Author: Sienna
Large Language Models (LLMs) have demonstrated exceptional capabilities in numerous language processing tasks; however, the computational intensity and memory consumption required for their deployment have become significant challenges to improving service efficiency. Industry estimates suggest that the processing cost of a single LLM request can be as much as 10 times that of traditional keyword searches. Faced with such high costs, we urgently need to enhance the throughput of LLM service systems and reduce the cost per request to more effectively meet user demands.©️【Deep Blue AI】Translation

The self-attention mechanism, as the cornerstone of the Transformer architecture, empowers the model to flexibly weigh the importance of different parts of the input data. In every layer of the Transformer, there exists an indispensable component—the Feed Forward Network (FFN), which can significantly enhance computational intensity and provide the model with stronger processing capabilities. When the self-attention mechanism is combined with the FFN, large language models (LLMs) based on Transformers can accurately capture the broad context and subtle differences in language, thereby exhibiting exceptional language processing capabilities. However, this powerful architecture also brings substantial computational and memory demands during training and inference.
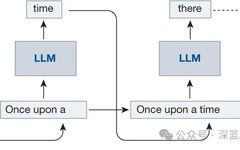
Large language models (LLMs) like GPT generate text based on autoregressive Transformer models. These models can generate tokens one by one based on a given input (prompt) and the previously generated output token sequence. For each request, this generation process is repeated until the model outputs a token indicating the end. This automatic recursive method constitutes the core of LLM inference, enabling it to generate text that is highly coherent with the context and demonstrating strong text generation abilities.
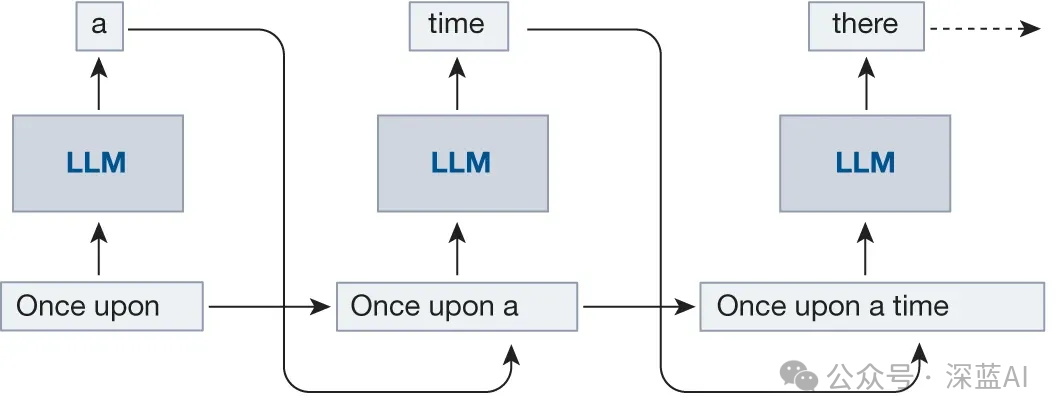
▲Figure 1|Autoregressive Generation ©️【Deep Blue AI】Translation

Due to the enormous computational and memory requirements of these models, they exhibit significant resource-intensive characteristics, which somewhat limits their adoption and application by organizations with limited computational resources. To overcome this challenge, extensive research is focused on reducing the computational resource consumption of these models. Currently, the optimization of LLM service efficiency mainly concentrates on two major directions: improvements at the algorithmic level and optimizations at the system level.

To significantly enhance the efficiency of language model inference, numerous innovative algorithms and technologies have emerged, aiming to compensate for the local performance deficiencies of large-scale Transformer models. Among these technologies, non-autoregressive decoding stands out with its ability to decode output tokens in parallel, breaking the traditional constraints of autoregressive generation and significantly improving inference speed.
Furthermore, speculative decoding has also greatly accelerated the inference process of LLMs. By utilizing a smaller draft model to generate speculative tokens, which are then verified by the target LLM, it effectively reduces the computational load during inference.
In terms of architectural design, researchers have proposed many design change suggestions to improve the performance of LLMs:
●Configuration ReductionBy reducing model configurations, achieving weight sharing, and vocabulary reduction, the model complexity can be effectively lowered. However, this reduction may also impact the performance of downstream tasks, so a balance needs to be found between the degree of reduction and performance.
●Simplifying AttentionMechanisms are also a key approach to enhancing performance. Since the complexity of self-attention calculations is proportional to the square of the input sequence length, this poses a significant challenge for processing ultra-long sequence tasks. To address this, various Transformer variants have been designed, such as FlashAttention, to simplify the standard attention mechanism and provide more efficient solutions for ultra-long sequence tasks.
●Model CompressionTechnologies aim to create more efficient and compact models to reduce the memory footprint and computational demands of LLMs. These techniques can significantly lower model complexity while maintaining performance largely unchanged, thus improving inference speed.
●Knowledge Distillationis another effective technique that allows small models (student models) to perform tasks with performance close to that of large models (teacher models) while significantly reducing computational resource requirements.
●Pruningtechniques focus on identifying and eliminating unnecessary or redundant parameters in models. In LLMs, parameters often account for a significant portion of model size and computational demands. By carefully pruning these parameters, we can streamline the model, improving its efficiency while maintaining stable performance.

