
Source: Heart of Autonomous Driving
Editor: Deep Blue Academy
Original Transformer Detector
DETR (ECCV2020)
The pioneering work! DETR! Code link: https://github.com/facebookresearch/detr
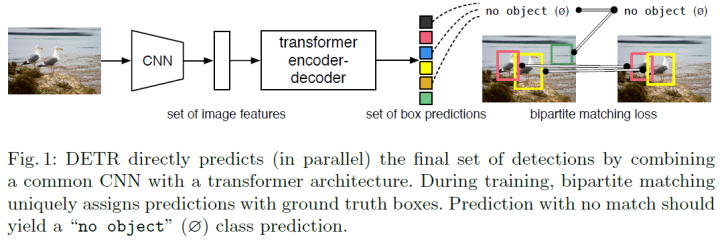
The paper proposes a novel approach that views object detection as a direct set prediction problem. DETR simplifies the detection process and effectively eliminates the need for many manually designed components, such as NMS or anchor generation. The main component of the new framework, called the DEtection TRansformer or DETR, is a set-based global loss that enforces one-to-one predictions through bipartite matching, as well as a transformer encoder-decoder architecture.
Given a fixed set of learned object queries, DETR analyzes the relationships between the objects and the global image context to directly and simultaneously output the final set of predictions. Unlike many other detectors, the new model concept is simple and does not require specialized libraries.
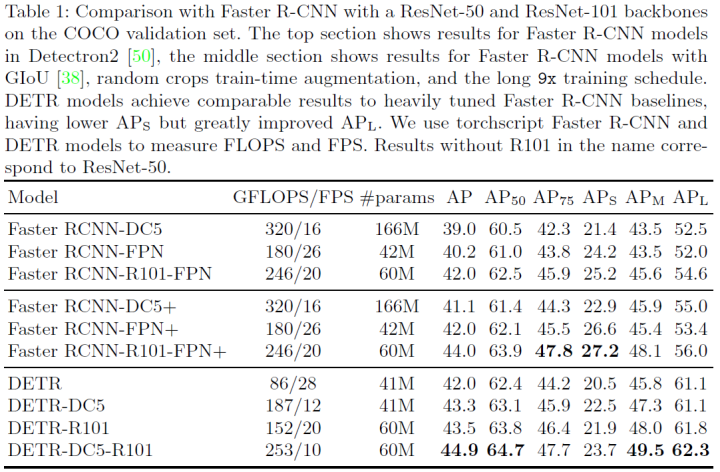
DETR demonstrates accuracy and runtime comparable to the mature and highly optimized Faster RCNN baseline on the challenging COCO object detection dataset. Furthermore, DETR can easily be extended to output panoptic segmentation in a unified manner.
The network structure of DETR is shown in the figure below, which illustrates that DETR consists of four main modules: backbone, encoder, decoder, and prediction head. The backbone network is a classic CNN that outputs features downsampled by a factor of 32.
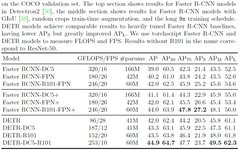
The experimental results are shown below. The performance is quite good, but the training is too slow, taking 300 epochs.
DETR also demonstrates panoptic segmentation results on COCO, showing that instance discrimination capability is still quite limited, especially for the Bus in the middle.

Pix2seq (Google Hinton)
Code link: https://github.com/google-research/pix2seq
In summary: A simple and general new framework for object detection that transforms object detection into a language modeling task, greatly simplifying the pipeline, with performance comparable to Faster R-CNN and DETR! It can also be extended to other tasks.
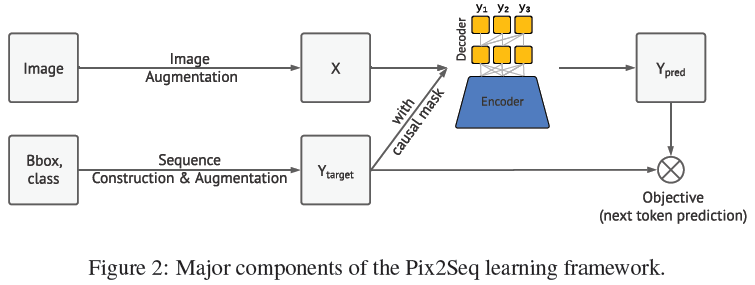
The paper proposes Pix2Seq, a simple and general object detection framework! Unlike existing methods that explicitly integrate prior knowledge about the task, Pix2seq treats object detection as a language modeling task based on observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are represented as discrete tokens, training a neural network to perceive images and generate the desired sequences.
Pix2seq is primarily based on the intuition that if the neural network knows the location and content of the objects, we only need to teach it how to read them out. Besides using task-specific data augmentation, Pix2seq makes minimal assumptions about the task, yet achieves competitive results on the challenging COCO dataset compared to highly specialized and optimized detection algorithms.
The network mainly consists of four components:
-
Image augmentation: As commonly seen in training computer vision models, the paper uses image augmentation to enrich a fixed set of training examples (e.g., using random scaling and cropping); -
Sequence construction and augmentation: Since object annotations in images are typically represented as a set of bounding boxes and class labels, the paper converts them into a series of discrete tokens; -
Architecture: An encoder-decoder model is used, where the encoder perceives pixel inputs, and the decoder generates the target sequences (one token at a time); -
Objective/loss function: The model is trained to maximize the log-likelihood of tokens based on the image and previous tokens (using softmax cross-entropy loss).
