

Source: AI Technology Review
This article contains over 10,000 words, and it is recommended to read it in about 20 minutes.
In this article, author Zhang Junlin uses vivid language to compare the features of the three major feature extractors in natural language processing (CNN/RNN/TF).
At the turn of the year, everyone is busy reviewing the achievements of the past year (or counting pots in tears by the stove), and making plans for 2019. Of course, some friends with high execution and work efficiency can directly copy the plans made at the beginning of 2018, completing the planning for 2019 in just 3 seconds, congratulations to them.
From an economic perspective, 2018 was a tough year for everyone, but for the field of natural language processing, 2018 was undoubtedly a fruitful year. If one technological advancement had to be chosen, it would undoubtedly be the Bert model. In the previous article introducing Bert, titled “From Word Embedding to Bert Model—The Evolution of Pre-training Techniques in NLP,” I boldly claimed the following two personal judgments: one is that the two-stage model of Bert (pre-training + fine-tuning) will undoubtedly become a popular method in NLP research and industrial applications;
https://zhuanlan.zhihu.com/p/49271699
the second is that in terms of feature extractors in the NLP field, Transformer will gradually replace RNN to become the most mainstream feature extractor. Regarding the judgments on feature extractors, the previous article only provided a conclusion due to space constraints and did not give compelling explanations. Those who have read my articles know that I do not make conclusions lightly, but why did I reach this conclusion at that time? This article can be seen as an elaboration of the previous one, providing detailed evidence to support the conclusion previously given.
If I were to make a macro judgment about the future trends of the three major feature extractors in NLP, my judgment is as follows: RNN has become outdated, having basically completed its historical mission, and will gradually exit the historical stage; CNN, if properly modified, still has hope to hold a place in the NLP field. If the degree of modification exceeds expectations, there is a slim chance that it could survive and thrive as a local warlord, but I believe this hope is slim, comparable to the probability of Song Xiaobao crying after playing basketball against Yao Ming; and the new darling, Transformer, will obviously quickly become the most mainstream feature extractor in NLP.
As for whether new feature extractors will emerge in the future to dethrone Transformer, this concern is quite necessary. After all, Li Shangyin warned us a thousand years ago:
“The emperor’s grace flows east like water, those favored worry about losing favor. Do not play the flowers before the wine, the cool breeze only blows in the west of the palace.” This poem seems particularly fitting for RNN at present. As for whether Transformer will lose favor in the future, the answer to this question can basically be affirmative; it is just a matter of whether this moment will arrive in three years or one year.
Of course, I hope that if you are reading this article, or if I am, on a future day, we could pull an ordinary-looking lady from the street, send her to Korea for plastic surgery, and accidentally deviate from the industrial template of beauty, creating a stunning beauty who could send Transformer into obscurity. That would be the best. However, in the current state, even with a telescope, it seems that there are no candidates with such qualifications appearing in our sight.
I know that if a rigorous researcher were to make such seemingly hasty conclusions in the current unclear situation, it might spark controversy. But this is indeed my real thought at the moment, as for the basis of the above judgments? Is there sufficient evidence? Is the evidence adequate? I believe that after reading this article, you will have your own conclusion.
At this point, some students who are used to being picky might question: why do you say that the typical feature extractors in NLP are only these three? What about other well-known feature extractors like Recursive NN? Well, many articles introducing important advancements in NLP even consider Recursive NN a major advancement in NLP, along with others like Memory Network enjoying this level of honor. However, I have never been optimistic about these two technologies, and I have not been for many years. The current situation has further solidified this view. Moreover, I advise you for free, there is no need to waste time on these two technologies, as to why, it is unrelated to the theme of this article and I will discuss it in detail later when there is an opportunity.
The above is the conclusion, and below we formally enter the evidential phase.
Battlefield Reconnaissance: Characteristics and Types of NLP Tasks

The characteristics of NLP tasks are vastly different from those in the image domain. The above image shows an example; the input for NLP is often a sentence or a piece of text, so it has several characteristics:
-
First, the input is a one-dimensional linear sequence, which is easy to understand;
-
Secondly, the input is of variable length, with some being long and others short, which can add some minor complications for the model to handle;
-
Thirdly, the relative positional relationships of words or phrases are very important; swapping the positions of two words can lead to completely different meanings.
If I were to say to you: “You don’t need to pay back the ten million you owe me” versus “I don’t need to pay you back the ten million you owe me,” what would your feelings be upon hearing them? Understand the difference between the two; in addition, the long-distance features in the sentence are also crucial for understanding semantics. For example, refer to the words highlighted in red in the image above; whether the feature extractor can capture long-distance features is also critical for solving NLP tasks.
Please remember these characteristics; whether a feature extractor is suitable for the characteristics of the problem domain sometimes determines its success or failure. Many model improvement directions are actually about modifying them to better match the characteristics of the domain problem. This is why I first explain these contents before introducing feature extractors like RNN, CNN, and Transformer.
NLP is a broad field, encompassing dozens of subfields. Theoretically, anything related to language processing can fall under this scope. However, if we abstract a large number of NLP tasks, we find that the vast majority can be categorized into several major task types. Two seemingly different tasks may be solved by the same model.

Generally speaking, the vast majority of NLP problems can be categorized into the four types of tasks shown in the above image:
-
The first type is sequence labeling; this is the most typical NLP task, such as Chinese word segmentation, part-of-speech tagging, named entity recognition, semantic role labeling, etc., all of which fall under this category. Its characteristic is that each word in the sentence requires the model to provide a classification category based on the context.