While delving into enhancing algorithm efficiency, we can also further improve LLM service efficiency by optimizing the underlying systems and frameworks used for LLM inference. This optimization process primarily relies on the following key mechanisms:
●Parallel Computing:We leverage the parallel processing capabilities of modern hardware architectures to distribute computational tasks across multiple cores or devices, significantly accelerating the inference process. Among them, tensor parallelism distributes each layer’s computation across multiple devices to achieve optimal latency, while pipeline parallelism places different layers on different devices and establishes efficient pipelines between them, focusing mainly on optimizing throughput and the cost per inference.
●Low-bit Quantization:By adopting fewer bits (i.e., less than 32 bits) to represent values, we can significantly reduce memory consumption and accelerate inference speed on hardware platforms. However, quantization also comes with challenges, especially when using low-precision integer formats like INT8, where limited dynamic range may lead to precision loss during conversion from high-precision floating-point representations.
●Request Scheduling:Due to the unique characteristics of LLM services, such as iterative autoregressive decoding mechanisms, unknown output lengths, and context information state management, effectively scheduling incoming inference requests is crucial.
●Memory Optimization:Given the inherent memory-intensive nature of the transformer architecture, efficient memory management remains a significant challenge for LLM services.

Algorithm optimization plays a critical role during the training phase of large language models (LLMs). Once training is completed, we can further optimize the model’s inference latency and throughput through system optimization, thereby enhancing overall performance. In this article, we will focus on two key system optimization techniques—request scheduling and memory optimization, both of which are crucial for improving LLM service performance.
To better understand the memory demands of LLM services, we first need to gain insight into their memory distribution. The following chart illustrates the memory usage of an LLM with 13 billion parameters on an NVIDIA A100 GPU configured with 40GB of memory.

▲Figure 2|Memory Layout When Providing an LLM with 13B Parameters on NVIDIA A100 ©️【Deep Blue AI】Translation
Approximately 65% of memory resources are allocated to model weights, which remain static during service operation, providing a stable parameter foundation for the model. The self-attention mechanism of the Transformer relies on key (K) and value (V) tensors, which form the core of dynamic state, also known as the KV cache. The KV cache carries contextual information from previous tokens, which is essential for generating new output tokens sequentially. About 30% of memory is specifically reserved for storing the KV cache, ensuring the model can efficiently utilize contextual information when processing sequential data. The remaining small amount of memory is used for storing other data.
Given that model weights are fixed, our focus during GPU optimization primarily lies in the effective management of the KV cache. By optimizing the use and allocation of the KV cache, we can significantly enhance the model’s inference efficiency and reduce memory consumption.

When we send a request to the LLM service, we provide a list of input prompt tokens, and the LLM service generates a corresponding list of output tokens based on these prompts. During this process, the LLM samples and generates new tokens one by one, with each new token’s generation influenced by all previous tokens in the sequence, especially their K and V vectors. When given a request prompt, the generation computation in the LLM service can be divided into two main stages:
First is the prompt stage or pre-filling stage,where the entire user prompt is inputted, and the generation probability of the first new token is calculated. At the same time, corresponding K and V vectors are generated. Since the prompt is pre-known, the calculations in the prompt stage can utilize matrix-matrix multiplication for efficient parallel processing. Thus, this stage can leverage the parallel computing capabilities of GPUs to improve processing efficiency.
Next is the autoregressive generation stage or decoding stage,where the remaining new tokens are generated sequentially. In this process, the K and V vectors of existing tokens are typically cached for use in generating future tokens, known as the KV cache mechanism. It is important to note that a token’s KV cache relies on all previous tokens. The stage ends when the generated sequence reaches its maximum length or outputs a sequence-ending token. However, due to data dependency, calculations between different iterations cannot be processed in parallel. This results in relatively low GPU utilization during this stage and consumes considerable memory resources, leading to most of the latency for a single request.
Thus, the memory limitations of LLM inference imply that its throughput is largely constrained by the high-bandwidth GPU memory capacity. To improve throughput, we can consider batching multiple requests together. However, to process multiple requests within the same batch, efficient management of the memory space used by each request is necessary to ensure effective resource utilization and avoid issues like memory overflow.

