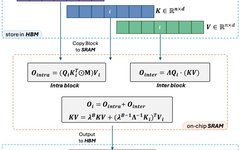
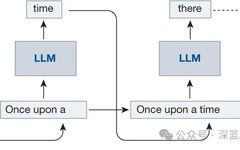
In-Depth Analysis of Self-Attention from Source Code

Follow the WeChat public account “ML_NLP” Set as “Starred” to receive heavy content promptly! Reprinted from | PaperWeekly ©PaperWeekly Original · Author|Hai Chenwei School|Master’s student at Tongji University Research Direction|Natural Language Processing In the current NLP field, Transformer/BERT has become a fundamental application, and Self-Attention is the core part of both. Below, we attempt to … Read more