-
The second type is classification tasks; common text classification and sentiment analysis fall under this category. Its characteristic is that regardless of how long the article is, a single classification category is provided overall.
-
The third type of task is sentence relationship judgment; tasks such as entailment, QA, semantic rewriting, and natural language inference all fall under this mode. Its characteristic is that given two sentences, the model judges whether they have a certain semantic relationship.
-
The fourth type is generative tasks; tasks such as machine translation, text summarization, poetry writing, and image captioning all belong to this category. Its characteristic is that after inputting text content, it needs to autonomously generate another segment of text.
To solve these different tasks, what is most important from the model’s perspective? It is the capability of the feature extractor. Especially since the popularity of deep learning, this point has become even more prominent. The greatest advantage of deep learning is end-to-end (end to end); of course, this does not refer to from client to cloud, but rather that previously researchers had to consider which features to extract, while in the end-to-end era, you can completely ignore this and throw the raw input to a good feature extractor, which will extract the useful features by itself.
As a seasoned bug creator and algorithm engineer, what you need to do now is: choose a good feature extractor, choose a good feature extractor, choose a good feature extractor, feed it a large amount of training data, set the optimization target (loss function), tell it what you want it to do… then you think you don’t need to do anything else and just wait for the results, right? Then you are the most optimistic person I have ever met in the universe… You actually spend a lot of time on hyperparameter tuning… From this process, it can be seen that if we have a powerful feature extractor, then intermediate and junior algorithm engineers becoming tuning experts is inevitable; in the era of AutoML (automated whatever), perhaps in the future you want to be a tuning expert but cannot, as Li Si said, “I want to go with you to chase the yellow dog and go out of the eastern gate of Shangcai to chase the fox, can it be done?” Please understand this. So please cherish the days when you are still adjusting hyperparameters at two o’clock in the morning, because for you, there is one good news and one bad news. The good news is: for you, this hard life may not last long! The bad news is: for you, this hard life may not last long!!! So how can you become an algorithm expert? You need to design a more powerful feature extractor.
Next, we will start discussing the three major feature extractors.
The Veteran RNN: Can the Old General Still Eat?
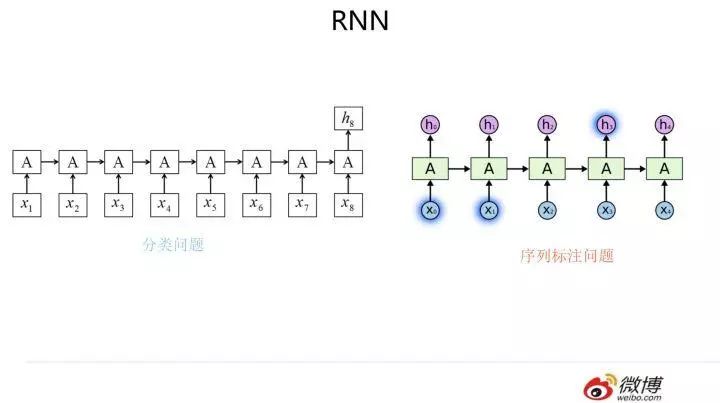
Everyone is probably familiar with the RNN model, so I won’t go into detail. The model structure is referenced in the image above; the core is that each input corresponds to a hidden layer node, and the hidden layer nodes form a linear sequence, with information gradually transmitted from front to back between the hidden layers. Let’s directly enter the content I want to discuss.
Why RNN Can Become the Mainstream Feature Extractor for Solving NLP Problems
We know that once RNN was introduced into the NLP field, it quickly became a star model that attracted attention and was widely used in various NLP tasks. However, the original RNN also had problems; it adopted a linear sequence structure to continuously collect input information from front to back, but this linear sequence structure faced optimization difficulties during backpropagation because the backpropagation path was too long, easily leading to severe gradient vanishing or exploding problems. To solve this problem, LSTM and GRU models were later introduced, which alleviated the gradient vanishing problem by adding intermediate state information to propagate backward, achieving good results. Thus, LSTM and GRU quickly became the standard models of RNN.
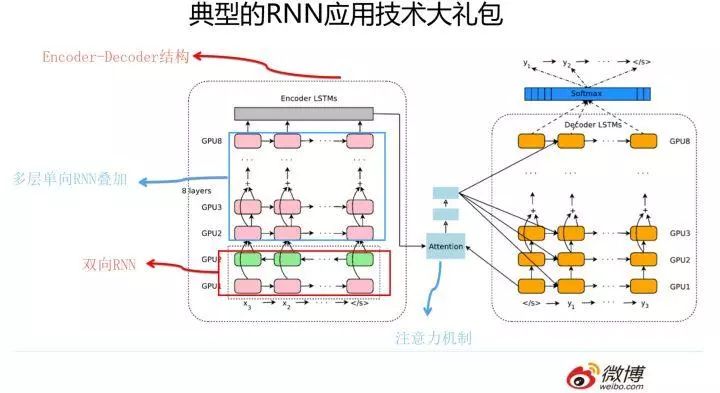
In fact, the original idea of skip connection that revolutionized models in the image domain, such as HighwayNet/ResNet, was borrowed from the hidden layer transmission mechanism of LSTM. Through continuous optimization, NLP borrowed and introduced the attention mechanism from the image domain; these technological advancements greatly expanded the capabilities and application effects of RNN. The model shown in the image below is a typical general framework technology package using RNN to solve NLP tasks, and you can see this technology package in various fields of NLP before newer technologies emerged.
