Click the above“Beginner’s Guide to Vision” to choose star mark or pin.
Important content delivered promptly
This article is reproduced from:Machine Heart | Contributors: Yiming, Du Wei, Jamin
Author:Chaitanya Joshi
What is the relationship between Transformers and GNNs? It may not be obvious at first. However, through this article, you will view the architecture of Transformers from the perspective of GNNs, gaining a clearer understanding of the principles.
Some engineers might ask this question: Graph deep learning sounds good, but are there any successful commercial cases? Has it been used in practical applications?
Aside from recommendation systems in companies like Pinterest, Alibaba, and Twitter, the Transformer has actually achieved commercial success, greatly changing the NLP industry.
Through this blog post, Chaitanya Joshi, now an assistant researcher at Nanyang Technological University, will introduce readers to the intrinsic connections between graph neural networks and Transformers.Specifically, the author first introduces the basic principles of model architecture in NLP and GNN, using formulas and images to make connections, and then discusses how to promote progress in this area.

This article’s author, Chaitanya Joshi, assistant researcher at Nanyang Technological University.
This article provides a good explanation of the concept that “Transformers are graph neural networks”.
First, we start with representation learning.
Representation Learning in NLP
From a high-level perspective, all neural network architectures represent input data—in the form of vectors or embedding matrices.This approach encodes useful statistical or semantic information.These hidden representations can be used for useful tasks such as image classification or sentence translation.Neural networks build better representations through feedback (i.e., loss function).
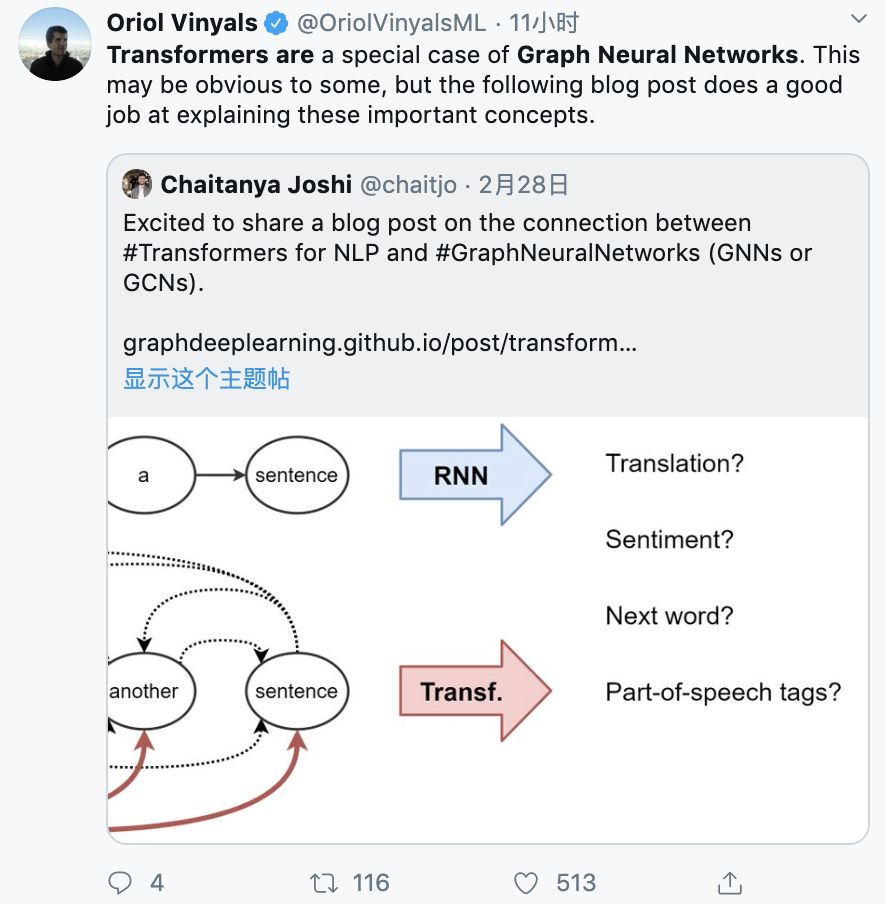
For NLP, traditionally, RNNs create a representation for each word—using a sequential manner.For example, one word per time step.Intuitively, we can imagine an RNN layer as a conveyor belt.Words are processed from left to right in an autoregressive manner.At the end, we can obtain the hidden features for each word in the sentence, which can then be input into the next RNN layer or used in tasks.
