来源:DeepHub IMBA
This article is approximately 1800 words long and is recommended to be read in 5 minutes.
This article will provide a detailed introduction to the principles and mechanisms of the masks in attention mechanisms.
The attention mechanism mask allows us to send batches of data of varying lengths into the transformer at once. In the code, this is done by padding all sequences to the same length and then using the “attention_mask” tensor to identify which tokens are padding. This article will detail the principles and mechanisms of this mask.
First, let’s introduce how it operates without using a mask. Here we use GPT-2 to perform inference one sequence at a time, which is very slow:
from transformers import GPT2LMHeadModel, GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained('gpt2') gpt2 = GPT2LMHeadModel.from_pretrained('gpt2') context = tokenizer('It will rain in the', return_tensors='pt') prediction = gpt2.generate(**context, max_length=10) tokenizer.decode(prediction[0]) # prints 'It will rain in the morning, and the rain'
Using batch input is faster when memory allows, as we can process multiple sequences simultaneously during one inference process. Performing inference on many samples is much faster but also slightly more complex. Below is the code for performing inference using the transformer library:
tokenizer.padding_side = "left" tokenizer.pad_token = tokenizer.eos_token sentences = ["It will rain in the", "I want to eat a big bowl of", "My dog is"] inputs = tokenizer(sentences, return_tensors="pt", padding=True) output_sequences = gpt2.generate(**inputs) for seq in output_sequences: print(tokenizer.decode(seq))
The transformer library helps us handle many details, and we will now explain in detail what it does inside.
We input tokens into language models like GPT-2 and BERT as tensors for inference. A tensor is like a Python list but has some additional features and constraints. For example, for a 2D+ tensor, all vectors in that dimension must be of the same length. For example:
from torch import tensor tensor([[1,2], [3,4]]) # ok tensor([[1,2], [3]]) # error!
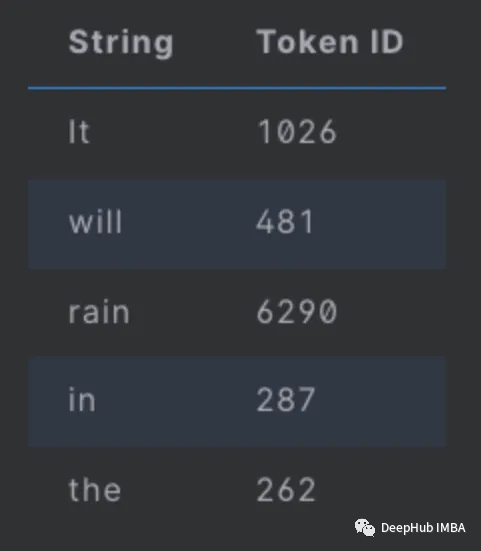
When we tokenize the input, it is converted into a tensor of sequences, where each integer corresponds to an item in the model’s vocabulary. Below is an example of tokenization in GPT-2:
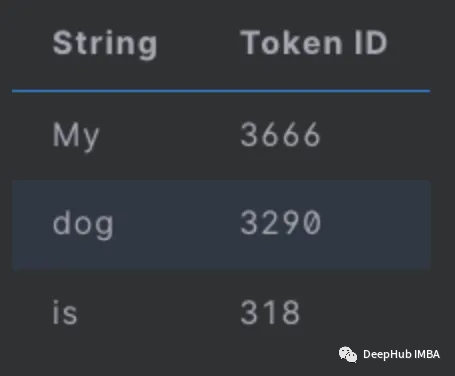
If we want to include a second sequence in the input:
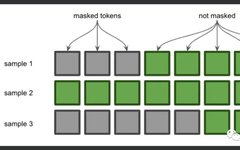
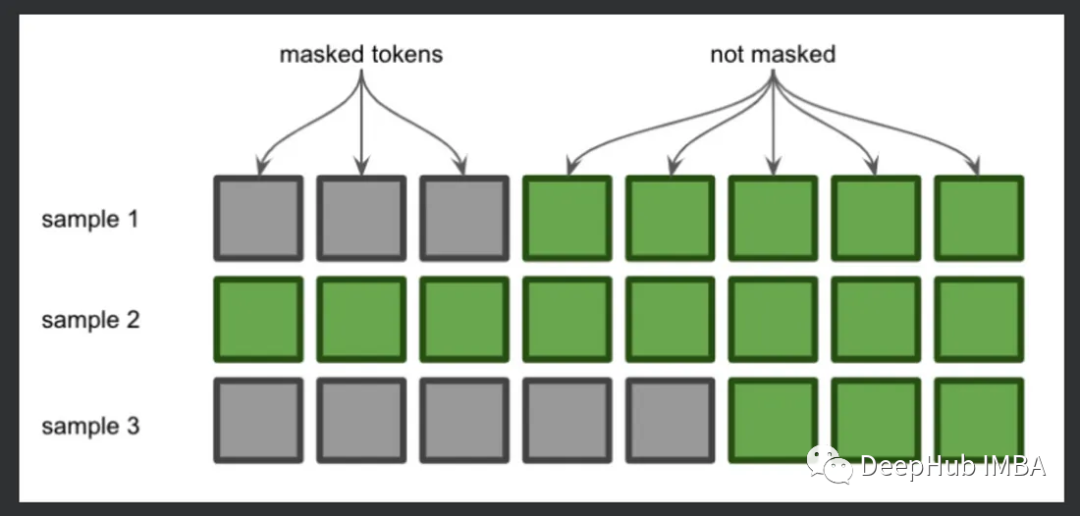
Since these two sequences have different lengths, they cannot be combined into one tensor. In this case, we need to pad the shorter sequence with dummy tokens so that each sequence has the same length. Since we want the model to continue adding to the right side of the sequence, we will pad the left side of the shorter sequence.
This is one application of the attention mask. The attention mask tells the model which tokens are padding, placing 0 at the positions of padding tokens and 1 at the positions of actual tokens. Now that we understand this, let’s look at the code line by line.
tokenizer.padding_side = "left"
