Large models based on the Transformer architecture are playing an increasingly important role in artificial intelligence, especially in the fields of natural language processing (NLP) and computer vision (CV). Model compression methods reduce their memory and computational costs, which is a necessary step for implementing Transformer models on practical devices. Given the unique architecture of Transformers, particularly the alternating attention mechanism and the feedforward neural network (FFN) module, specific compression techniques are required. The efficiency of these compression methods is also crucial, as it is often impractical to retrain large models on the entire training dataset. This overview provides a comprehensive review of recent compression methods, with a particular focus on their application to Transformer models. Compression methods are primarily divided into four categories: pruning, quantization, knowledge distillation, and efficient architecture design. In each category, we discuss compression methods for CV and NLP tasks, emphasizing common underlying principles. Finally, we delve into the relationships between various compression methods and discuss further directions in the field.
Deep neural networks have become an indispensable part of numerous AI applications, encompassing various forms such as multilayer perceptrons (MLP), convolutional neural networks (CNN), recurrent neural networks (RNN), long short-term memory networks (LSTM), and Transformers. Recently, Transformer-based models have become the mainstream choice across various fields, including natural language processing (NLP) and computer vision (CV). Given their powerful scalability, most large models with over billions of parameters are based on the Transformer architecture, which are considered fundamental elements of artificial general intelligence (AGI).
Despite the significant capabilities demonstrated by large models, their enormous scale poses challenges for practical development. For example, the GPT-3 model has 175 billion parameters and requires approximately 350GB of memory model storage (float16). The vast number of parameters and the associated computational overhead demand devices with extremely high memory and computational capacity. Directly deploying such models incurs enormous resource costs and significantly increases carbon emissions. Furthermore, on edge devices like smartphones, the development of these models becomes impractical due to limited storage and computational resources.
Model compression is an effective strategy to alleviate the development costs associated with Transformer models. This approach is based on the principle of reducing redundancy and includes various categories such as pruning, quantization, knowledge distillation, and efficient architecture design. Network pruning directly removes redundant components, such as blocks, attention heads, FFN layers, or individual parameters. By adopting different pruning granularities and criteria, various sub-models can be derived. Quantization reduces development costs by using lower-bit representations for model weights and intermediate features. For example, quantizing a full-precision model (float32) to 8-bit integers can reduce memory costs by a quarter. Depending on the computational process, it can be categorized into post-training quantization (PTQ) or quantization-aware training (QAT), with the former requiring limited training costs, making it more effective for large models. Knowledge distillation, as a training strategy, transfers knowledge from a large model (teacher) to a smaller model (student). The student mimics the teacher’s behavior by simulating the teacher’s output and intermediate features. Notably, for advanced models like GPT-4, which are accessed only through APIs, the instructions and explanations they generate can also guide the learning of student models. In addition to obtaining models from predefined large models, some methods generate efficient architectures by directly reducing the computational complexity of attention modules or FFN modules. Combining different methods can achieve extreme compression. For instance, Han et al. achieved an impressive 49x compression ratio on traditional VGGNet by combining network pruning, quantization, and Huffman coding. Regarding Transformer models, their compression strategies exhibit unique characteristics. Unlike other architectures such as CNN or RNN, Transformers have a distinctive design, including alternating attention and FFN modules. The former captures global information by computing attention maps across different tokens, while the latter extracts information from each token separately. This specific architecture can inspire customized compression strategies aimed at achieving optimal compression rates. Moreover, the efficiency of compression methods is particularly critical for such large models. Due to the high computational costs of large models, it is often unaffordable to retrain the entire model on the original training set. Some highly efficient training methods, such as post-training compression, are favored.
In this overview, we aim to comprehensively investigate how to compress these Transformer models (Figure 1) and categorize methods based on quantization, knowledge distillation, pruning, and efficient architecture design. In each category, we separately investigate compression methods in the NLP and CV domains. Table 1 summarizes the main categories of compression and lists representative methods suitable for large Transformer models. Although NLP and CV are often viewed as very different fields, we observe that their model compression methods actually share similar principles. Finally, we discuss the relationships between different compression methods and propose some future research directions.
The remainder of this article is organized as follows. Section 2 introduces the basic concepts of Transformers. Following this, Section 3 discusses compression methods that maintain the architecture, including quantization and knowledge distillation—these techniques preserve the model’s architecture. Section 4 further explores architecture-preserving compression, including pruning and efficient architecture design. Section 5 explores additional Transformer compression methods. Finally, Section 6 summarizes the compression methods and discusses future research directions.