By implementing batch processing of multiple requests, we can indeed enhance the utilization of LLM services. However, in practice, batching requests for LLM services is not straightforward, primarily due to two challenges.
First, requests often arrive at different time points, which poses a dilemma for static batching strategies: either make earlier requests wait for later ones, causing unnecessary waiting time, or delay accepting new requests until earlier ones are processed, leading to significant queuing delays.
Secondly, requests such as chat often have significantly different input and output lengths. When using static batching techniques, to ensure batch consistency, we usually need to pad the inputs and outputs of requests to make their lengths uniform, which undoubtedly wastes GPU computational resources and memory space.

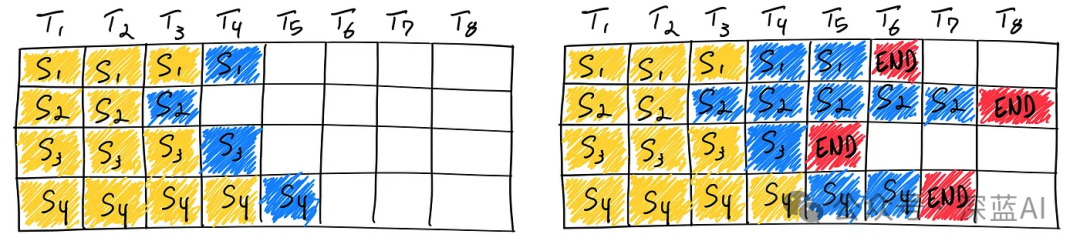
▲Figure 3|Static Batching (T represents iterations, S represents sequences) ©️【Deep Blue AI】Translation
The left side shows the scenario of the first iteration, where each sequence starts from the prompt token (yellow) to generate a token (blue). After multiple iterations, as shown on the right, the lengths of the completed sequences vary, due to different sequences triggering the sequence-ending token (red) at different iteration stages. Although sequence S3 completes first after two iterations, the GPU utilization remains low until the last sequence S2 in the batch finishes its generation process after six iterations due to the use of static batching.
To effectively address this challenge, fine-grained batching mechanisms have emerged. Unlike traditional methods that operate at the request level, these techniques refine operations to the iteration level. After each iteration ends, completed request sequences are removed from the current batch, and new request sequences are immediately added. This mechanism ensures that new requests only need to wait for one iteration to be processed, without having to wait for the entire batch process to complete.

ORCA is a typical example of a system that implements a continuous batching mechanism. ORCA does not need to wait for every sequence in the batch to complete generation but employs an iterative scheduling strategy that flexibly determines batch size based on real-time conditions. The significant advantage of this design is that once a sequence in a batch completes generation, ORCA can immediately insert a new sequence, achieving higher GPU utilization than traditional static batches.
From the diagram below, we can clearly see how continuous batching operates: seven sequences complete in succession. On the left, we observe the batch status after a single iteration; on the right, the dynamic changes in sequences within the batch after multiple iterations are displayed. Once a sequence outputs the sequence-ending token, ORCA quickly responds by seamlessly inserting a new sequence in its place (such as S5, S6, and S7). This dynamic adjustment significantly enhances GPU utilization by preventing the GPU from being idle while waiting for all sequences to complete, ensuring more efficient use of GPU resources.
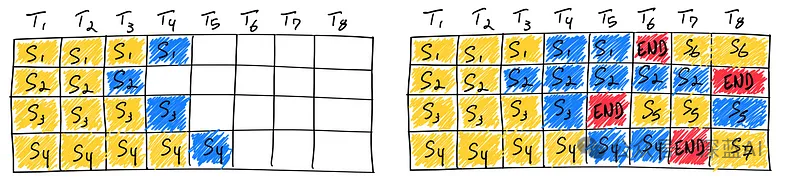
▲Figure 4|Continuous Batching ©️【Deep Blue AI】Translation

