
Original from AI Park
Author: Cheng He
Translated by: ronghuaiyang
Applying Transformers to CV tasks is becoming increasingly common, and here are some related advancements for everyone.

The Transformer architecture has achieved state-of-the-art results in many natural language processing tasks. A significant breakthrough for Transformer models may be the release of GPT-3 mid-year, which was awarded the “Best Paper” at NeurIPS 2020.
In the field of computer vision, CNNs have been the dominant model for visual tasks since 2012. With the emergence of increasingly efficient architectures, computer vision and natural language processing are converging, making the use of Transformers for visual tasks a new research direction aimed at reducing structural complexity and exploring scalability and training efficiency.
Here are several well-known projects in related work:
-
DETR (End-to-End Object Detection with Transformers), using Transformers for object detection and segmentation. -
Vision Transformer (AN IMAGE IS WORTH 16X16 WORDS: Transformer FOR IMAGE RECOGNITION AT SCALE), using Transformers for image classification. -
Image GPT (Generative Pretraining from Pixels), using Transformers for pixel-level image completion, similar to other GPT text completion methods. -
End-to-End Lane Shape Prediction with Transformers, using Transformers for lane marking detection in autonomous driving.
Architecture
Overall, there are two main model architectures in the relevant work adopting Transformers in CV. One is a pure Transformer structure, and the other is a hybrid structure that combines CNNs/backbones with Transformers.
-
Pure Transformer -
Hybrid: (CNNs + Transformer)
Vision Transformer is based on a complete self-attention Transformer structure without using CNNs, while DETR is an example of a hybrid model structure that combines Convolutional Neural Networks (CNNs) and Transformers.
Some Questions
-
Why use Transformers in CV? How to use them? -
What are the benchmark results? -
*What are the constraints and challenges of using Transformers in CV?* -
Which structure is more efficient and flexible? Why?
You will find the answers in the in-depth studies of ViT, DETR, and Image GPT below.
Vision Transformer
Vision Transformer (ViT) directly applies a pure Transformer architecture to a series of image patches for classification tasks, achieving excellent results. It also outperforms state-of-the-art convolutional networks on many image classification tasks, while the required pre-training computational resources are significantly reduced (at least by 4 times).
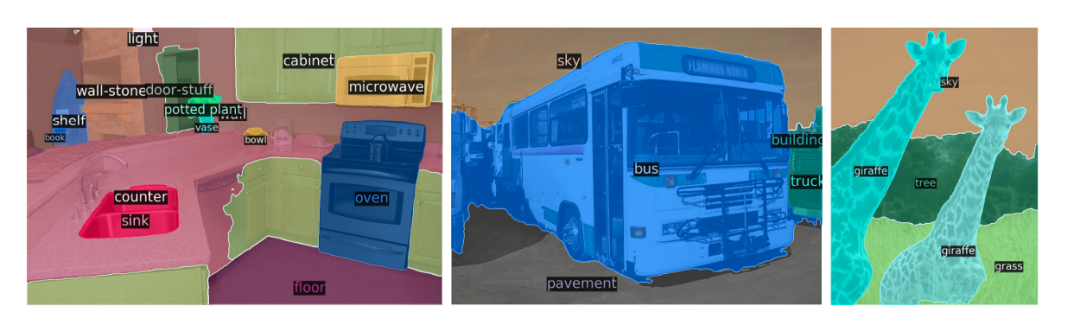
Image Sequence Patches
They segment the image into fixed-size small patches and then input the linear projections of these patches along with their image positions into the transformer. The remaining steps involve a clean and standard Transformer encoder and decoder.
Position embeddings are added to the image patch embeddings to retain spatial/positional information globally through various strategies. In this paper, they experimented with different spatial information encoding methods, including no positional encoding, 1D/2D position embedding encoding, and relative position embedding encoding.
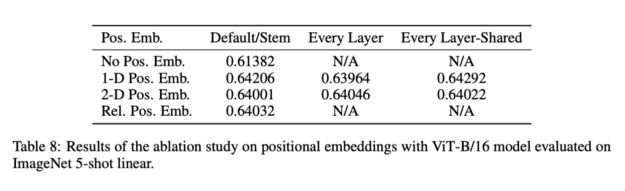
An interesting finding is that compared to one-dimensional position embeddings, two-dimensional position embeddings did not yield significant performance improvements.
Datasets
The model is pre-trained by removing duplicate data from multiple large datasets to support fine-tuning (smaller datasets) downstream tasks.