This line tells the tokenizer to pad from the left (the default is from the right), because the logits of the rightmost tokens will be used to predict future tokens.
tokenizer.pad_token = tokenizer.eos_token
This line specifies which token will be used for padding. It doesn’t matter which one is chosen; here we choose the “end of sequence” token.
sentences = ["It will rain in the", "I want to eat a big bowl of", "My dog is"]
The three sequences above have different lengths when tokenized, and we use the following method to pad:
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
After performing padding and adding padding, we get the following result:
{'input_ids': tensor([ [50256, 50256, 50256, 1026, 481, 6290, 287, 262], [ 40, 765, 284, 4483, 257, 1263, 9396, 286], [50256, 50256, 50256, 50256, 50256, 3666, 3290, 318] ]), 'attention_mask': tensor([ [0, 0, 0, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1] ])}
As we can see, the first and third sequences were padded at the start, and the attention_mask parameter marked the positions of this padding.
Now let’s pass this input to the model to generate new text:
output_sequences = gpt2.generate(**inputs)
If you are not familiar with the **kwargs syntax for function calls, it passes the input dictionary as named parameters, using keys as parameter names and values as corresponding argument values.
We just need to loop through each generated sequence and print the results in a human-readable form, using the decode() function to convert token ids back to strings.
for seq in output_sequences: print(tokenizer.decode(seq))
In the attention mask, our input consists of 0s and 1s, but during the final computation, the attention weights at invalid positions are set to a very small value, usually negative infinity (-inf), so that their influence is suppressed to a probability close to zero during attention score computation.
This is because, when calculating attention weights, a Softmax computation is required:
The properties of the Softmax function: The attention mechanism typically uses the Softmax function to convert attention scores into attention weights. The Softmax function exponentiates the input values and then normalizes them. When input values are very small or negative infinity, they approach zero after exponentiation. Therefore, setting the mask to negative infinity ensures that the corresponding attention weights tend towards zero during the Softmax computation.
Excluding the influence of invalid positions: By setting the attention weights of invalid positions to negative infinity, we can effectively lower the weights of these positions. During the computation of attention weights, the negative infinity weight will make the corresponding attention weights approach zero, allowing the model to ignore the influence of invalid positions. This ensures that the model focuses better on valid information, improving its accuracy and generalization ability.
However, negative infinity is not the only option. Sometimes, a very large negative number can also be used to achieve a similar effect. The specific choice can be determined based on the specific task and model requirements.
Editor: Wenjing