Sequence construction illustration:

Trained for 300 epochs, experimental results:
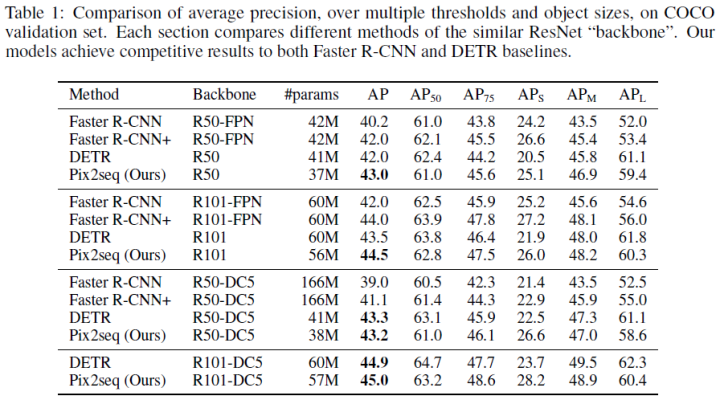
Sparse Attention
Deformable DETR (ICLR 2021)
Code link: https://github.com/fundamentalvision/Deformable-DETR
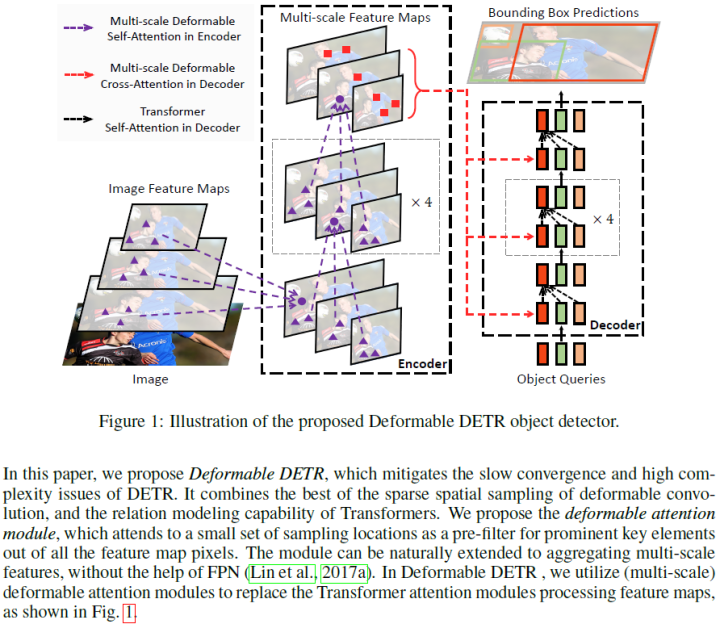
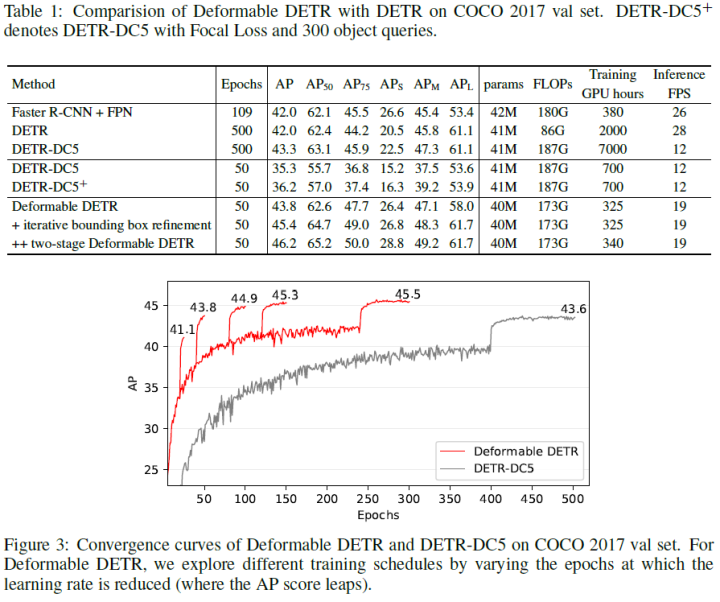
Recently, DETR was proposed to eliminate the need for many manually designed components in object detection while proving good performance. However, due to the limitations of the Transformer attention module when processing image feature maps, it suffers from slow convergence and limited feature space resolution. To alleviate these issues, the paper proposes Deformable DETR, whose attention module focuses only on a small set of key sampling points around the reference. Deformable DETR can achieve better performance than DETR (especially on small objects) and reduces training time by 10 times. Extensive experiments on the COCO benchmark demonstrate the effectiveness of the algorithm.
– Issues with DETR
-
Long training cycles, 10-20 times slower than Faster R-CNN! -
Poor performance on small objects! Typically uses multi-scale features to resolve small objects; however, high-resolution feature maps significantly increase DETR’s complexity!
– Reasons for the above issues
-
At initialization, the attention model has almost uniform weights for all pixels on the feature map (i.e., the contribution graph of one query multiplied by all keys is relatively uniform; ideally, the query should be highly correlated with a sparse set of keys), thus requiring a long time to learn better attention maps; -
Handling high-resolution features incurs excessive computational load and storage complexity;
– Motivation
-
To avoid uniform distribution of initialized weights in the encoder, i.e., instead of calculating similarity with all keys, compute similarity with more meaningful keys; deformable convolution is an effective way to focus on sparse spatial localization; -
The paper proposes deformable DETR, integrating sparse spatial sampling of deformable convolution with the transformer correlation modeling capability across the overall feature map pixels, allowing the model to focus on small sampled locations as pre-filters, serving as keys.
Experimental Results
End-to-End Object Detection with Adaptive Clustering Transformer (Peking University & Hong Kong Chinese University)
Code link: https://github.com/gaopengcuhk/SMCA-DETR/
DETR uses Transformers for object detection and achieves performance similar to two-stage detectors like Faster R-CNN. However, due to high-resolution spatial inputs, DETR requires substantial computational resources for training and inference. This paper proposes a new variant of Transformer—the Adaptive Clustering Transformer (ACT)—to reduce the computational cost of high-resolution inputs.
ACT uses Locality Sensitive Hashing (LSH) to adaptively cluster query features and employs prototype-key interactions to approximate query-key interactions. ACT can reduce the quadratic complexity of self-attention within the model to O(N), where K is the number of prototypes per layer. ACT can be an embedded module, replacing the original self-attention module without any training. ACT achieves a good balance between accuracy and computational cost (FLOP).
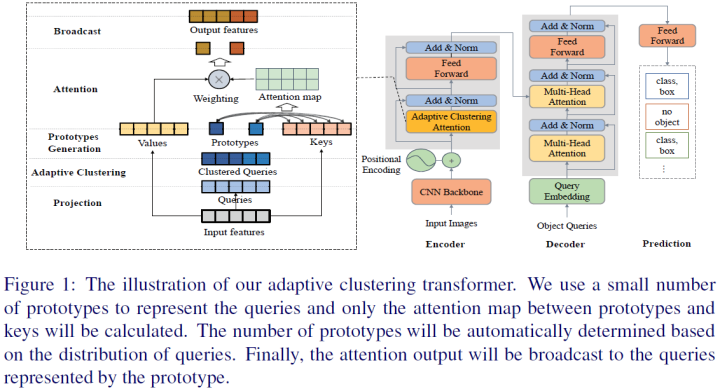
The main contributions of this paper are as follows:
-
Developed a new method called Adaptive Clustering Transformer (ACT) that can reduce the inference cost of DETR. ACT can lower the quadratic complexity of the original Transformer while being fully compatible with it; -
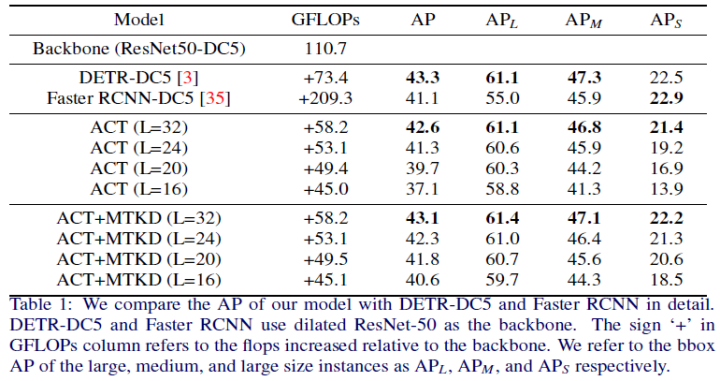
Reduced the FLOPS of DETR from 73.4 Gflops to 58.2 Gflops (excluding backbone ResNet FLOPS) without any training process, with only a 0.7% loss in AP; -
Further reduced the loss in AP to 0.2% through multi-task knowledge distillation (MTKD), achieving seamless switching between ACT and the original Transformer.
The experimental results are as follows:
PnP-DETR (ICCV 2021)
Paper link: GitHub – twangnh/pnp-detr: Implementation of ICCV21 paper: PnP-DETR: Towards Efficient Visual Analysis with Transformers
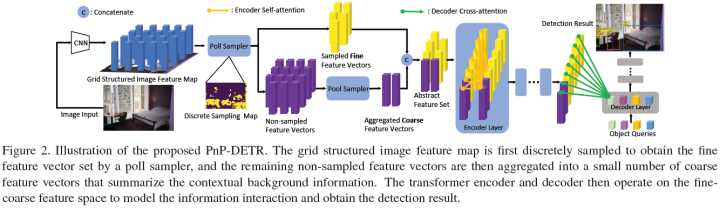
Although DETR is effective, the redundant computation in certain areas (e.g., background) can be costly. In this work, the paper encapsulates the idea of reducing spatial redundancy within a new poll and pool (PnP) sampling module, utilizing this module to construct an end-to-end PnP DETR architecture that adaptively allocates its computation spatially to improve efficiency.
Specifically, the PnP module abstracts image feature maps into fine foreground object feature vectors and a small number of coarse background context feature vectors. The Transformer models the information interaction within the fine-coarse feature space and transforms features into detection results. Furthermore, by changing the sampling feature length, the PnP-enhanced model can immediately achieve various expected trade-offs between performance and computation within a single model without needing to train multiple models as in existing methods.
Thus, it provides greater flexibility for deployment in different scenarios with varying computational constraints. The paper further validates the generalization of the PnP module on panoptic segmentation and recent Transformer-based image recognition models like ViT, showing consistent efficiency gains. The paper believes that PnP-DETR takes a step towards effective visual analysis using Transformers, where spatial redundancy is typically observed.
The main contributions of this paper are as follows:
-
Analyzed the spatial redundancy of image feature maps in the DETR model, which leads to excessive computational load in the transformer network. Thus, proposed to abstract the feature maps to significantly reduce the model’s computational load; -
Designed a novel two-step polling and pooling sampling module to extract features. The algorithm first uses a poll sampler to extract fine foreground feature vectors, then uses a pool sampler to obtain coarse context feature vectors; -
Constructed PnP-DETR, which operates on the abstract fine-coarse feature space and adaptively distributes computation across the spatial domain. By changing the length of the fine feature set, the PnP-DETR algorithm achieves higher efficiency, enabling immediate computation and performance trade-offs within a single model. -
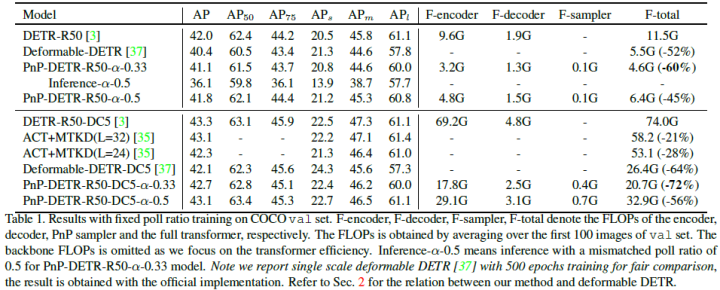