-
ILSVRC-2012 ImageNet dataset has 1k classes and 1.3 million images -
ImageNet-21k has 21k classes and 14 million images -
JFT has 18k classes and 303 million high-resolution images
Model Variants
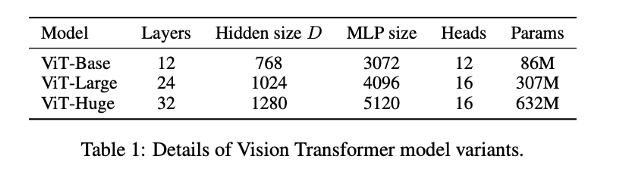
Like other popular Transformer models (GPT, BERT, RoBERTa), ViT (Vision Transformer) also has different model sizes (base, large, and huge) and different numbers of transformer layers and heads. For example, ViT-L/16 can be interpreted as a large (24-layer) ViT model with a 16×16 input image patch size.
Note that the smaller the input patch size, the larger the computational model, because the number of input patches N = HW/P*P, where (H, W) is the resolution of the original image, and P is the resolution of the patch image. This means that a 14 x 14 patch is computationally more expensive than a 16 x 16 patch.
Benchmark Results
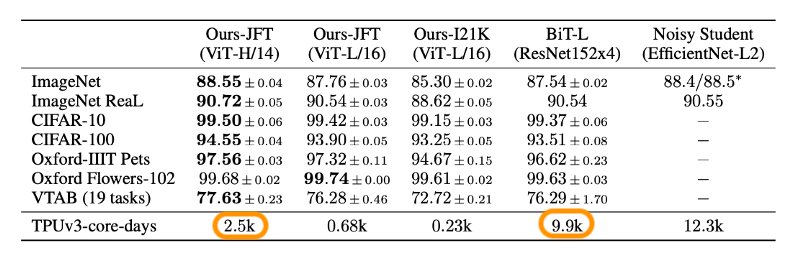
The results above indicate that the model outperforms existing SOTA models on multiple popular benchmark datasets.
Vision transformers (ViT-H/14, ViT-L/16) pre-trained on the JFT-300M dataset outperform ResNet models (ResNet152x4, pre-trained on the same JFT-300M dataset) on all test datasets, while the computational resources (TPUv3 core days) used during pre-training are significantly reduced. Even ViTs pre-trained on ImageNet-21K perform better than the baseline.
Model Performance vs Dataset Size
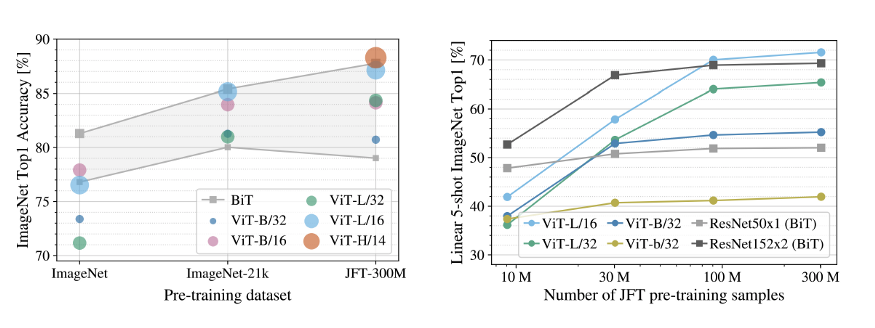
The above figure shows the impact of dataset size on model performance. When the pre-training dataset size is small, ViT does not perform well; when training data is abundant, it outperforms previous SOTA.
Which Structure is More Efficient?
As mentioned at the beginning, there are different architectural designs for using transformers in computer vision, some completely replace CNNs (ViT), some partially replace them, and some combine CNNs with transformers (DETR). The following results show the performance of various model structures under the same computational budget.
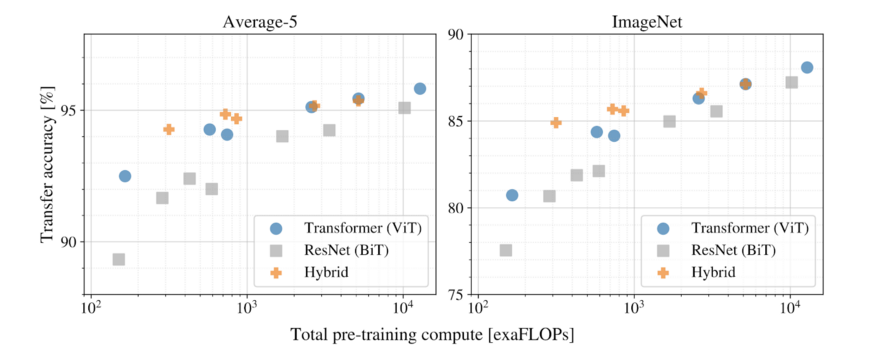
The above experiments indicate:
-
The pure Transformer architecture (ViT) is more efficient and scalable than traditional CNNs (ResNet BiT) in size and computational scale. -
The hybrid architecture (CNNs + Transformer) outperforms pure Transformers at smaller model sizes, while performance is very close at larger model sizes.
Key Points of ViT (Vision Transformer)
-
Uses Transformer architecture (pure or hybrid) -
Input images are tiled into multiple patches -
Defeated SOTA on multiple image recognition benchmarks -
Pre-training on large datasets is cheaper -
More scalable and computationally efficient
DETR
DETR is the first framework to successfully use Transformers as a main building block in the object detection pipeline. It matches the performance of previous SOTA methods (highly optimized Faster R-CNN) with a simpler and more flexible pipeline.
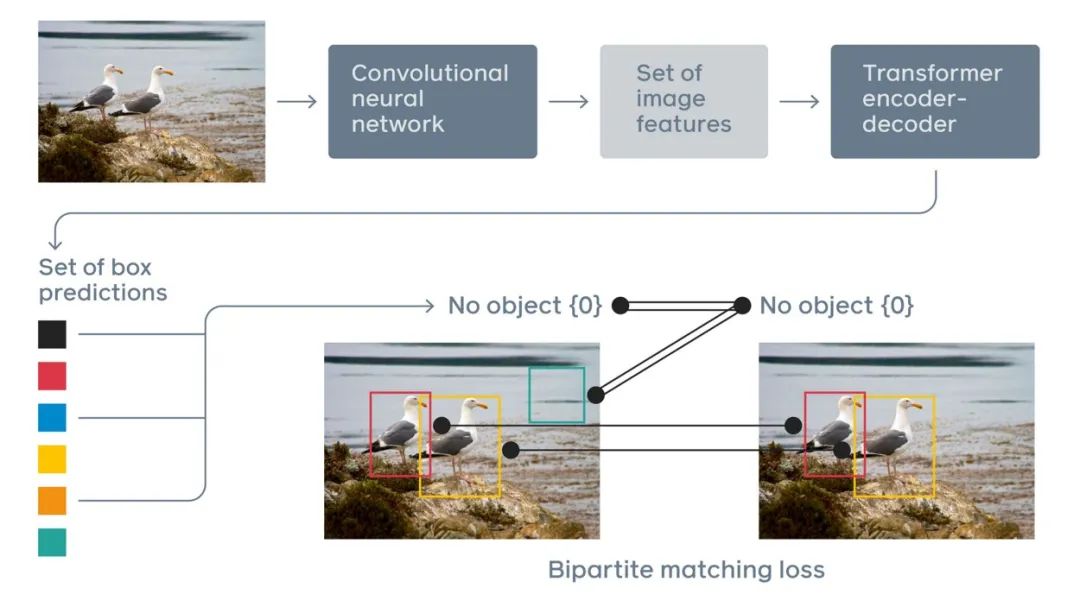
The above image shows DETR, a hybrid pipeline with CNN and Transformer as the main building blocks. The process is as follows:
-
CNN is used to learn the 2D representation of the image and extract features -
The output of CNN is flattened and supplemented with position encoding to feed into the standard Transformer encoder -
The decoder of the Transformer predicts classes and bounding boxes through output embeddings into a feed-forward network (FNN)
Simpler Pipeline
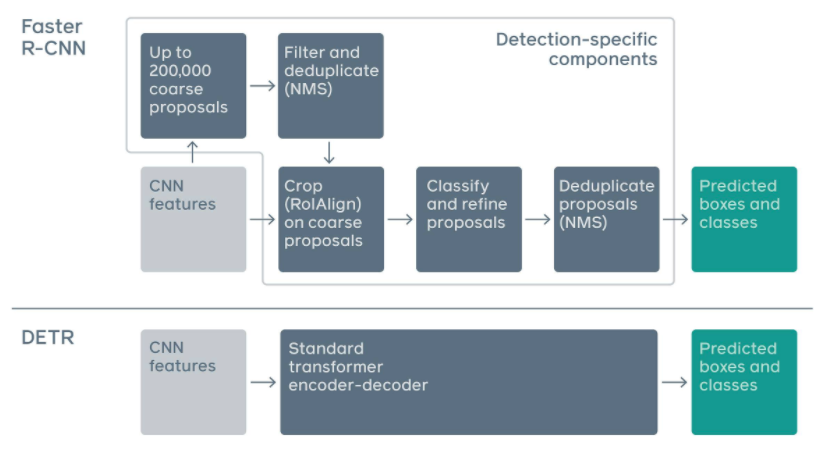
Traditional object detection methods, such as Faster R-CNN, have multiple steps for anchor generation and NMS. DETR eliminates these handcrafted components, significantly simplifying the object detection pipeline.