The above content briefly introduces the general technological evolution process of RNN in the NLP field. So why has RNN quickly become popular in NLP and dominated the field? The main reason is that the structure of RNN is naturally suited to solving NLP problems. The input for NLP is often an indefinite-length linear sequence of sentences, while the RNN structure is a network structure that can accept indefinite-length inputs and transmit information linearly from front to back. Moreover, after LSTM introduced three gates, it was also very effective in capturing long-distance features. Therefore, RNN is particularly suitable for the linear sequence application scenario of NLP, which is the fundamental reason for its popularity in the NLP field.
Two Serious Problems Facing RNN in the New Era
RNN has been popular in the NLP field for many years (2014-2018?). Before 2018, the State of the Art results in most subfields were achieved by RNN. However, in the past year, it is evident that the leading position of RNN is being shaken; as the saying goes, every model has its peak for 3-5 years, and it seems that even internet celebrity models are no exception.
So what is the reason for this? There are mainly two reasons.
The first reason is the rise of some new models, such as specially modified CNN models and the recently popular Transformer, which currently has significant advantages over RNN in terms of application effects. This is a major reason; if the old cannot compete with the new and lacks the ability for self-revolution, it will naturally exit the historical stage, which is a natural law. As for the specific evidence of RNN’s weaker capabilities, this article will discuss later, so I won’t elaborate here. Of course, there are still a considerable number of RNN loyalists among technical personnel, and this group is unlikely to easily give up a once-popular star model, so they are thinking of or have thought of some improvement methods to extend RNN’s life. What these methods are and whether they are effective will be discussed later.
Another serious obstacle to RNN’s continued popularity is: RNN’s sequential dependency structure is quite unfriendly to large-scale parallel computing. Simply put, RNN has difficulty achieving efficient parallel computing capabilities. At first glance, this may not seem like a big problem, but it is actually quite serious. If you are only satisfied with publishing a paper by modifying RNN, this is indeed not a big problem. However, when it comes to technical selection in the industry, it is unlikely to choose a slow model when there are much faster models available. A model that lacks practical application to support its existence value will face a bleak future, and even a simple mind can deduce this answer.
So the question arises: why does RNN have poor parallel computing capabilities? What causes this?
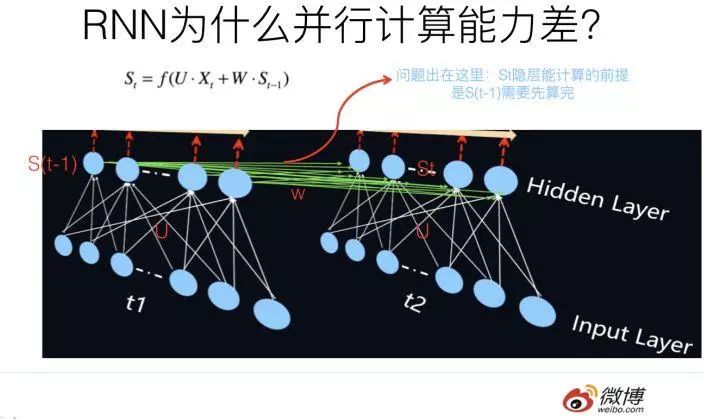
We know that the most typical feature that distinguishes RNN from other models is that the calculation of the hidden layer state at time T depends on two inputs: the input word Xt at time T (which is not a characteristic since all models must receive this raw input) and the key input, the hidden layer state St at time T also depends on the output of the hidden layer state S(t-1) at time T-1. This point is the most indicative of RNN’s essential characteristics; the historical information of RNN is transmitted through this information channel. As for why RNN’s parallel computing capability is poor, the problem lies here. The calculation at time T depends on the result of the calculation at time T-1, and the calculation at time T-1 depends on the result at time T-2… This forms a so-called sequential dependency relationship, meaning that the first time step must be completed before the second time step can be calculated, which makes it impossible for RNN to perform parallel calculations from this perspective; it can only move forward word by word according to the time steps.
In contrast, CNN and Transformer do not have this sequential dependency problem, so for them, parallel computing capability is not an issue; operations at each time step can be computed in parallel.
So can RNN be modified to enhance its parallel computing capabilities? If so, how effective would it be? Let’s discuss this issue.
How to Modify RNN to Achieve Parallel Computing Capability?
As mentioned above, RNN’s inability to perform parallel computing stems from the dependency of the calculation at time T on the result at time T-1, which is reflected in the fully connected network between hidden layers. Since the problem lies here, to solve it, we must address this aspect. What can be done in this aspect to increase RNN’s parallel computing capability? You can think about it.
Actually, you don’t have many options; you have two major ideas for improvement: one is to retain the hidden layer connections between any continuous time steps (from T-1 to T); the other is to partially break the connections between continuous time steps (from T-1 to T).
First, let’s look at the first method; our question has now transformed into: we still want to retain the hidden layer connections between any continuous time steps (from T-1 to T), but under this premise, we also want to achieve parallel computing. How to handle this? Because as long as we retain the hidden layer connection between two continuous time steps, it means that to calculate the hidden layer result at time T, we need to finish the hidden layer result at time T-1 first, which puts us back into the trap of sequential dependency, right? Yes, it does, but why must parallel computing occur between different time steps? No one says that RNN’s parallel computing must occur at different time steps; think about it, doesn’t the hidden layer also contain many neurons? So can we perform parallel computing among hidden layer neurons? If you still don’t understand what this means, please look at the image below.
