
Source: DeepHub IMBA
This article is 4000 words long, and it is recommended to read it in 10 minutes.
This study not only points out a long-ignored technical issue but also provides important optimization directions for future model training practices.
When fine-tuning large-scale language models (LLMs) in a local environment, it is often difficult to achieve large-batch training due to GPU memory limitations. To address this issue, gradient accumulation techniques are commonly used to simulate larger batch sizes. This method differs from the traditional way of updating model weights after each batch; instead, it accumulates gradients over multiple smaller batches and only updates the weights after a preset number of accumulations. This approach effectively achieves the effects of large-batch training while avoiding common memory overhead issues.
Theoretically, setting the batch size to 1 and accumulating gradients over 32 batches should yield results equivalent to directly using a batch size of 32 for training. However, practical research has found that when using mainstream deep learning frameworks (such as Transformers), the gradient accumulation method often leads to significantly worse model performance compared to directly using large-batch training.
This issue has sparked widespread discussion on Reddit, and Daniel Han from Unsloth AI has successfully reproduced the problem. He found that this issue affects not only single-machine gradient accumulation but also multi-GPU training environments. In multi-GPU configurations, implicit accumulation of gradients across multiple devices can lead to suboptimal model training results. Moreover, this problem may have persisted undetected for several years in model training.
This article will discuss the following aspects: First, it will explain the basic principles of gradient accumulation and illustrate the specific manifestations of the problem and the error accumulation process through examples; secondly, it will analyze the impact of this problem in different training scenarios; finally, it will evaluate the effectiveness of the correction proposed by Unsloth, which has already been implemented in the Transformers framework by Hugging Face.
Detailed Explanation of Gradient Accumulation Technology
Analysis of Neural Network Training Process
The training process of a neural network includes the following key steps: generating predictions through forward propagation, calculating the loss between predicted values and true values, and then calculating gradients through backpropagation to optimize model weights. In a standard training process, the gradients of each batch are immediately used to update model weights after they are computed.
Using a larger batch size typically provides a more stable training process and helps improve model performance and generalization ability. However, large-batch training requires more memory, especially in terms of gradient computation and storage. When hardware resources are limited, it may not be possible to load large batch data into memory all at once, which limits the actual usable batch size.
Implementation Mechanism of Gradient Accumulation
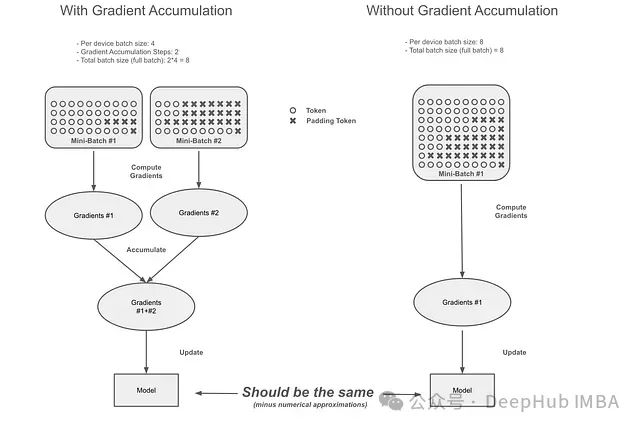
Gradient accumulation technology achieves large-scale batch training by breaking down large batch data into multiple smaller batches. Unlike traditional methods that update model weights after each small batch, this technique accumulates gradients over multiple smaller batches and only performs a weight update once the predetermined accumulation steps are completed. The specific implementation mechanism is as follows:
-
First, determine the target effective batch size and the small batch size that the hardware can handle. If the target effective batch size is 64, and the hardware can only process 16 samples at a time, then gradient accumulation needs to be performed over 4 batches of size 16. -
During training, for each small batch, perform forward propagation, loss calculation, and backpropagation operations to compute the gradients. At this point, do not directly update the weights, but store the gradients in an accumulation buffer. -
When the number of processed small batches reaches the preset threshold (e.g., 4 small batches in the above example), average the accumulated gradients and use this average gradient to update the model weights. Then clear the accumulation buffer and enter the next accumulation cycle.
