Continuous Progress: Overview of New Features in TensorFlow 2.4!

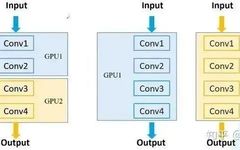
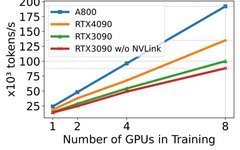
By / Goldie Gadde and Nikita Namjoshi, TensorFlow TensorFlow 2.4 has been officially released! With increased support for distributed training and mixed precision, along with the introduction of a new NumPy frontend and tools for monitoring and diagnosing performance bottlenecks, this version highlights new features and enhancements in performance and scalability. New Features of tf.distribute … Read more