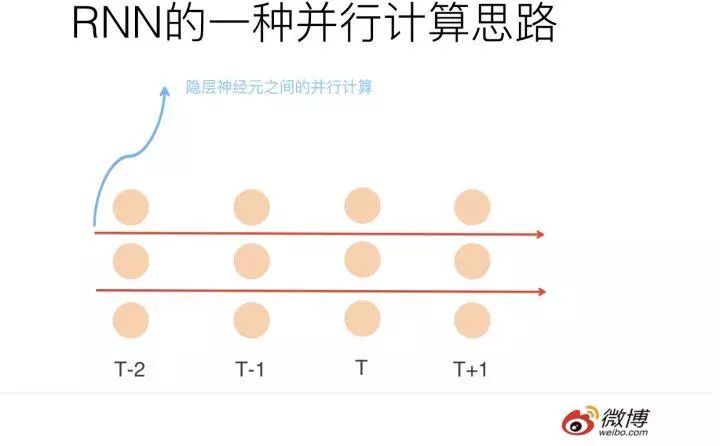
The above image only displays the hidden layer nodes at each time step, with each time step containing three neurons. This is a top-down view from above the hidden layer nodes of RNN. Additionally, the hidden layer neurons between two consecutive time steps still have connections, which are not shown in the image for simplicity. Now you should understand; if the hidden layer neurons have three, we can form three parallel computations (the red arrows separate them into three paths), and each path still has to compute sequentially due to the sequential dependency problem.
So the big idea should be clear, right? However, those familiar with RNN structure will find that this still leaves a problem: the connections between hidden layer neurons are fully connected, meaning that the hidden layer neuron at time T is connected to all hidden layer neurons at time T-1. If this is the case, it is impossible to perform parallel computing among the neurons. You can think about why this is simple; I assume you have the ability to figure it out. So what should we do? Very simple, the connection relationship between the hidden layer neurons at time T and T-1 needs to be modified; instead of being fully connected, we change it so that only the corresponding neurons (those shown in the image as separated by red arrows) are connected, while other neurons are not connected. This way, we can solve this problem, allowing for parallel computation among the hidden layer neurons.
The first method for modifying RNN to enhance parallel computing capability is roughly as described above; a representative of this method is the paper: Simple Recurrent Units for Highly Parallelizable Recurrence, which proposes the SRU method. Its essential improvement is to change the dependency of hidden layers from fully connected to Hadamard product, so that the hidden layer unit at time T, which originally depended on all hidden layer units at time T-1, now only depends on the corresponding unit at time T-1, allowing for parallel computation among hidden layer units while still collecting information according to the time sequence. Thus, its parallelism occurs among hidden layer units rather than between different time steps.
This is actually a rather clever method, but its limitation is that the upper limit of its parallelism is limited; the degree of parallelism depends on the number of hidden layer neurons, and this number is often not very large. Increasing parallelism further is already unlikely. Additionally, each parallel line still requires sequential computation, which will also slow down the overall speed. The testing speed of SRU was: comparable to the original CNN (Kim 2014) in text classification, but the paper did not mention whether CNN adopted parallel training methods. Other complex tasks like reading comprehension and MT tasks only provided effect evaluations without speed comparisons with CNN, which I suspect is for a reason, as complex tasks often require deep networks; I will not make further guesses.
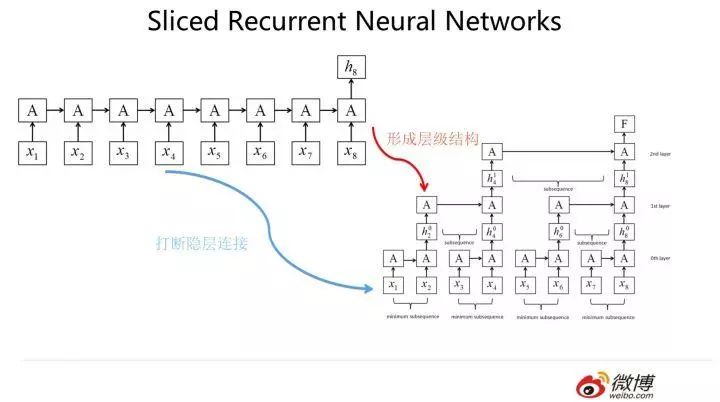
The second typical improvement idea is: to enable parallel computing between different time step inputs, the only approach is to break the connections between hidden layers, but not completely, because doing so would make it impossible to capture composite features. Therefore, the only strategy available is to partially break the connections, such as breaking them every two time steps, but how to capture features that are slightly farther away? This can only be done by increasing the depth of the network, establishing connections between far-distance features through depth. A representative model is the Sliced RNN shown in the image above. When I first saw this model, I couldn’t help but laugh like a barbell; I couldn’t help but walk up to greet it: Hello, CNN model, I never expected you, this rough guy, would one day wear a pink dress and appear before me as RNN, haha. Those who understand the CNN model will probably smile knowingly at my statement: isn’t this just a simplified version of CNN? Those who do not understand CNN are advised to read the subsequent CNN section before returning to see if this is the case.
So how is the speed improvement of RNN after this modification? The paper provides comparative speed experiments; in summary, the SRNN is 5 to 15 times faster than the GRU model, which is quite good. However, compared to the DC-CNN model, it is still about three times slower than CNN on average. This is quite normal, but also a bit hard to explain; it is normal because this is essentially transforming RNN into a structure similar to CNN, and the segments still adopt the RNN sequential model, so it is bound to slow down the speed. Being slower than CNN is only to be expected. The point that is “hard to explain” is: since it is essentially CNN and is slower than CNN, then what is the point of this modification? Isn’t it? The previous student who likes to nitpick because they rarely suffer losses might say: maybe its performance is particularly good. Well, from the mechanism of this structure, the likelihood is not very high. You might say that the experimental part of the paper proves this. I believe that the experimental part does not provide sufficient comparative tests; it needs to supplement comparisons with other CNN models besides DC-CNN. Of course, this is purely personal opinion, don’t take it seriously, because when I speak, I often shake my head, and at this time, someone usually surprises me with feedback, saying: why do I hear the sound of water when you speak?