The PnP sampling module is universal and is end-to-end learnable without explicit supervision like RPN. The paper further validated it on panoptic segmentation and recent ViT models, showing consistent efficiency gains. This approach provides useful insights for future research on effective solutions for vision tasks using transformers. The experimental results are as follows:
Sparse DETR (ICLR 2022)
Code link: https://github.com/kakaobrain/sparse-detr
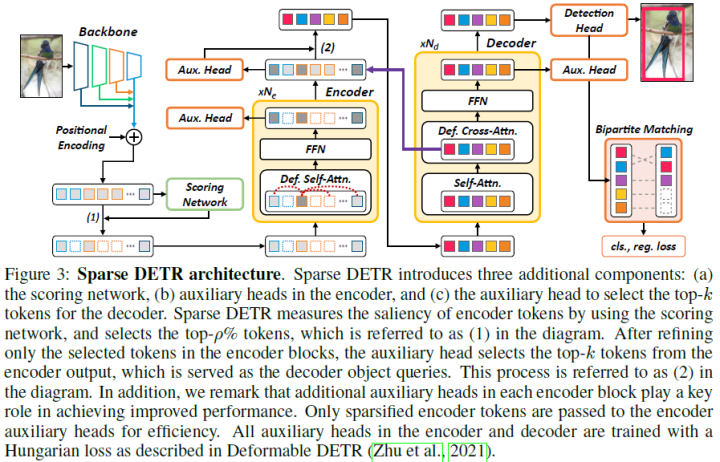
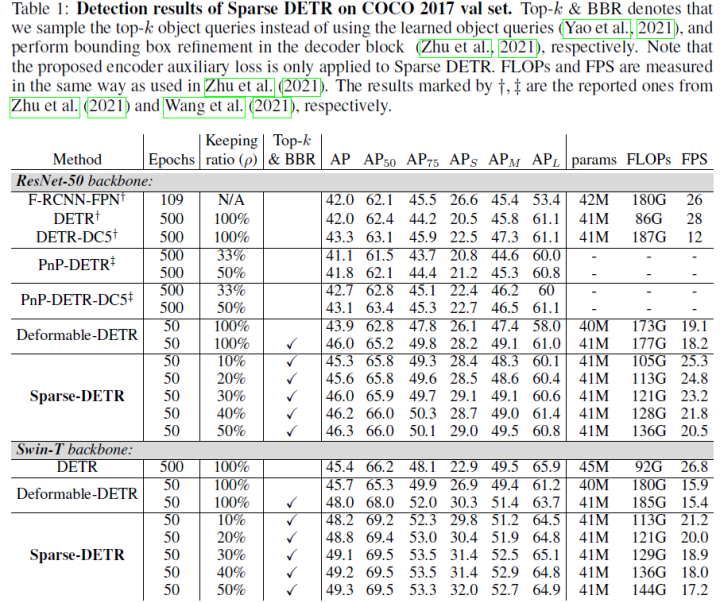
Deformable DETR uses multi-scale features to improve performance; however, compared to DETR, the number of encoder tokens increases by 20 times, and the computational cost of encoder attention remains a bottleneck. In preliminary experiments of this paper, it was found that even updating only a portion of the encoder tokens does not significantly degrade detection performance. Motivated by this observation, the paper proposes Sparse DETR, which selectively updates only the tokens expected to be referenced by the decoder, thereby assisting the model in effectively detecting objects.
Moreover, applying auxiliary detection loss to the selected tokens in the encoder can enhance performance while minimizing computational overhead. This paper validates that Sparse DETR outperforms Deformable DETR even with only 10% of encoder tokens on the COCO dataset. Although only the encoder tokens are sparsified, the total computational cost is reduced by 38%, and the FPS increases by 42% compared to Deformable DETR.
The main contributions of this paper are as follows:
-
Proposed an encoder token sparsification method for an effective end-to-end object detector, alleviating the attention complexity in the encoder. This efficiency allows stacking more encoder layers than Deformable DETR, thus improving performance under the same computational load; -
Introduced two new sparsification criteria to sample a subset of information from the entire token set: Objectness Score (OS) and Decoder cross-Attention Map (DAM). Based on the decoder cross-attention map criterion, the sparse model maintains detection performance even when using only 10% of the entire tokens; -
Applied auxiliary loss only to the selected tokens in the encoder. This additional loss not only stabilizes the learning process but also significantly improves performance with only a slight increase in training time.
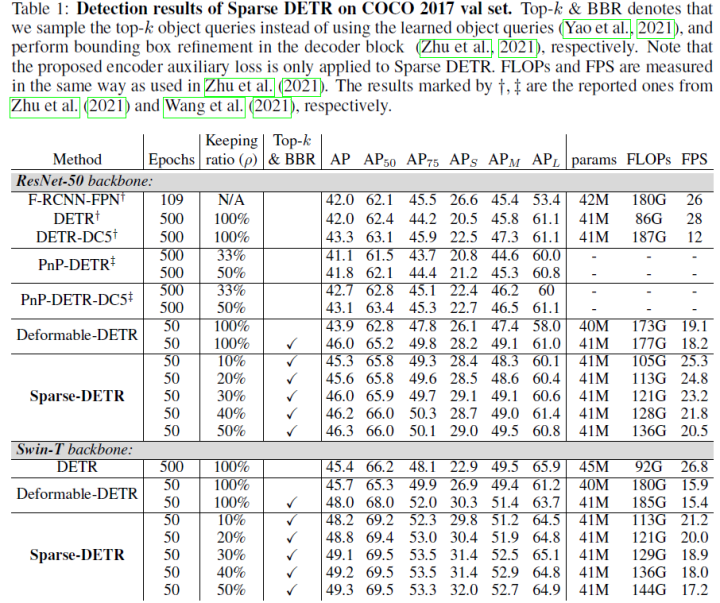
Experimental results are shown below:
Spatial Priors
Fast Convergence of DETR with Spatially Modulated Co-Attention (ICCV 2021)
DETR’s convergence speed is slow. Training DETR from scratch requires 500 epochs to achieve high accuracy. To accelerate its convergence, this paper proposes a simple yet effective scheme to improve the DETR framework, namely the Spatially Modulated Co-Attention (SMCA) mechanism. The core idea of SMCA is to perform regression-aware co-attention in DETR by constraining the co-attention response to higher regions near the initially estimated bounding box locations.
The proposed SMCA enhances the convergence speed of DETR by replacing the original co-attention in the decoder while keeping other operations in DETR unchanged. Additionally, by integrating multi-head and scale-selection attention designs into SMCA, the proposed SMCA can achieve better performance compared to DETR with a dilated convolution backbone. The paper conducts extensive ablation studies on the COCO dataset to validate the effectiveness of the proposed SMCA.
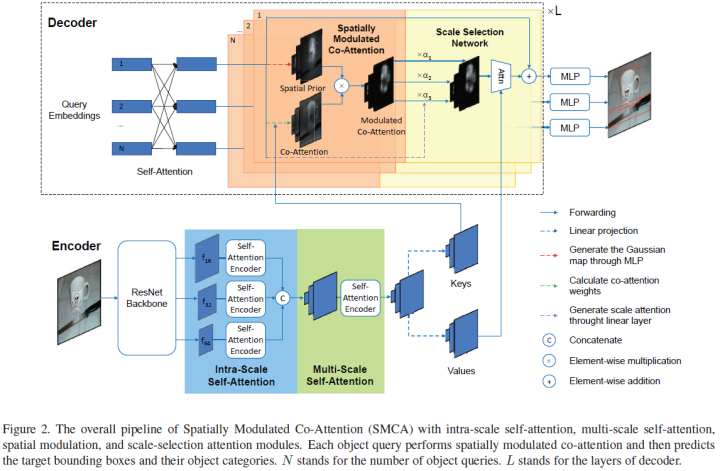
Main contributions are as follows:
-
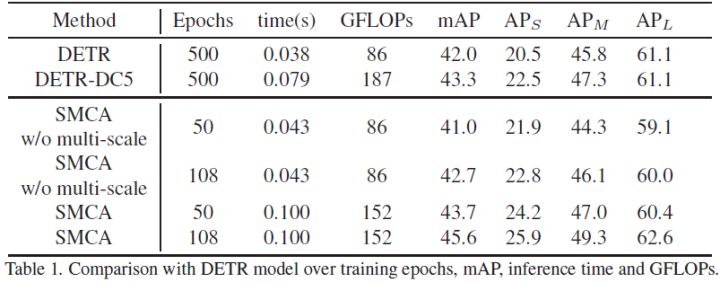
Proposed a new Spatially Modulated Co-Attention (SMCA) that can accelerate the convergence of DETR by performing position-constrained target regression. SMCA is a plug-and-play module in the original DETR. The basic version of SMCA without multi-scale features and multi-head attention can achieve 41.0 mAP in 50 epochs and 42.7 mAP in 108 epochs. Training the basic version of SMCA for 50 epochs requires 265 V100 GPU hours. -
The complete SMCA further integrates multi-scale features and multi-head spatial modulation, which can significantly improve and surpass DETR with fewer training iterations. The complete SMCA can achieve 43.7 mAP in 50 epochs and 45.6 mAP in 108 epochs, while DETR-DC5 achieves 43.3 mAP in 500 epochs. Training the complete SMCA for 50 epochs requires 600 V100 GPU hours. -
Conducted extensive ablation studies on the COCO 2017 dataset to validate the proposed SMCA module and network design.
Motivation
To accelerate DETR’s convergence, this paper proposes dynamically predicting a 2D spatial Gaussian weight map to multiply with co-attention feature maps to achieve faster convergence. It is a plug-and-play solution that significantly enhances DETR’s performance. It outperforms deformable DETR and DETR networks.
Experimental results are shown below:
Conditional DETR (ICCV 2021)
This paper addresses the key issue of slow training convergence in DETR by proposing a conditional cross-attention mechanism for rapid DETR training. The motivation is that the cross-attention in DETR heavily relies on content embeddings to locate and predict boxes, which increases the demand for high-quality content embeddings, thus complicating training.
The method proposed in this paper is called Conditional DETR, which learns conditional spatial queries from decoder embeddings for the decoder’s multi-head cross-attention. The benefit is that, through conditional spatial queries, each cross-attention head can focus on bands containing different regions, such as an object endpoint or an area within the object box. This narrows the spatial range used for locating object classifications and box regressions, thereby relaxing the dependence on content embeddings and simplifying training. Experimental results show that for backbones R50 and R101, Conditional DETR converges 6.7 times faster, and for stronger backbones DC5-R50 and DC5-R101, it converges 10 times faster.
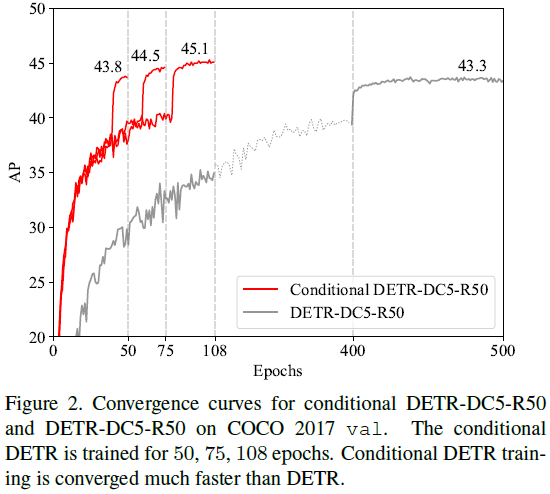
Motivation
To analyze why DETR converges slowly, the paper visualizes the spatial attention maps in the DETR decoder’s cross-attention.

Each head’s spatial attention map attempts to find an extremity area of the object. The paper argues that in computing cross-attention in DETR, the content embedding in the query must match both the content embedding in the key and the spatial embedding in the key, which places high demands on the quality of content embeddings. After training DETR for 50 epochs, the quality of the content embeddings is not high enough to accurately narrow the search range for the object, leading to slow convergence. In summary, the reason for DETR’s slow convergence is that DETR heavily relies on high-quality content embeddings to locate the extremity areas of objects, which are crucial for locating and recognizing objects.
Based on this, the paper proposes Conditional DETR!
Experimental results are shown below:
Anchor DETR (AAAI 2022)
Code link: https://github.com/megvii-research/AnchorDETR
This paper proposes a new query mechanism for object detection based on Transformers. In previous Transformer-based detectors, object queries are a set of learned embeddings. However, each learned embedding lacks explicit physical significance, and we cannot explain where it will focus. Since the prediction slot of each object query does not have a specific pattern, it is challenging to optimize. In other words, each object query does not focus on a specific region.
To address these issues, the query design in this paper is based on anchor points, which are widely used in CNN-based detectors. Therefore, each object query focuses on targets near the anchor. Additionally, the query design in this paper allows predicting multiple targets at one location to solve the challenge of “one area, multiple targets.” Furthermore, the paper designs a variant of attention that can reduce memory costs while achieving performance similar to or better than the standard attention in DETR. Due to the query design and attention variant, this method is named Anchor DETR, which achieves better performance than DETR and runs faster.

Reviewing CNN-based detectors, anchors are highly correlated with locations and contain interpretable significance. Inspired by this, the authors propose a query design based on anchor points, encoding anchor points as target queries. The queries are encoded coordinates of the anchor points, thus each target query has explicit physical significance.
However, this solution has one limitation: multiple targets may appear at one location. In this case, a single query at that location cannot predict multiple targets, so queries from other locations must collaboratively predict these targets. This leads to each target query being responsible for a larger area. Therefore, the authors improve the target query design by adding multiple patterns (i.e., one anchor can detect multiple targets) for each anchor, allowing each anchor to predict multiple targets.
Besides the query design, the authors also design an attention variant—Row-Column Decouple Attention (RCDA). It decouples the two-dimensional key features into one-dimensional row features and one-dimensional column features, then performs row attention and column attention sequentially. RCDA can reduce computational costs while achieving performance similar to or even better than the standard attention in DETR.
Experimental results are shown below:
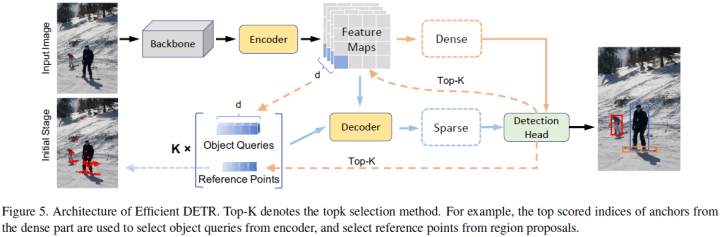
Efficient DETR (Megvii)
DETR and Deformable DETR have a cascaded structure with 6 stacked decoder layers to iteratively update object queries; otherwise, their performance would significantly decline. This paper studies the random initialization of target containers (including object queries and reference points), which mainly accounts for the necessity of multiple iterations. Based on the findings of the paper, Efficient DETR is proposed, a simple and efficient pipeline for end-to-end object detection.
By utilizing dense detection and sparse set detection, Efficient DETR uses dense priors before initializing target containers and eliminates the gap between a single decoder structure and a six-decoder structure. Experiments conducted on MS COCO show that the method in this paper achieves competitive performance with only 3 encoder layers and 1 decoder layer compared to state-of-the-art object detection methods. Efficient DETR is also robust in crowded scenes, significantly outperforming contemporaneous detectors on the CrowdHuman dataset.
The experimental results are as follows:

Dynamic DETR (ICCV 2021)
This paper proposes a new Dynamic DETR method that introduces dynamic attention into both the encoder and decoder stages of DETR to break its two limitations regarding small feature resolution and slow training convergence. To address the first limitation, which is due to the quadratic computational complexity of the self-attention module in the Transformer encoder, the paper proposes a dynamic encoder that approximates the attention mechanism of the Transformer encoder using convolution-based dynamic encoders with various attention types. This encoder can dynamically adjust attention based on multiple factors such as scale importance, spatial importance, and representation (i.e., feature dimension) importance.
To alleviate the second limitation regarding learning difficulty, the paper introduces a dynamic decoder that replaces the cross-attention module in the Transformer decoder with ROI-based dynamic attention. This decoder effectively helps the Transformer focus on ROIs in a coarse-to-fine manner, significantly reducing learning difficulty, thereby achieving faster convergence. The paper conducts a series of experiments to demonstrate the advantages of this approach. Dynamic DETR significantly shortens training time (reducing it by 14 times) while performing much better (mAP improvement of 3.6).
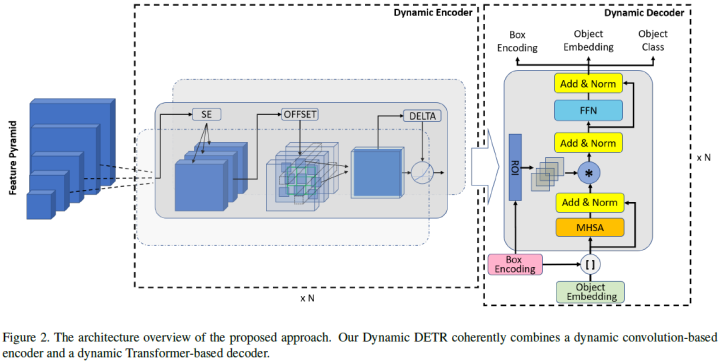
The main contributions of this paper are as follows:
-
Proposed a new Dynamic DETR method that coherently combines a dynamic convolution-based encoder with a dynamic Transformer-based decoder. This method significantly enhances the representation capability and learning efficiency of the object detection head without any computational overhead. -
Compared to the original DETR, Dynamic DETR greatly reduces training time (by 14 times) while significantly improving performance (3.6 mAP), as shown in the figure; -
It is the first end-to-end method to achieve superior performance to traditional methods in the standard 1x setting using a ResNet-50 backbone, achieving 42.9 mAP.
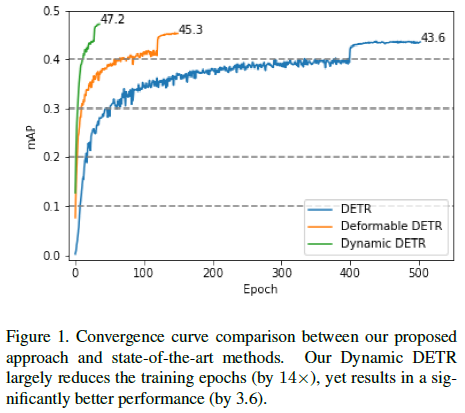
The experimental results are shown below:
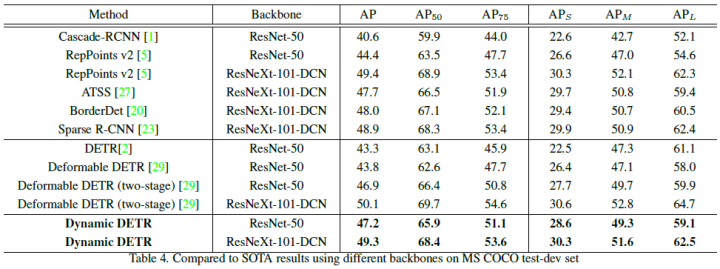
Structural Redesign
Rethinking Transformer-based Set Prediction for Object Detection (ICCV 2021)
Code link: GitHub: Let’s build from here Edward-Sun/TSP-Detection
DETR is a recently proposed Transformer-based method that treats object detection as a set prediction problem and achieves state-of-the-art performance but requires additional training time to converge. This paper investigates the reasons for optimization difficulties in DETR training, revealing several factors that lead to its slow convergence, primarily the Hungarian loss and the issues with co-attention in the Transformer.