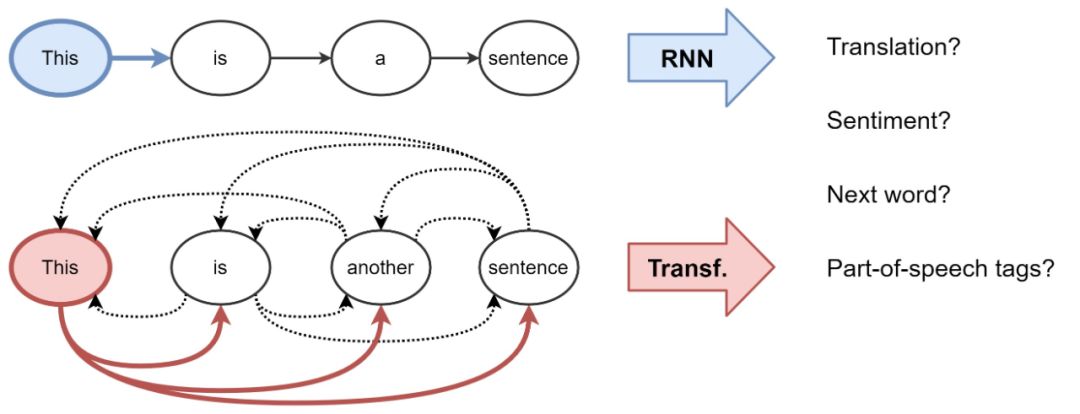
Starting from machine translation, Transformers gradually began to replace RNNs.This model has a new representation learning strategy.It no longer uses recursion; instead, it uses attention mechanisms to build representations for each word—i.e., the importance of each word in the sentence.Knowing this, the feature update for a word is the weighted sum of linear transformations of all words, based on their importance.
By translating the previous paragraph into mathematical symbols and vectors, we can create an understanding of the entire architecture.Updating the hidden feature h of the i-th word in the long sentence S from layer ℓ to layer ℓ+1:
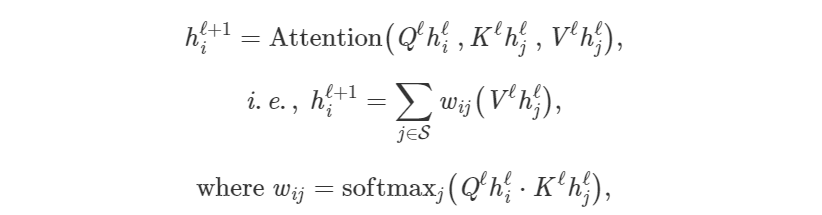
Where j∈S is the set of words in the sentence, Q^ℓ, K^ℓ, V^ℓ are learnable linear weights (representing Query, Key, and Value for attention computation, respectively).The attention mechanism is executed in parallel for each word in the sentence, thus obtaining their updated features in one shot (another point on RNNs where features are updated word by word).