The above lists two major ideas for improving RNN’s parallel computing capabilities. I personally hold a pessimistic attitude towards RNN’s parallel computing capabilities, mainly because RNN’s essential characteristics limit the choices we can make. It’s just a choice between breaking or not breaking the hidden layer connections. If we choose to break, we will face the aforementioned problem that it may no longer be an RNN model; to make it look like RNN, we still need to adopt RNN structure in the broken segments, which will undoubtedly slow down the speed, so it is a dilemma; rather than doing this, it is better to switch to another model. If we choose not to break, it seems that we can only perform parallel computation among hidden layer neurons, and this approach has the drawback of having a low upper limit on parallel capability; additionally, the existing sequential dependency will still be a problem. This is why I am pessimistic; mainly, I do not see great hope.
The Striker CNN: Surviving on the Battlefield
More than a year ago, CNN was the most common deep learning model in natural language processing besides RNN. Here, I will introduce the CNN feature extractor in more detail than RNN, mainly considering that everyone may not be as familiar with it as with RNN.
The Early Nostalgic CNN Model in NLP
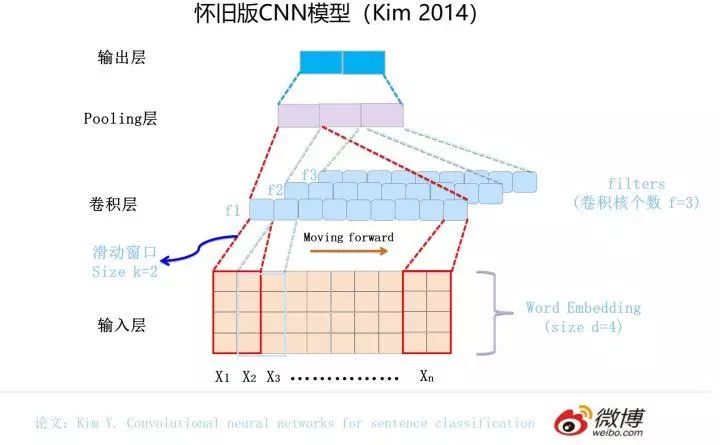
The first to introduce CNN into NLP was Kim in 2014, with the paper and network structure referenced in the image above. Generally, the input characters or words are expressed using Word Embedding, which converts the originally one-dimensional text information into a two-dimensional input structure. Assuming the input X contains n characters, and the length of each character’s Word Embedding is d, then the input is a d*n two-dimensional vector.
The convolutional layer is essentially a feature extraction layer, where a hyperparameter F can be set to specify how many convolutional kernels (Filters) the convolutional layer contains. For a certain Filter, you can imagine a d*k sized moving window starting from the first character of the input matrix and continuously moving backward, where k is the window size specified by the Filter, and d is the length of the Word Embedding. For a certain moment’s window, through the nonlinear transformation of the neural network, the input values within this window are converted into a feature value. As the window moves forward, the feature value corresponding to this Filter is continuously generated, forming the feature vector of this Filter. This is the process of feature extraction by convolutional kernels. Each Filter operates this way, creating different feature sequences. The pooling layer then performs dimensionality reduction on the Filter’s features to form the final features. Generally, a fully connected neural network is connected after the pooling layer to form the final classification process.
This is the working mechanism of the earliest CNN model applied in the NLP field to solve sentence classification tasks; it still looks quite simple. Subsequently, improved models based on this foundation appeared. These nostalgic CNN models can achieve results comparable to the nostalgic version of RNN in some tasks, allowing them to thrive in various fields of NLP, but in more NLP areas, they are still in an awkward situation of being suppressed by RNN models.
So why is CNN, which is invincible in the image domain, suppressed by RNN, a local snake in the NLP domain? This indicates that this version of CNN still has many problems; the fundamental issue is that the old revolutionaries face new problems, mainly not making targeted changes to the characteristics of the new environment, leading to the issue of not adapting to the new environment.
Can CNN survive in the various NLP task environments dominated by RNN? The answer is about to be revealed.
The Evolution of CNN: The Model Arena of Natural Selection
Next, let’s first look at the problems with the nostalgic version of CNN and then see how our NLP experts have modified CNN until it reaches the modern version that looks quite effective today.
First, we need to clarify one point: what features does CNN capture? From the operation mechanism of the nostalgic version of CNN’s convolutional layer described above, you can see that the key lies in the sliding window covered by the convolutional kernel. The features captured by CNN are basically reflected in this sliding window. A sliding window of size k gently traverses the words of the sentence, creating ripples; what does it capture? In fact, it captures the k-gram fragment information of words, and the size of k determines how far-reaching the captured features can be.