Architecture-Preserving Compression
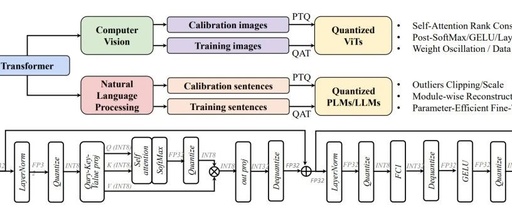
Quantization is a key step in deploying Transformers on various devices, especially for GPUs and NPUs designed specifically for low-precision arithmetic operations. (1) Post-training quantization (PTQ) [21], [41], [22], [42], [43], [44], [45], primarily focuses on optimizing the quantization parameters for weights and activations using a small amount of unlabeled calibration data, with some recent methods exploring adaptive rounding for weight quantization. (2) Quantization-aware training (QAT) [46], [47], [48], [49], [50], [51], [23], [52], [53], [54], [55], [56], [57], inserts quantization nodes into the network and trains using the full training data, where all weights and quantization parameters are optimized together. In this section, we systematically introduce model quantization research based on Transformer visual models and large language models, as shown in Figure 2.
Large models based on the Transformer architecture are playing an increasingly important role in artificial intelligence, especially in the fields of natural language processing (NLP) and computer vision (CV). Model compression methods reduce their memory and computational costs, which is a necessary step for implementing Transformer models on practical devices. Given the unique architecture of Transformers, particularly the alternating attention mechanism and the feedforward neural network (FFN) module, specific compression techniques are required. The efficiency of these compression methods is also crucial, as it is often impractical to retrain large models on the entire training dataset. This overview provides a comprehensive review of recent compression methods, with a particular focus on their application to Transformer models. Compression methods are primarily divided into four categories: pruning, quantization, knowledge distillation, and efficient architecture design. In each category, we discuss compression methods for CV and NLP tasks, emphasizing common underlying principles. Finally, we delve into the relationships between various compression methods and discuss further directions in the field.
Deep neural networks have become an indispensable part of numerous AI applications, encompassing various forms such as multilayer perceptrons (MLP), convolutional neural networks (CNN), recurrent neural networks (RNN), long short-term memory networks (LSTM), and Transformers. Recently, Transformer-based models have become the mainstream choice across various fields, including natural language processing (NLP) and computer vision (CV). Given their powerful scalability, most large models with over billions of parameters are based on the Transformer architecture, which are considered fundamental elements of artificial general intelligence (AGI).
Despite the significant capabilities demonstrated by large models, their enormous scale poses challenges for practical development. For example, the GPT-3 model has 175 billion parameters and requires approximately 350GB of memory model storage (float16). The vast number of parameters and the associated computational overhead demand devices with extremely high memory and computational capacity. Directly deploying such models incurs enormous resource costs and significantly increases carbon emissions. Furthermore, on edge devices like smartphones, the development of these models becomes impractical due to limited storage and computational resources.
Model compression is an effective strategy to alleviate the development costs associated with Transformer models. This approach is based on the principle of reducing redundancy and includes various categories such as pruning, quantization, knowledge distillation, and efficient architecture design. Network pruning directly removes redundant components, such as blocks, attention heads, FFN layers, or individual parameters. By adopting different pruning granularities and criteria, various sub-models can be derived. Quantization reduces development costs by using lower-bit representations for model weights and intermediate features. For example, quantizing a full-precision model (float32) to 8-bit integers can reduce memory costs by a quarter. Depending on the computational process, it can be categorized into post-training quantization (PTQ) or quantization-aware training (QAT), with the former requiring limited training costs, making it more effective for large models. Knowledge distillation, as a training strategy, transfers knowledge from a large model (teacher) to a smaller model (student). The student mimics the teacher’s behavior by simulating the teacher’s output and intermediate features. Notably, for advanced models like GPT-4, which are accessed only through APIs, the instructions and explanations they generate can also guide the learning of student models. In addition to obtaining models from predefined large models, some methods generate efficient architectures by directly reducing the computational complexity of attention modules or FFN modules. Combining different methods can achieve extreme compression. For instance, Han et al. achieved an impressive 49x compression ratio on traditional VGGNet by combining network pruning, quantization, and Huffman coding. Regarding Transformer models, their compression strategies exhibit unique characteristics. Unlike other architectures such as CNN or RNN, Transformers have a distinctive design, including alternating attention and FFN modules. The former captures global information by computing attention maps across different tokens, while the latter extracts information from each token separately. This specific architecture can inspire customized compression strategies aimed at achieving optimal compression rates. Moreover, the efficiency of compression methods is particularly critical for such large models. Due to the high computational costs of large models, it is often unaffordable to retrain the entire model on the original training set. Some highly efficient training methods, such as post-training compression, are favored.