We can better understand the attention mechanism through the following:
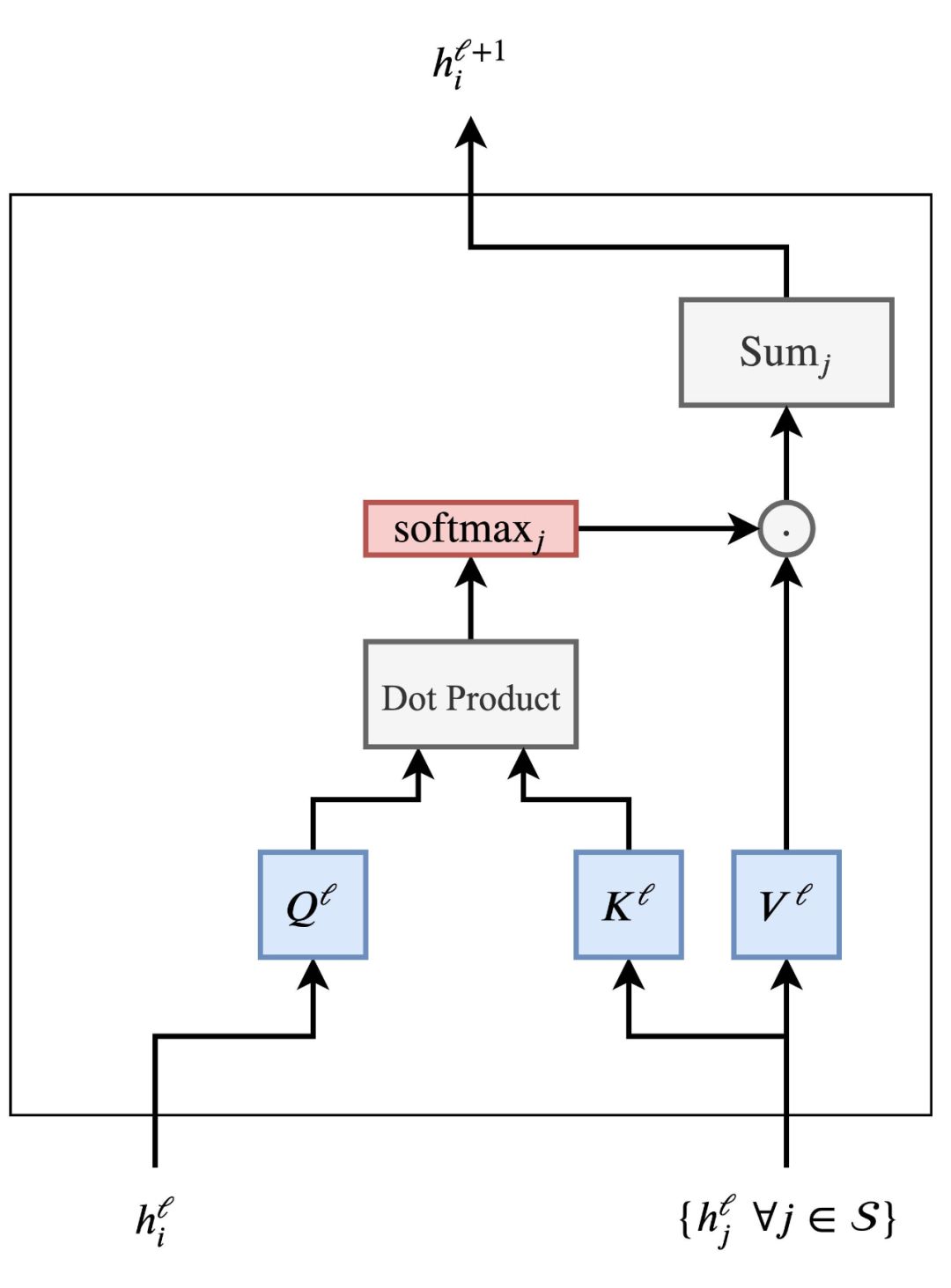
Considering h_j^l; ∀j∈S, the features h_i^l of the word in the sentence and other words are computed by the dot product to calculate the attention weight for each pair (i, j), and then softmax is computed across all j.Finally, the updated word feature h_i^l+1 is obtained by weighting all h_j^l according to their weights.
Multi-Head Attention Mechanism
Making the dot product attention mechanism work has proven to be tricky:Poor random initialization can disrupt the stability of the learning process, which can be overcome by executing multiple heads of attention in parallel and concatenating the results (where each “head” has its own learnable weights):
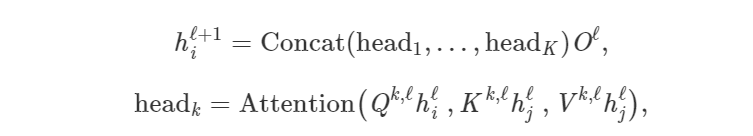
Where Q^k,ℓ, K^k,ℓ, V^k,ℓ are the learnable weights of the k-th attention head, O^ℓ is a downward projection to match the dimensions of h_i^l+1 and h_i^l across layers.
