of large models are undoubtedly resource-intensive projects, encompassing massive investments in computing power, manpower, and electricity, all of which rely on solid financial support.
First, the training of large models relies on the strong support of high-performance computer clusters. These clusters are equipped with a massive number of CPUs, GPUs, or TPUs, providing robust support for large-scale parallel computing.
Secondly, the training of large models also requires a team of highly skilled professionals. This team gathers data scientists, engineers, and researchers, all of whom possess deep expertise and skills in algorithms, models, and data.
Lastly, the operation of high-performance computer clusters relies on a continuous supply of electricity. In large-scale training processes, electricity costs account for a significant portion. Without adequate financial backing, it is undoubtedly a daunting task to bear such massive electricity consumption.
In summary, technologies like Transformers based on scaling laws open a new era for large models. However, money plays a crucial role; it determines how far large models can go and whether they can continuously bring us more innovations and surprises!
About Us
Data Pai THU, as a data science public account, is backed by Tsinghua University’s Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a platform for gathering data talent, and creating the strongest group of China’s big data.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU