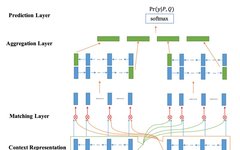
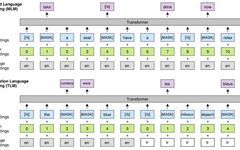
Essential Interview Preparation for AI Roles: XGBoost, Transformer, BERT, and Wave Network Principles

Yunzhong from Aofeisi Quantum Bit Edited | Public Account QbitAI In today’s era of artificial intelligence, most people pay attention to deep learning technologies, but please do not overlook the understanding of traditional machine learning techniques. In fact, when you truly engage in AI work, you will find that the dependence on traditional machine learning … Read more