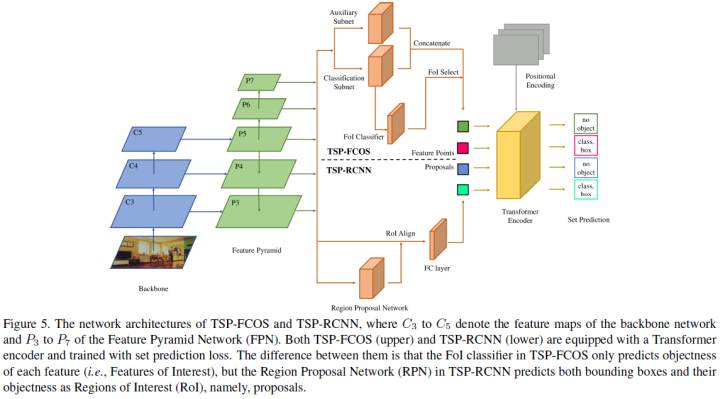
To overcome these issues, this paper proposes two solutions: TSP-FCOS (Transformer-based set prediction using FCOS) and TSP-RCNN (Transformer-based set prediction using RCNN). Experimental results show that the proposed methods not only converge faster than the original DETR but also significantly outperform DETR and other baselines in detection accuracy.
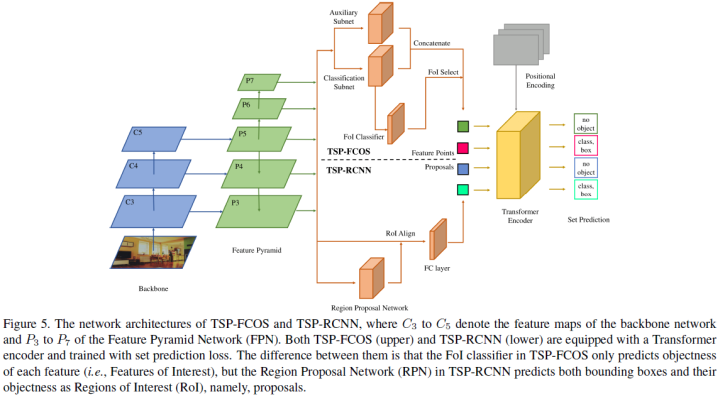
-
TSP-FCOS: Added a head between the backbone and encoder; -
TSP-RCNN: Added RoIAlign between the backbone and encoder;
The experimental results are shown below:
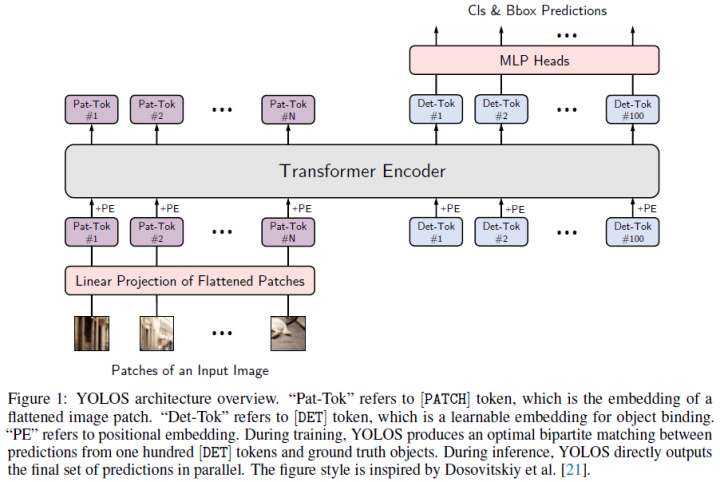
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection (NeurIPS 2021)
Code link: GitHub – hustvl/YOLOS: You Only Look at One Sequence (NeurIPS 2021)
Can Transformers perform 2D object and region-level recognition from a pure sequence-to-sequence perspective with minimal understanding of 2D spatial structure? To answer this question, the paper proposes “You Only Look at One Sequence” (YOLOS), a series of object detection models based on naive visual Transformers with minimal modifications, area priorities, and inductive biases for the target task.
The paper finds that only YOLOS pre-trained on the medium-sized ImageNet-1k dataset can achieve competitive performance on the COCO object detection benchmark, for example, directly adopting the BERT-Base architecture of YOLOS-Base can achieve 42.0 box AP on COCO. The paper also discusses the impact and limitations of current pre-training schemes and scaling strategies for Transformer models through YOLOS.
The main contributions of this paper are as follows:
-
Used the medium-sized ImageNet-1k as the only pre-training dataset and demonstrated that it can successfully transfer to ordinary ViT to perform complex object detection tasks, yielding competitive results on the COCO benchmark with minimal modifications (i.e., only looking at one sequence (YOLOS)); -
First demonstrated that 2D object detection can be accomplished in a pure sequence-to-sequence manner by using fixed-size, non-overlapping image patch sequences as input. In existing object detectors, YOLOS utilizes minimal 2D inductive biases. -
For naive ViT, the paper finds that object detection results are highly sensitive to pre-training schemes, and detection performance is far from saturated. Therefore, the proposed YOLOS can also serve as a challenging benchmark task to evaluate different (label-supervised and self-supervised) ViT pre-training strategies.