In this overview, we aim to comprehensively investigate how to compress these Transformer models (Figure 1) and categorize methods based on quantization, knowledge distillation, pruning, and efficient architecture design. In each category, we separately investigate compression methods in the NLP and CV domains. Table 1 summarizes the main categories of compression and lists representative methods suitable for large Transformer models. Although NLP and CV are often viewed as very different fields, we observe that their model compression methods actually share similar principles. Finally, we discuss the relationships between different compression methods and propose some future research directions.
The remainder of this article is organized as follows. Section 2 introduces the basic concepts of Transformers. Following this, Section 3 discusses compression methods that maintain the architecture, including quantization and knowledge distillation—these techniques preserve the model’s architecture. Section 4 further explores architecture-preserving compression, including pruning and efficient architecture design. Section 5 explores additional Transformer compression methods. Finally, Section 6 summarizes the compression methods and discusses future research directions.
Architecture-Preserving Compression
Quantization is a key step in deploying Transformers on various devices, especially for GPUs and NPUs designed specifically for low-precision arithmetic operations. (1) Post-training quantization (PTQ) [21], [41], [22], [42], [43], [44], [45], primarily focuses on optimizing the quantization parameters for weights and activations using a small amount of unlabeled calibration data, with some recent methods exploring adaptive rounding for weight quantization. (2) Quantization-aware training (QAT) [46], [47], [48], [49], [50], [51], [23], [52], [53], [54], [55], [56], [57], inserts quantization nodes into the network and trains using the full training data, where all weights and quantization parameters are optimized together. In this section, we systematically introduce model quantization research based on Transformer visual models and large language models, as shown in Figure 2.
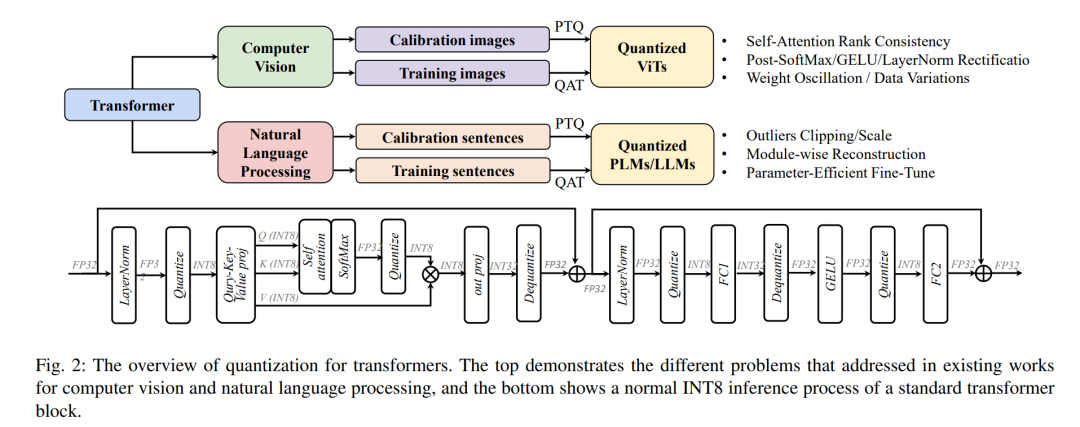
Knowledge distillation (KD) aims to train student networks by compressing [83], [84], [85] or transferring [87], [88], [86] knowledge from the teacher network. In this article, we primarily focus on distillation methods aimed at achieving a compact student model while maintaining satisfactory performance compared to the bulky teacher model. Student models typically have narrower and shallower architectures, making them more suitable for deployment on resource-constrained systems.
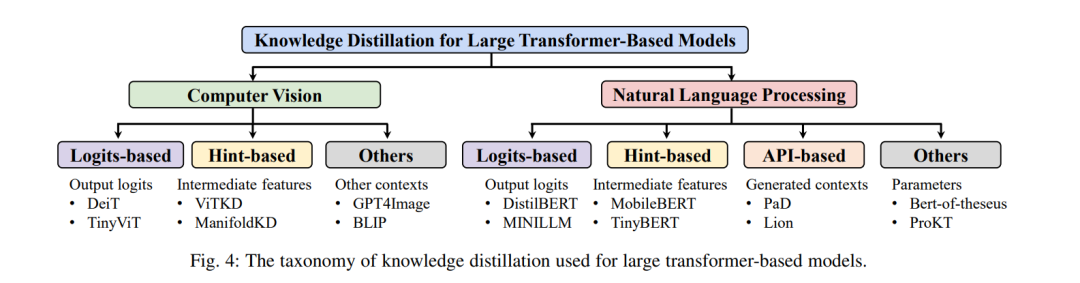
Neural network pruning has long been regarded as an effective method for reducing model size and accelerating model inference. The classification of pruning methods can be quite complex, including the sequence of pruning and model training, structural specifications, and the determination of which parameters to prune [133]. However, within the scope of this review, we limit the source model to pre-trained large Transformers targeting natural language processing [134], [4] or visual recognition [12], [26], [135], [136], and propose several specific technical categories that need to be discussed (see Figure 5).