Although continuous batching effectively reduces the waste of computational resources and handles requests in a more flexible manner, the limitations of GPU memory capacity, especially the space allocated for the KV cache, still restrict the number of requests that can be processed in parallel. The KV cache memory dynamically changes during the decoding process, while traditional methods often pre-allocate a contiguous block of memory based on maximum sequence length, making this approach often inefficient.
To overcome this challenge, vLLM has proposed an innovative PagedAttention scheme. This scheme divides the KV cache into multiple non-contiguous memory blocks, each capable of storing a fixed number of tokens corresponding to K and V information. Through this approach, PagedAttention significantly improves batch size and overall throughput.
The inspiration for PagedAttention comes from operating systems’ solutions for memory fragmentation management and virtual memory paging concepts. It views the KV cache of requests as multiple pages, with each page containing a certain number of token information, similar to memory pages in operating systems. This design allows KV cache blocks to be stored in non-contiguous memory spaces, facilitating more flexible memory management.
In PagedAttention, we can draw on the virtual memory management strategies of operating systems, treating blocks as pages, tokens as bytes, and requests as processes. The scheduler can dynamically allocate and manage these pages based on actual needs in each iteration, ensuring sufficient space for each request without compromising performance.
KV cache management is a highly focused research area, and in addition to PagedAttention, many alternative mechanisms have been proposed. For instance, SpecInfer effectively eliminates KV cache redundancy allocation between multiple output sequences with the same prefix by introducing tree attention and depth-first tree traversal. Meanwhile, LightLLM adopts a more refined token-level memory management mechanism to further reduce memory usage and improve overall performance.

Optimizing LLM services is a complex and necessary process that requires a comprehensive approach to enhance performance. In recent years, many research teams have been dedicated to developing efficient software frameworks aimed at providing exceptional LLM inference deployment services.
These advanced systems generally support tensor parallelism, enabling multi-GPU collaboration, thereby significantly enhancing overall system performance. Additionally, they implement iterative-level scheduling strategies to ensure efficient resource utilization and improved responsiveness.
A typical architecture of an inference framework is illustrated in the diagram below, consisting of two main components: the engine and the server. The engine plays a crucial role, handling all transactions related to the model, KV cache management, and batch request processing, ensuring that the model can perform inference efficiently and accurately. The server is responsible for receiving and forwarding HTTP/gRPC requests from users; it not only serves as a bridge between users and the model but also plays an important role in coordinating and managing requests.
It’s worth mentioning that the server also provides key metrics such as throughput and latency, which are essential for tracking and evaluating model service performance, helping us to promptly identify potential issues and optimize accordingly.
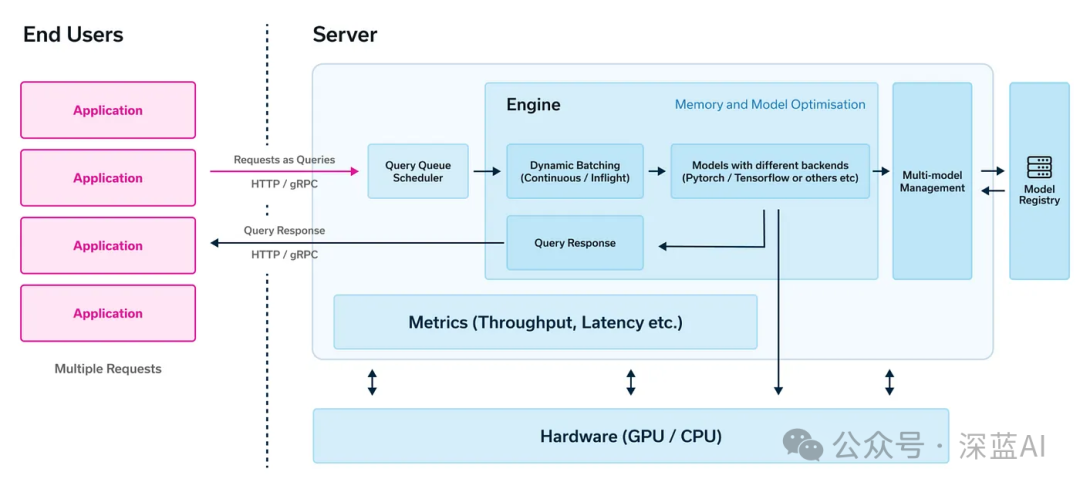
▲Figure 5|Classic Inference Software Framework ©️【Deep Blue AI】Translation
The functionalities of these systems are diverse, including but not limited to support for multiple programming languages (such as C++ and Python) and the ability to handle different precision formats (such as FP16 and INT8). Furthermore, they support various hardware platforms and models to meet application needs in different scenarios. In short, the design and implementation choices of these systems are closely aligned with their core optimization goals, aiming for lower latency (𝐿𝑎𝑡) and higher throughput (𝑇𝑝𝑡). The following table compares various GPU-based open-source LLM service systems.
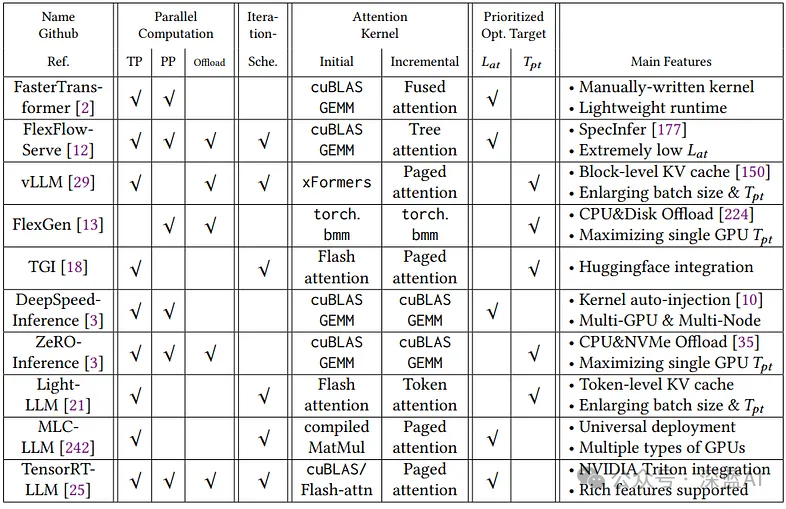
▲Figure 6|Comparison of State-of-the-Art GPU-Based Open Source LLM Service Systems ©️【Deep Blue AI】Translation