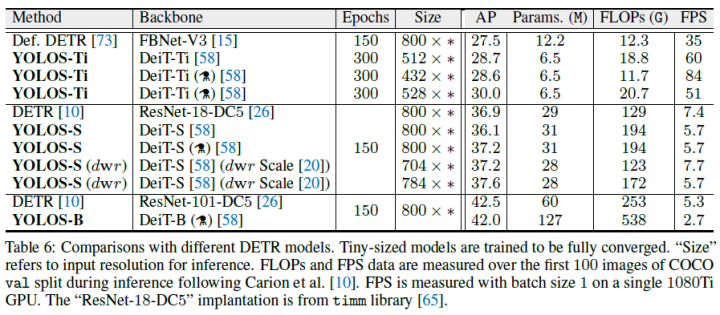
The experimental results are shown below:
Matching Optimization
DN-DETR (CVPR 2022)
Code link: https://github.com/FengLi-ust/DN-DETR
This paper proposes a new denoising training method to accelerate the training of DETR (DEtection TRansformer) and deepens the understanding of the slow convergence issue in DETR-like methods. The paper argues that slow convergence is caused by the instability of bipartite matching, leading to inconsistent optimization objectives in the early training stages. To address this issue, in addition to the Hungarian loss, the paper inputs noisy GT boxes into the Transformer decoder and trains the model to reconstruct the original boxes, effectively reducing the difficulty of bipartite matching and allowing for faster convergence.
This method is general and can be easily integrated into any DETR-like method with just a few lines of code to achieve significant improvements. Thus, DN-DETR produces significant improvements (+1.9AP) under the same settings. Compared to the baseline under the same settings, DN-DETR achieves comparable performance within 50% of the training time.
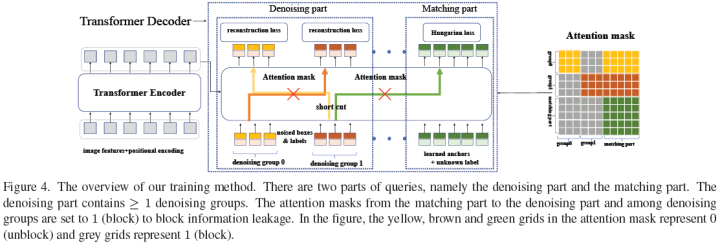
The main contributions of this paper are as follows:
-
Designed a new training method to accelerate DETR training. Experimental results show that our method not only speeds up training convergence but also results in significantly better training outcomes—achieving the best results among all detection algorithms in a 12-epoch setting. Furthermore, our method shows significant improvements (+1.9AP) over the baseline DN-DETR and can be easily integrated into other DETR-like methods; -
Analyzed the slow convergence of DETR from a new perspective and gained deeper insights into DETR training. Designed a metric to evaluate the instability of bipartite matching and validated that our method can effectively reduce instability; -
Conducted a series of ablation studies to analyze the effectiveness of different components in our model, such as noise, label embedding, and attention mask.
The experimental results are shown below:
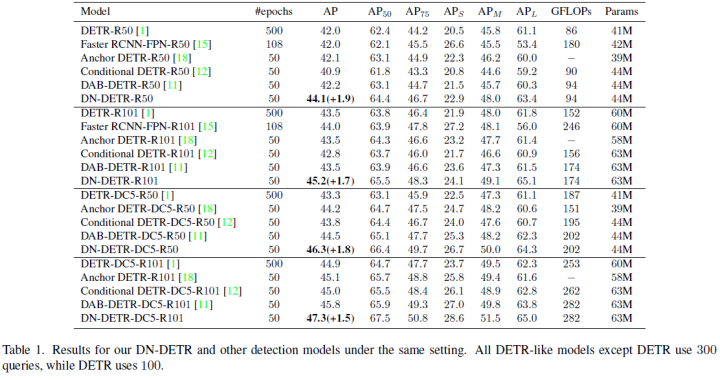
DINO
Code link: https://github.com/IDEACVR/DINO
This paper proposes DINO, an advanced end-to-end object detector. DINO improves upon previous DETR-like models in performance and efficiency through the use of a contrastive denoising training method, an anchor initialization hybrid query selection method, and a look forward twice scheme for box prediction. DINO achieves 49.4 AP in 12 epochs and 51.3 AP in 24 epochs on COCO with a ResNet-50 backbone and multi-scale features, significantly outperforming the previous best DETR-like model DN-DETR by +6.0 AP and +2.7 AP, respectively. DINO exhibits excellent scalability in terms of model size and data size.
Without any trick, DINO achieves the best results on the COCO val 2017 (63.2AP) and test set (63.3AP) after pre-training on the Objects365 dataset with a SwinL backbone. Compared to other models on the leaderboard, DINO significantly reduces its model size and pre-training data size while achieving better results.
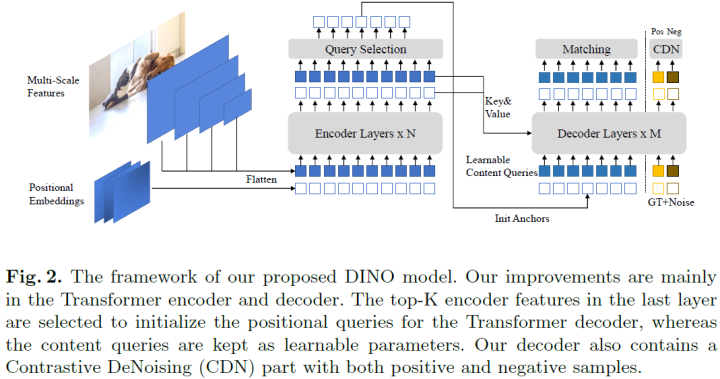
The main contributions of this paper are as follows:
-
Designed a new end-to-end object detector based on DETR that incorporates several new techniques, including contrastive DN training, hybrid query selection, and a two-time forward pass for different parts of the DINO model. -
Conducted in-depth ablation studies to validate the effectiveness of different design choices in DINO. Consequently, DINO achieves 49.4 AP in 12 epochs and 51.3 AP in 24 epochs with ResNet-50 and multi-scale features, significantly outperforming the previous best DETR-like model. Notably, DINO shows more significant improvements for small objects, increasing by +7.5 AP. -
Without any trick, DINO achieves the best scores on public benchmarks. After pre-training on the Objects365 dataset with a SwinL backbone, DINO achieves the best results on the COCO val2017 (63.2AP) and test set (63.3AP) benchmarks. To our knowledge, this is the first end-to-end Transformer detector to surpass the state-of-the-art (SOTA) models on the COCO leaderboard.
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。