Moreover, multi-head attention allows the attention mechanism to essentially “hedge” and view different aspects of the transformations or hidden features from the previous layer.
Scale Issues and Forward Propagation Sub-Layers
A key issue driving Transformers is that the features of words may have different scales after passing through the attention mechanism:1) This may be due to some words having very high or distributed attention weights w_ij after addition;2) In the independent feature/vector input stage, concatenating multiple attention heads (each attention head may output different scale values) ultimately leads to the final vector h_i^ℓ+1 having different values.According to traditional ML thinking, adding a normalization layer seems like a reasonable choice.
Transformers overcome this by using LayerNorm, allowing for normalization at the feature level and learning an affine transformation.Additionally, Transformers use the square root to scale the dot product scale.
Finally, the authors of Transformers proposed another trick to control the scale—a specially structured, position-level two-layer fully connected layer.After multi-head attention, they use learnable weights to map h_i^ℓ+1 to a higher dimension.This involves using ReLU nonlinearity, then mapping back to the original dimension, and using another normalization operation.
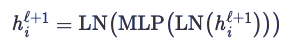
The structure of the Transformer layer is shown in the figure below:
In many deep networks, the Transformer architecture is adjustable, allowing the NLP community to scale up from the model parameter amount and data perspective.Residual connections are also key to stacking Transformer layers.
GNN Construction Graph Display
Graph Neural Networks (GNNs) or Graph Convolutional Networks (GCNs) establish representations of nodes and edges in graphical data.This is achieved through neighborhood aggregation (or information propagation), where each node collects features from its neighbors to update its local structure representation.Stacking multiple GNN layers allows the model to propagate each node’s features throughout the entire graph, spreading from neighboring nodes to neighboring nodes, and so on.
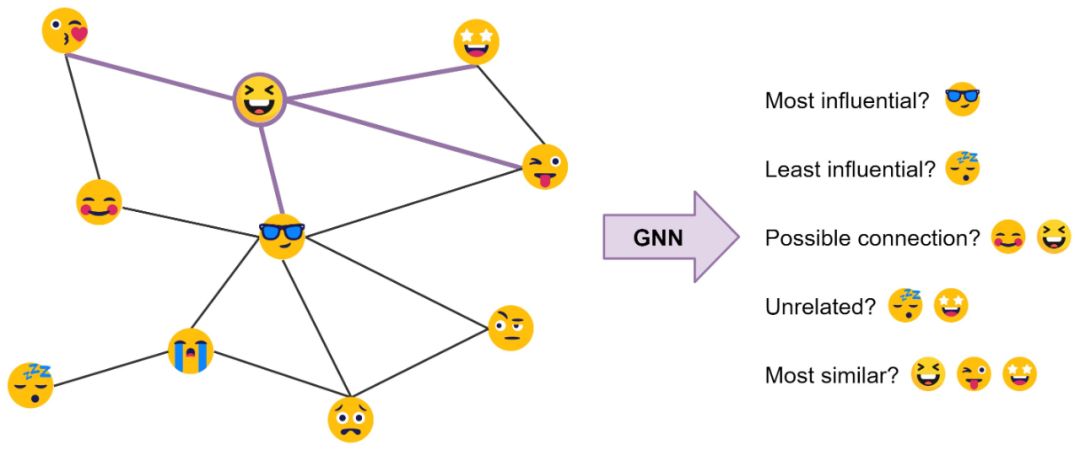
For example, in social networks:The node features generated by GNN can be used for predictions, such as identifying the most influential members or providing potential connections.
In its most basic form, GNNs update the hidden feature h of the first layer node i and add it to the feature set h_i^l of each neighboring node j∈N(i) through a nonlinear transformation of the node’s own feature h_i^l:
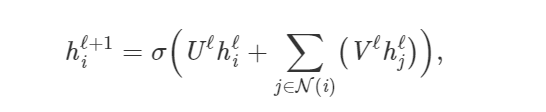
Where U^l,V^l are the learnable matrices of the GNN layer, similar to the ReLU nonlinear matrix.
