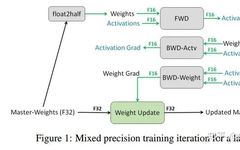
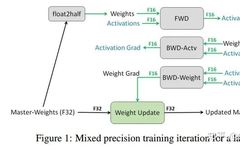
Strategies for Saving GPU Memory in PyTorch
Click on the above “Beginner’s Guide to Vision” to select and add “Star” or “Pin“ Heavy content delivered first Author | OpenMMLab Editor | Jishi Platform Original link: https://zhuanlan.zhihu.com/p/430123077 Introduction With the rapid development of deep learning, the explosion of model parameters has raised increasingly high requirements for GPU memory capacity. How to train models … Read more