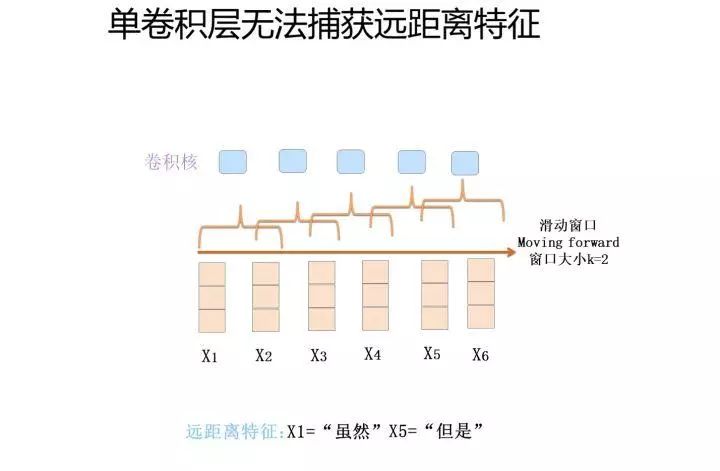
Now, let’s look at the first problem with Kim’s version of CNN: it has only one convolutional layer. At first glance, this seems to be a depth issue, right? I would ask you: why should we deepen CNN? In fact, deepening is a means, not an end. Having only one convolutional layer leads to the problem that long-distance features cannot be captured; if the sliding window size k is at most 2, and there is a long-distance feature with a distance of 5, then no matter how many convolution kernels are used, it cannot cover the input of length 5, so it cannot capture long-distance features.
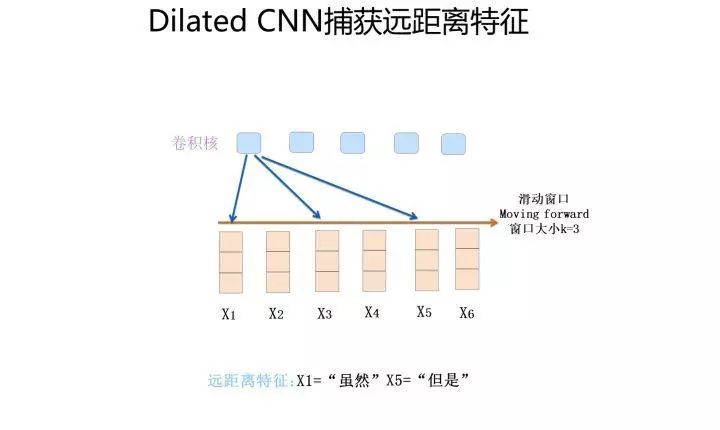
So how can we capture long-distance features? There are two typical improvement methods: one is to assume we still use a single convolutional layer with a sliding window size k set to 3, which only receives three input words, but we want to capture features with a distance of 5; how can we achieve that? Obviously, if the convolution kernel window still covers a continuous area, it will definitely not accomplish the task. Hint: have you played Jumping Game? Can we use a similar strategy? Yes, you can skip to cover, right? This is the basic idea of dilated convolution, and indeed it is one solution.
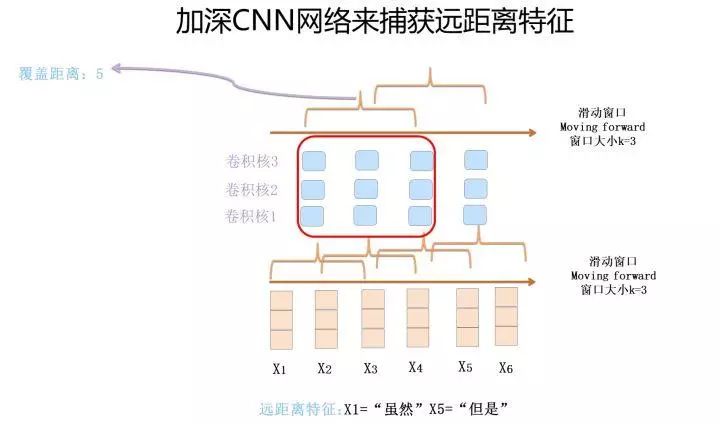
The second method is to increase the depth. In the first convolutional layer, assuming the sliding window size k is 3, if we stack another convolutional layer on top, also with a sliding window size of 3, the second layer’s window covers the output features of the first layer, so it can actually cover a distance of 5 in the input. If we continue to stack convolutional layers, we can continue to increase the length of the convolutional kernel’s coverage of the input.
The above are two typical solutions to CNN’s ability to capture long-distance features. Dilated CNN is a bit more technical, and when increasing the depth of the network, there are some tricks to how hyperparameters should be set, as continuous skipping may miss some feature combinations, so careful parameter tuning is required to ensure that all possible combinations are covered.
Relatively speaking, increasing the depth of CNN is the mainstream development direction. This principle is easy to understand; since the emergence of CNN, people have been trying various methods to deepen CNN, but reality is often ruthless, and it is found that no matter how it is manipulated, CNN cannot be deepened for NLP problems; it can only manage to stack 2 to 3 layers of convolutional layers. Increasing the depth of the network does not significantly help the task (please do not use CharCNN as a counterexample, as later studies have shown that using a two-layer CNN with words outperforms CharCNN). Currently, it seems that the issue lies in insufficient parameter optimization methods for deep networks rather than the depth itself being ineffective. Later, with the emergence of new technologies in the image domain, such as ResNet, it was natural for people to consider introducing skip connections and various normalization techniques to gradually deepen the CNN network.
The above discusses the first issue with Kim’s version of CNN, the inability to capture long-distance features, and the main solutions proposed by researchers afterward. Looking back, Kim’s version of CNN has another problem, which is related to whether CNN can maintain the positional information of the input sentences. First, I want to ask a question: RNN naturally encodes positional information due to its linear sequence structure; can CNN retain the relative positional information of the original input? We mentioned earlier that positional information is very useful for NLP problems.