Conclusion
In this overview, we systematically investigate the compression methods for Transformer models. Compared to traditional model compression methods, compressing Transformer models has unique considerations. Unlike other architectures such as CNN or RNN, Transformers have unique architectural designs, including alternating attention and FFN modules, which require specially customized compression methods to achieve optimal compression rates. Additionally, the efficiency of compression methods for these large models is particularly critical. Certain model compression techniques require substantial computational resources, which may be difficult to afford for such large models. This overview aims to cover most recent works related to Transformers and establish a comprehensive roadmap for their compression. Subsequently, we delve into the interconnections between various methods, address subsequent challenges, and outline future research directions.
The Relationships Between Different Compression Methods. Different compression methods can be used together to achieve extremely efficient architectures. A traditional sequence is to first define a new architecture with efficient operations. Then, redundant components (e.g., attention heads, layers) are removed to obtain a smaller model. For practical hardware implementations, quantizing weights or activations to lower bits is essential. The choice of required bit width depends not only on the tolerance for errors but also on hardware design. For example, Int8 computation is efficiently optimized on Nvidia A00 but lacks support on older Tesla P100. Distillation is often used as a training strategy applicable in both the pruning and quantization fine-tuning stages. Exploring how to combine different compression strategies for extremely high compression rates is promising. Although this has been widely explored in traditional models like CNNs, Transformer models present more complex architectures and higher computational costs. Finding suitable combination strategies through joint search is challenging.
Training Efficient Compression Strategies. Compared to compressing traditional models, there is a greater emphasis on the computational costs of compression methods. Large Transformers are currently trained on large datasets using substantial computational resources. For instance, Llama2 was trained on 20 trillion tokens over several months using thousands of GPUs. During pre-training, especially when the original data is often inaccessible, it is impractical to fine-tune with comparable computational resources. Therefore, applying efficient compression methods post-training becomes more feasible. A series of works initially developed for traditional small models have extensively researched post-training quantization, and these methods have seamlessly transitioned to Transformers. With just a few GPU hours, some recent works like GPTQ and SmoothQuant have quantized FP16 models to Int8 without causing significant performance loss. However, for lower bits (e.g., 4 bits), quantized models still suffer significant performance degradation. Notably, extremely low-bit models, such as binary Transformers, have been widely explored in traditional small models but remain relatively unexplored in the context of large models.
For pruning, the challenges after training are closely related to the granularity of pruning. While unstructured sparsity can achieve high compression rates and minimize fine-tuning requirements, similar strategies are difficult to transfer to structured pruning. Directly removing entire attention heads or layers will result in significant changes in model architecture and substantial accuracy loss. How to identify effective weights and how to effectively recover performance are insightful directions. Efficient strategies for identifying effective weights and restoring representational capacity are key research directions to address these challenges.
Efficient Architectures Beyond Transformers. In real-world applications, the input context of Transformer architectures can extend to extremely long lengths, including sequence texts in NLP (e.g., books with hundreds of thousands of words) or high-resolution images in CV. The native attention mechanism exhibits quadratic growth in complexity concerning input sequence length, posing significant computational challenges for long sequence inputs. Many studies have addressed this issue by alleviating the computational costs of attention, employing techniques such as sparse attention and local attention. However, these attention compression strategies often compromise representational capacity, leading to performance degradation. Emerging architectures like RWKV and RetNet adopt RNN-like recursive output generation, effectively reducing computational complexity to O(N). This development offers hope for further exploration of more efficient models. For computer vision tasks, even pure MLP architectures without attention modules can achieve SOTA performance. Exploring new efficient architectures by carefully studying their efficiency, generalization capabilities, and scalability beyond widely used Transformer architectures is promising.
Convenient Access to Specialized Knowledge
Convenient Download, please followSpecial Knowledge public account (click the above blue Special Knowledge to follow)

Click “Read the Original” to learn about using Special Knowledge, and view 100000+ AI-themed knowledge materials