Establishing a comprehensive and reproducible benchmark is crucial for objectively comparing the performance of various LLM service systems. This benchmark not only provides LLM users with a strong basis for decision-making, helping them choose the system solutions that best meet their needs, but also promotes the healthy development of the entire LLM service industry. However, there is currently a lack of a comprehensive benchmark that considers various influencing factors. This is primarily due to the complexity and diversity of evaluation setups, which involve model configurations, hardware environments, request loads, and more. Testing under a limited number of setup combinations often fails to yield comprehensive and reliable conclusions.
Nevertheless, we can still glean valuable information from benchmark tests under specific setups. For example, Run.ai recently released a benchmarking study that delves into the performance of different model service frameworks concerning the critical performance metric of throughput. This study thoroughly evaluated inference engines such as TensorRT-LLM and vLLM, as well as inference servers like RayLLM with RayServe, TGI, and TensorRT-LLM + Triton.
Anyscale also published their benchmark results on throughput and latency. They experimentally compared the performance of continuous batching and static batching under simulated real-world real-time inference workloads. Additionally, they compared the benchmark results of existing batching systems, such as HuggingFace’s text generation, NVIDIA’s FasterTransformer, and vLLM.
These benchmark efforts undoubtedly provide valuable insights for practitioners in the intelligent language field, helping them make more informed choices in project decisions. At the same time, we look forward to more comprehensive and objective benchmark studies emerging in the future to drive the continuous progress and development of the LLM service industry.
https://pages.run.ai/hubfs/PDFs/Serving-Large-Language-Models-Run-ai-Benchmarking-Study.pdf
https://medium.com/@javaid.nabi/efficient-generative-large-language-model-serving-1c22b58f3c92
https://medium.com/@javaid.nabi/efficient-generative-large-language-model-serving-1c22b58f3c92

UCLA’s Latest Work: 3DGS Reconstruction from a Sparse Perspective Combined with Diffusion Models
2024-04-23

The Most Powerful Open Source Model on Earth: Mistral
2024-04-22
【Deep Blue AI】is continuously recruiting authors. We welcome anyone who wants to transform their scientific and technical experiences into writing to share with more readers! If you’re interested in joining, please click the post below for more details👇
The Deep Blue Academy Author Team is strongly recruiting! We look forward to your joining.
*Click to view, save, and recommend this article*