In fact, the convolution kernel of CNN can retain the relative position of features; the reasoning is simple: the sliding window slides from left to right, and the captured features are arranged in the same order, so it has already recorded the relative positional information in its structure. However, if the convolutional layer is immediately followed by a pooling layer, the logic of the max pooling operation is: it selects and retains only the strongest feature from a feature vector obtained from a convolutional kernel, so the positional information is discarded at the pooling layer, which leads to information loss in NLP. Therefore, one trend in CNN’s development in the NLP field is to discard the pooling layer and rely on fully convolutional layers to increase network depth; there are reasons behind this (of course, this trend also exists in the image domain).
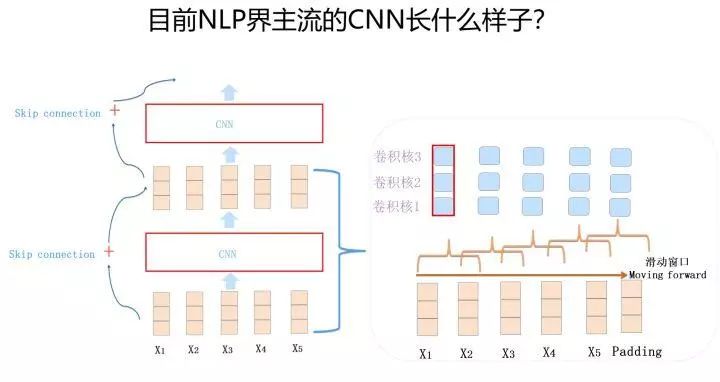
The above image shows the main structure of the modern CNN that can perform in the NLP field, typically consisting of 1-D convolutional layers to increase depth, using skip connections for optimization assistance, and possibly introducing dilated CNN techniques. For example, the main structure of ConvS2S is depicted in the image above, where the encoder contains 15 convolutional layers, and the convolution kernel size is 3, covering an input length of 25. Of course, for ConvS2S, the introduction of GLU gating nonlinear functions in the convolution kernels is also very helpful; due to space constraints, I will not elaborate on this here. GLU seems to be an essential component in CNN models for NLP that is worth mastering. Another example is TCN (paper: An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling), which integrates several techniques: using dilated CNN to expand the input coverage length of a single convolutional layer, stacking fully convolutional layers to increase depth, using skip connections for optimization, and introducing causal CNN to ensure that the network structure does not see data from T time steps later.
However, TCN’s experiments have two obvious issues: one is that the tasks other than the language model are not typical NLP tasks but synthetic data tasks, so the paper’s conclusion cannot directly claim to be suitable for the NLP field; the other is that the comparative methods used for effectiveness evaluation did not use models that performed well at the time, resulting in a low comparison benchmark. Therefore, the effectiveness of TCN’s model is not very convincing. In fact, it has basically introduced the elements it should have, but the experimental persuasiveness is lacking; I think it may be due to its lack of GLU.
In addition, let me briefly discuss the position encoding issue and parallel computing capability issue of CNN. As mentioned above, the convolutional layer of CNN can indeed retain relative positional information, as long as you do not randomly insert pooling layers in the middle of the model design, the issue should not be significant; it is also common practice to add position embeddings to each word and overlay them with word vector embeddings to form the word input.
As for CNN’s parallel computing capability, it is very strong, which is easy to understand. If we consider a single convolutional layer, first, for a certain convolution kernel, there are no dependencies between each sliding window position, so it can be computed in parallel; additionally, there is no mutual influence between different convolution kernels, so they can also be computed in parallel. The parallelism of CNN is very free and high, which is a significant advantage of CNN.
The above content describes how the nostalgic version of CNN has evolved step by step to survive in the NLP battlefield. If I were to summarize the evolution direction of CNN in one sentence, it would be: finding ways to increase the depth of CNN; as the depth increases, many seemingly unrelated problems will be solved. It is like the main theme of our country in the past 40 years has been economic development; when the economy develops well, many problems are no longer problems. The reason why everyone feels various difficulties in recent years is that the economy is not doing well, so many problems cannot be solved through economic development, leading to various difficulties emerging; this is the principle.
Now that we have introduced so much, how does the modern CNN perform compared to RNN and Transformer? Don’t worry; this issue will be discussed later.
The White Knight Transformer: The Hero Stands on Stage

Transformer was proposed by Google in the paper “Attention is All You Need” in 2017 for machine translation tasks, which caused quite a stir. Every colleague engaged in NLP development should thoroughly understand Transformer; its importance is beyond doubt, especially after you read this article, I believe your sense of urgency will become more pressing; I am indeed skilled at creating anxiety. However, I do not intend to focus on introducing it here; those who want to get started with Transformer can refer to the following three articles:
The first is Jay Alammar’s blog post, which visually introduces Transformer, titled “The Illustrated Transformer,” which is very easy to understand the entire mechanism. It is recommended to start with this article:
Chinese translation version
https://zhuanlan.zhihu.com/p/54356280
The second article is Calvo’s blog:
Dissecting BERT Part 1: The Encoder
https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3
Although it is said to analyze Bert, since Bert’s Encoder is Transformer, it is actually analyzing Transformer, and the examples given are excellent; then you can advance further by referring to the Harvard NLP research group’s “The Annotated Transformer.”
http://nlp.seas.harvard.edu/2018/04/03/attention.html
Both code and principles are thoroughly explained.
Below, I will only discuss content related to the theme of this article.