The sum over neighborhood j nodes j∈N(i) can be replaced with other aggregation functions that do not change the input size, such as simple mean/max or other more efficient functions, like the weighted sum obtained through attention mechanisms.
If we adopt multiple parallel heads for neighborhood aggregation and replace the sum over neighborhood J with attention mechanisms (i.e., weighted sums), we obtain Graph Attention Networks (GAT). Adding regularization and feedforward MLP results in Graph Transformers.
Sentences as Fully Connected Graphs of Words
To make the relationship between Transformers and graph neural networks more direct, we can imagine a sentence as a fully connected graph where each word is connected to all other words.Now, we use graph neural networks to construct features for each node (word), which can be used in other NLP tasks later.
Broadly speaking, this is actually what Transformers do.They are essentially GNNs with multi-head attention (as a neighborhood aggregation function).Standard GNNs aggregate features from local cluster nodes j∈N(i), while Transformers view the entire sentence S as a local cluster, obtaining aggregated features from each word j∈S in each layer.
Importantly, various problem-specific techniques, such as positional encoding, masked aggregation, learning rate scheduling, and additional pre-training—are crucial for the success of Transformers, but are rarely seen in GNNs.At the same time, viewing Transformers from the perspective of GNNs can help us discard many unnecessary parts architecturally.
What Can Be Learned from Transformers and GNNs?
Now that we have established the connection between Transformers and GNNs, some questions naturally arise:
Is a fully connected graph the best input format for NLP?
Before the advent of statistical NLP and ML, linguists like Noam Chomsky focused on creating formal theories of language structure, such as grammar trees/graphs.Tree-LSTM is one such attempt, but can Transformers or GNN architectures better bridge linguistic theory and statistical NLP?This remains a question.
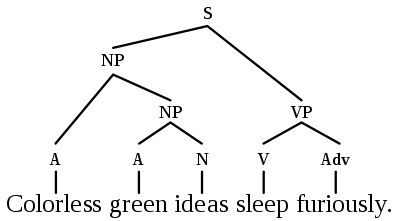
How to Learn Long-Term Dependencies
Another issue with fully connected graphs is that they make learning long-term dependencies between words difficult.This solely depends on how the number of edges in the fully connected graph expands quadratically with the number of nodes, for example, in a sentence with n words, Transformers or GNNs will compute n^2 word pairs.The larger n is, the more difficult the computation becomes.
The NLP community’s perspective on long sequences and dependencies is interesting; to achieve better Transformers, we can implement sparse or adaptive attention mechanisms considering input size, add recursion or compression at each layer, and use locality-sensitive hashing for efficient attention.
Thus, integrating some perspectives from the GNN community could yield significant results, such as binary partitioning for sentence graph sparsification appearing to be a good method.
Do Transformers Learn Neural Syntax?
The NLP community has produced some papers exploring what Transformers learn.However, this requires a basic premise, which is that attending to all word pairs in a sentence (with the aim of identifying which pairs are most interesting) enables Transformers to learn task-specific syntax, etc.
Moreover, different heads in multi-head attention may also focus on different syntactic features.
In terms of graphs, can we restore the most important edges and their derivatives based on the way GNNs perform neighborhood aggregation at each layer, when using GNNs on the full graph? I am uncertain about this.