Amazing Results When Extended to Panoptic Segmentation
In this paper, they further extended the DETR pipeline for panoptic segmentation tasks, which is a recently popular and challenging pixel-level recognition task. To simply explain the panoptic segmentation task, it unifies two different tasks: one is traditional semantic segmentation (assigning class labels to each pixel), and the other is instance segmentation (detecting and segmenting each object’s instance). Using a single model architecture to solve both tasks (classification and segmentation) is a very clever idea.
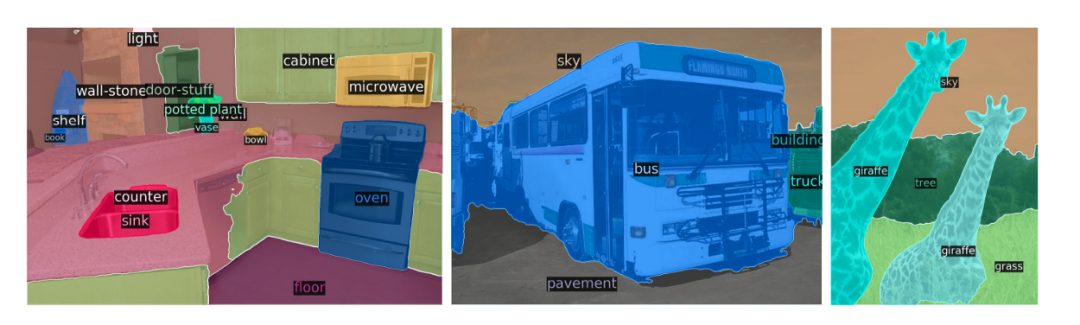
The above image shows an example of panoptic segmentation. Through DETR’s unified pipeline, it surpasses very competitive baselines.
Attention Visualization
The image below shows the attention of the Transformer decoder on the predictions. The attention scores for different objects are represented in different colors.
By observing the colors/attention, you will be surprised by the model’s ability to understand the image globally through self-attention and solve the overlapping bounding box problem. Especially the orange on the zebra legs, which, despite overlapping with blue and green regions, is well classified.

Key Points of DETR
-
Uses Transformer for a simpler and more flexible pipeline -
Can match SOTA on object detection tasks -
Parallel, more efficient direct output of final prediction sets -
Unified architecture for object detection and segmentation -
Significant improvement in detection performance for large objects, but decreased performance for small objects
Image GPT
Image GPT is a model trained on pixel sequences for image completion using the GPT-2 transformer model. Like general pre-trained language models, it is designed to learn high-quality unsupervised image representations. It can autoregressively predict the next pixel without knowing the 2D structure of the input image.
Features from pre-trained Image GPT achieve state-of-the-art performance on some classification benchmarks and approach state-of-the-art unsupervised accuracy on ImageNet.
The image below shows the completion model generated from a half-provided image as input, followed by the creative completion from the model.

Key Points of Image GPT:
-
Uses the same transformer architecture as GPT-2 in NLP -
Unsupervised learning, no manual labeling required -
Requires more computation to generate competitive representations -
Learned features achieved SOTA performance on classification benchmarks in low-resolution datasets
Conclusion
The tremendous success of Transformers in natural language processing has been explored in the field of computer vision and has become a new research direction.
-
Transformers have proven to be a simple and scalable framework for computer vision tasks such as image recognition, classification, and segmentation, or merely learning global image representations. -
Significantly advantageous in training efficiency compared to traditional methods. -
Architecturally, it can be used in a pure Transformer way or in a hybrid method combined with CNNs. -
It also faces challenges, such as lower performance in detecting small objects in DETR and subpar performance when the pre-training dataset is small in Vision Transformer (ViT). -
Transformers are becoming a more general framework for learning sequential data (including text, images, and time series data).

Original in English: https://towardsdatascience.com/transformer-in-cv-bbdb58bf335e

Please long press or scan the QR code to follow this public account