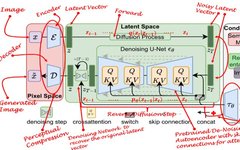
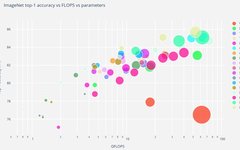
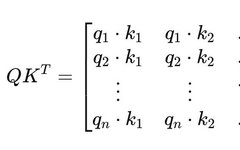How Multimodal Large Language Models (MLLMs) Are Reshaping Computer Vision

Interpretation: AI Generates the Future This article introduces the Multimodal Large Language Model (MLLM), its definition, applications using challenging prompts, and the top models that are reshaping computer vision. Table of Contents What is a Multimodal Large Language Model (MLLM)? Applications and Cases of MLLMs in Computer Vision Leading Multimodal Large Language Models Future Outlook … Read more