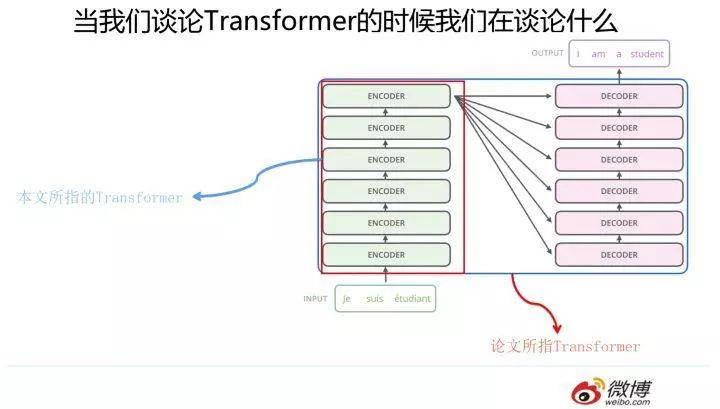
Here, I want to clarify that the Transformer feature extractor referred to in this article is not what the original paper indicates. We know that the Attention is All You Need paper refers to the complete Encoder-Decoder framework, while here I am discussing it from the perspective of a feature extractor; you can simply understand it as the Encoder part of the paper. This is because the purpose of the Encoder part is relatively straightforward: to extract features from the original sentences, while the Decoder part has relatively more functions, including feature extraction, language modeling, and translation model functions expressed through the attention mechanism. Therefore, please note this to avoid confusion in understanding subsequent concepts.
The Encoder part of Transformer (not the modules marked as encoder in the image above, but the overall part within the red box; the image comes from The Illustrated Transformer, where Jay Alammar refers to each Block as Encoder, which does not conform to conventional naming) is made up of several identical Transformer Blocks stacked together. This Transformer Block is actually the most critical part of Transformer, and the core recipe is here. So what does it look like?
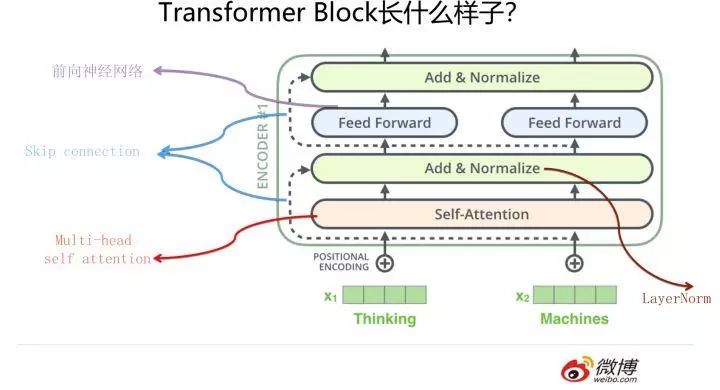
Its photo is shown in the image above; doesn’t it look cute, a bit like an Android robot? Here, I need to emphasize that although the original Transformer paper focuses on Self Attention, the elements in this Block that make Transformer effective are not limited to Self Attention; all elements, including Multi-head Self Attention, Skip Connection, LayerNorm, and FF, work together. Why do I say this? You will understand this point later.
Let’s discuss how Transformer addresses the characteristics of NLP tasks.
First, natural language is generally an indefinite-length sentence; how does Transformer handle this indefinite length issue? The approach taken by Transformer is similar to CNN; it generally sets a maximum length for the input, and if the sentence is not that long, it is padded, making the entire model input appear at least of fixed length.
Additionally, the relative positions of words in NLP sentences contain a lot of information. As mentioned earlier, RNN naturally encodes positional information due to its structure; CNN’s convolutional layers also retain relative positional information, so doing nothing is not a big issue. However, for Transformer, to retain the relative positional information of the input sentence’s words, something must be done.
Why must it do something? Because the first layer of the input network is the Multi-head Self Attention layer; we know that Self Attention allows the current input word to relate to any word in the sentence and integrate into an embedding vector, but once all information reaches the embedding, the positional information has not been encoded. Therefore, unlike RNN or CNN, it is essential for Transformer to explicitly encode position information at the input end. Transformer uses a position function for position encoding, while models like Bert give each word a Position embedding, combining the word embedding with the corresponding position embedding to form the word input embedding, similar to the approach described in ConvS2S.
Regarding the long-distance dependency features in NLP sentences, Self Attention can naturally solve this issue because when integrating information, the current word relates to any word in the sentence, so it completes this task in one step. Unlike RNN, which needs to propagate through hidden layer nodes, or CNN, which needs to increase network depth to capture long-distance features, the solution of Transformer in this regard is evidently simpler and more intuitive. I mention these points to specifically introduce how Transformer addresses several key points in NLP tasks.
Transformer has two versions: Transformer Base and Transformer Big. Their structures are essentially the same; the main difference is the number of Transformer Blocks included. Transformer Base contains 12 stacked Blocks, while Transformer Big doubles that, containing 24 Blocks. Undoubtedly, Transformer Big has double the network depth, parameter count, and computational load compared to Transformer Base, making it a relatively heavy model, but it also achieves the best results.
Paper Notes BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Understanding the BERT Model)
https://ai.yanxishe.com/page/blogDetail/9925
Author: Zhang Junlin, a director of the Chinese Society for Chinese Information Processing, PhD from the Institute of Software, Chinese Academy of Sciences, currently a senior algorithm expert at Weibo AI Lab. Before this, Zhang Junlin worked as a senior technical expert at Alibaba, leading a new technology team, and has held positions as a technical manager and technical director at Baidu and Yonyou. He is also the author of the technical books “This is Search Engine: Detailed Explanation of Core Technologies” (which won the 12th National Excellent Book Award) and “Big Data Daily Knowledge: Architecture and Algorithms.”
This article was first published on Zhihu: https://zhuanlan.zhihu.com/p/54743941
Editor: Wang Jing
Proofreader: Lü Yanqin