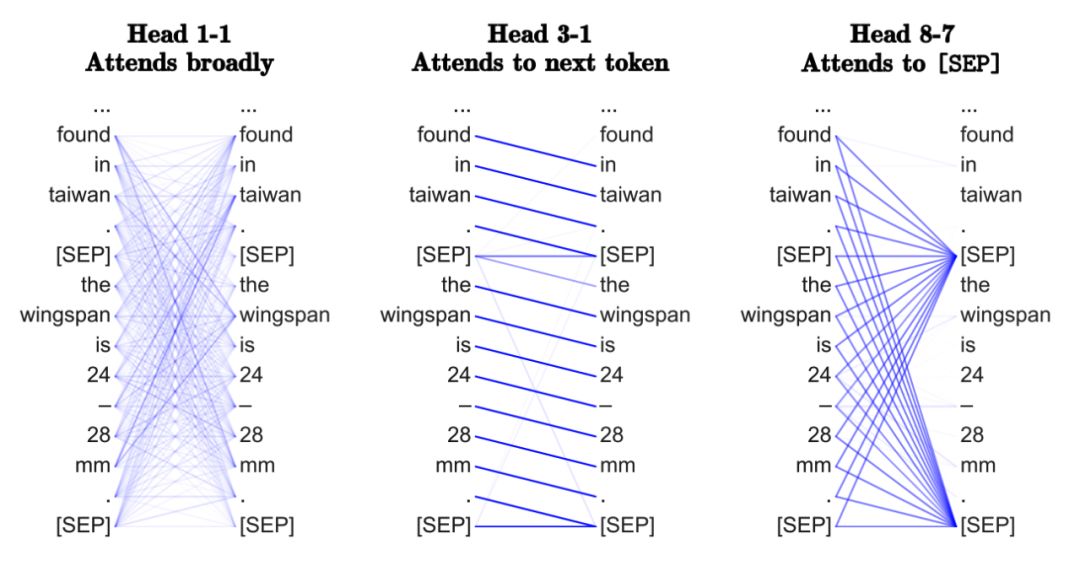
Why Use Multi-Head Attention?
I personally agree with the optimization perspective of multi-head attention mechanisms, as having multiple attention heads can enhance learning effectiveness and overcome poor random initialization.For example, the paper “Are Sixteen Heads Really Better than One?” indicates that after training without significant performance impact, Transformer heads can be “pruned” or “removed”.
Multi-head neighborhood aggregation mechanisms have also proven effective in GNNs; for example, GAT uses the same multi-head attention, and MoNet in the paper “Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs” uses multiple Gaussian kernels to aggregate features.Although multi-head methods are intended to stabilize the attention mechanism, can these methods become the standard for unleashing the remaining performance of the model?
In contrast, GNNs with simpler aggregation functions like sum or max do not require multiple aggregation heads to achieve stable training.So, if we do not compute the compatibility between any word pairs in the sentence, wouldn’t that be a better alternative for Transformers?
Furthermore, would Transformers benefit from completely eliminating attention?The paper “Convolutional Sequence to Sequence Learning” by Yann Dauphin et al. proposes an alternative ConvNet architecture.So, Transformers may eventually make some improvements similar to ConvNets.
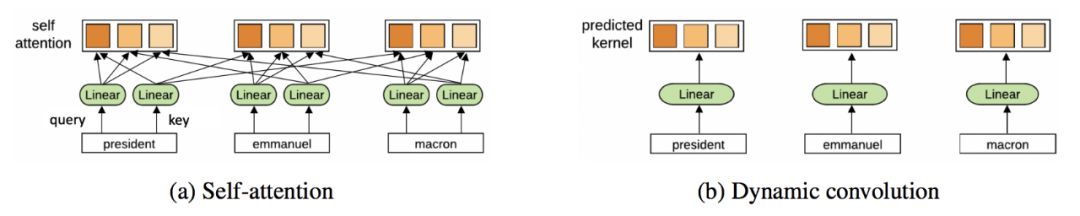
From the above points, GNNs and Transformers have many commonalities.Analyzing Transformers from the GNN perspective is significant for understanding the thought process of language models, enhancing model training efficiency, and reducing parameter counts in the future.
Reference link: https://graphdeeplearning.github.io/post/transformers-are-gnns/
Good News!
Beginner’s Guide to Vision Knowledge Planet
Is now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply "Chinese Tutorial for Extension Module" in the "Beginner's Guide to Vision" public account backend to download the first Chinese version of the OpenCV extension module tutorial available online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the "Beginner's Guide to Vision" public account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the "Beginner's Guide to Vision" public account backend to download 20 practical projects based on OpenCV implementation, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes; otherwise, you will not be approved. After successfully adding, you will be invited to enter the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be asked to leave the group. Thank you for your understanding~