 Source: Machine Learning AI Algorithm Engineer
Source: Machine Learning AI Algorithm Engineer
This article is approximately 1000 words, and it is recommended to read in 5minutes.
This article introduces six common patterns of text vectorization.
1. Text Vectorization
Text vectorization: representing text information as vectors that can express the semantics of the text, using numerical vectors to represent the semantics of the text. Word Embedding: a method of converting words in text into numerical vectors, which falls under the category of text vectorization processing. The challenges faced by vector embedding operations include:
(1) Information Loss: Vector representation needs to preserve the structure of information and the relationships between nodes.
(2) Scalability: The embedding method should be scalable and capable of handling variable-length text information.
(3) Dimensionality Optimization: High dimensionality can improve accuracy, but it also amplifies time and space complexity. Low dimensionality, while having lower time and space complexity, comes at the cost of losing original information, thus requiring a trade-off in the choice of optimal dimensions.
Common text vectorization and word embedding methods include One Hot Model, Bag of Words Model, TF-IDF, N-Gram, Word2vec, and Doc2vec.
2. One-Hot Encoding
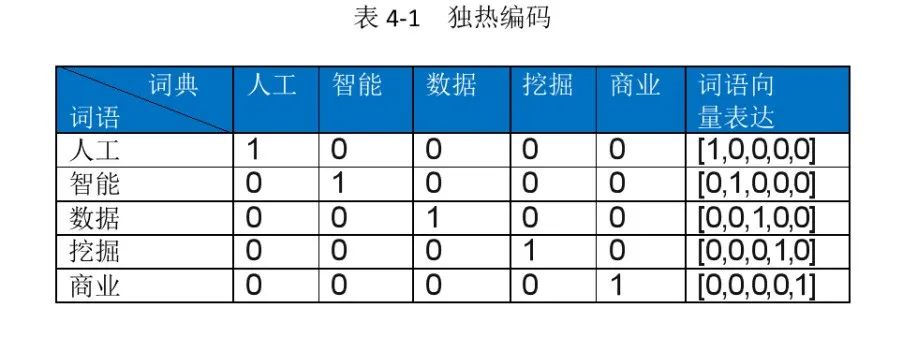
One-hot encoding uses an N-bit state register to encode N states, representing categorical variables as binary vectors.
First, a dictionary is constructed based on the provided text, where the numbers can be seen as labels corresponding to words or classification information of objects.
Then, based on the one-hot encoding expression, an N-dimensional vector is constructed, where the dimension matches the length of the dictionary. When vectorizing a given word, the register at the corresponding position where it appears in the dictionary is set to 1, while the others are set to 0, as shown below:
3. Bag of Words Model
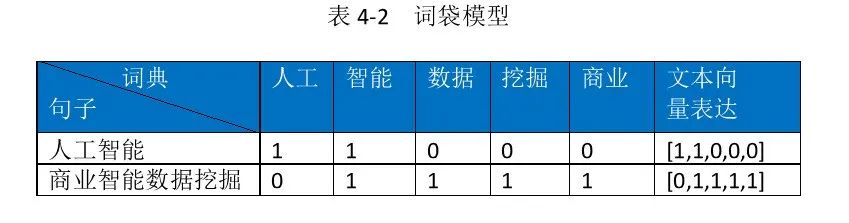
The Bag-of-Words model (BOW) assumes that for a given text, the order of words and grammatical factors are ignored, treating it as a simple collection of vocabulary. Each word’s occurrence in the document is considered independent, not reliant on other words. First, the sentence is vectorized, with the sentence dimension matching the dictionary dimension; the number at the i-th dimension represents the frequency of the word with ID i appearing in that sentence.
4. TF-IDF Model
TF-IDF (term frequency-inverse document frequency) is a commonly used statistical technique in data mining. TF (Term Frequency) refers to the frequency of a term, and IDF (Inverse Document Frequency) refers to the inverse document frequency index.
Term frequency counts how often a term appears in a specific document, while inverse document frequency counts how often a term appears in other articles. The basic logic is that a term’s importance increases with its frequency in a specific document but decreases with its frequency in other documents in the corpus. The mathematical expression is as follows:
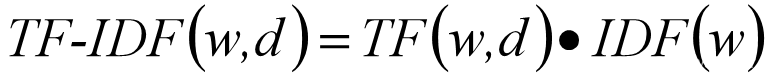
5. N-Gram Model
The N-Gram language model is based on the given text information to predict the next most likely word. N=1 is called unigram, indicating that the occurrence of the next word does not depend on any previous words; N=2 is called bigram, indicating that the next word only depends on the immediately preceding word, and so on.
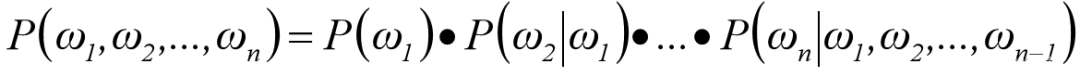
6. Word-Vector Model
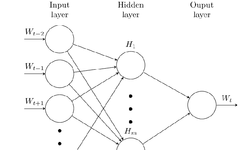
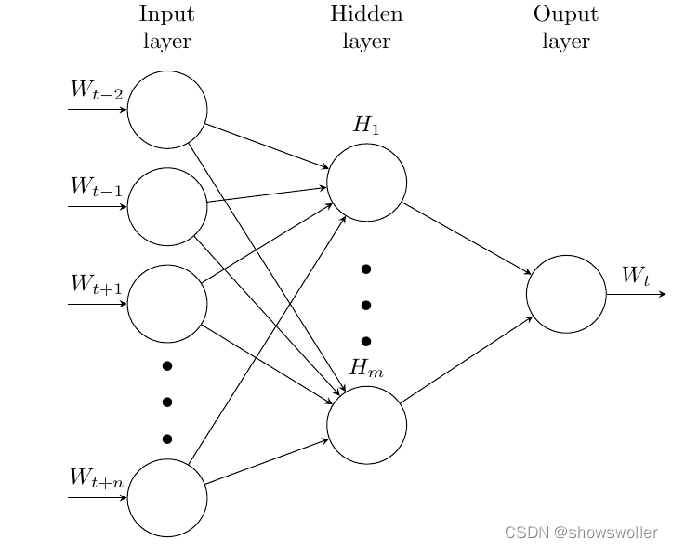
Transforming uncomputable, unstructured words into computable, structured vectors. The word2vec model assumes that the order of word occurrences is not important. Word2Vec includes two network structures: the Continuous Bag of Words (CBOW) and the Skip-gram model. After training, the model can establish a mapping relationship between words and vectors, thus representing the relationship between words.
The CBOW model is as follows:
Editor: Wang Jing
Proofreader: Lin Yilin
