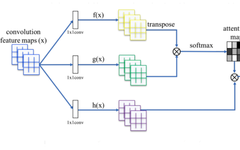
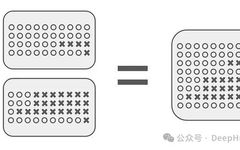
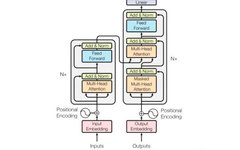
Understanding the Mathematical Principles of Transformers
Author:Fareed Khan Translator: Zhao Jiankai,Proofreader: Zhao Ruxuan The transformer architecture may seem intimidating, and you may have seen various explanations on YouTube or blogs. However, in my blog, I will clarify its principles by providing a comprehensive mathematical example. By doing so, I hope to simplify the understanding of the transformer architecture. Let’s get started! … Read more