Application Scenarios of Gradient Accumulation
Current mainstream large-scale language models and visual language models are often large in scale, with parameter counts typically exceeding the memory capacity of a single GPU. In this case, gradient accumulation technology has significant advantages.
Main application scenarios include:
-
Training of Large Models in Resource-Constrained Environments: For large Transformer models or convolutional neural networks (CNNs) used for image processing, the memory required for full batch training often exceeds hardware limitations. Gradient accumulation makes it possible to achieve equivalent large-batch training under limited resource conditions. -
Optimization of Distributed Training Environments: In multi-device training configurations, gradient accumulation can effectively reduce synchronization frequency between devices. Each device can first accumulate gradients locally and only synchronize once the accumulation cycle is completed, significantly reducing communication overhead.
In practical applications, gradient accumulation has become a standard technique in the training process of various models (including pre-training, fine-tuning, and post-training stages).
Normalization Issues in Gradient Accumulation
Theoretically, training with a single batch of N samples should be mathematically equivalent to training with gradient accumulation over 4 batches of N/4 samples.
However, this is not the case.
A simple gradient summation strategy cannot ensure the mathematical equivalence of gradient accumulation and full batch training. In the cross-entropy loss calculation process commonly used in most LLM training, normalization is usually required based on the number of non-padding or non-ignored tokens to ensure that the loss value matches the number of effective tokens in the training sequence. For simplification, we assume that the sequence length equals the average length of the dataset.
In the actual gradient accumulation process, the losses of each small batch are independently calculated and then directly summed, leading to a final total loss that is G times larger than that of full batch training (where G is the number of gradient accumulation steps). To correct this issue, each accumulated gradient needs to be scaled by 1/G to match the results of full batch training. However, the effectiveness of this scaling method is based on the assumption that the sequence lengths between small batches are consistent.
In practical training of models like LLMs, variations in sequence length are common, and this variation can lead to biases in loss calculation. In applications such as causal language model training, the correct gradient accumulation method should first calculate the overall loss of all batches in the accumulation steps, and then divide it by the total number of non-padding tokens in these batches. This is fundamentally different from the method of calculating the loss for each batch separately and then averaging it.
Therefore, when the sequence lengths in small batches are consistent and do not require padding, traditional gradient accumulation methods remain effective. For readers unfamiliar with padding mechanisms, it is recommended to refer to relevant technical documentation to gain a deeper understanding of its impact on batch processing.
From a technical implementation perspective, the pre-training phase of LLMs is relatively less affected by this issue. Although the pre-training process requires substantial GPU resources for gradient accumulation, this phase typically employs complete large-scale batches containing continuous document blocks, with no need for padding operations. The design goal of the pre-training phase is to maximize the learning effect of each training step. This also explains why many LLM vocabularies do not include padding tokens, as padding operations are rarely used during the pre-training phase.
Experimental Validation of Gradient Accumulation Issues
To quantitatively analyze the impact of erroneous gradient accumulation on the training process, this study conducted systematic experiments using Unsloth on SmolLM-135M (Apache 2.0 license), testing model performance under different batch sizes, gradient accumulation steps, and sequence length configurations.
The experimental environment utilized the memory-efficient Unsloth framework and a moderately sized LLM to conduct large-batch training experiments on a 48GB GPU (A40 provided by RunPod).
Impact Analysis of Large-Scale Gradient Accumulation Steps
First, the existence of the gradient accumulation issue was verified. Theoretically, the following training configurations should produce nearly identical learning curves:
-
per_device_train_batch_size = 1, gradient_accumulation_steps = 32 -
per_device_train_batch_size = 32, gradient_accumulation_steps = 1 -
per_device_train_batch_size = 2, gradient_accumulation_steps = 16 -
per_device_train_batch_size = 16, gradient_accumulation_steps = 2
The overall training batch size for these configurations is 32.
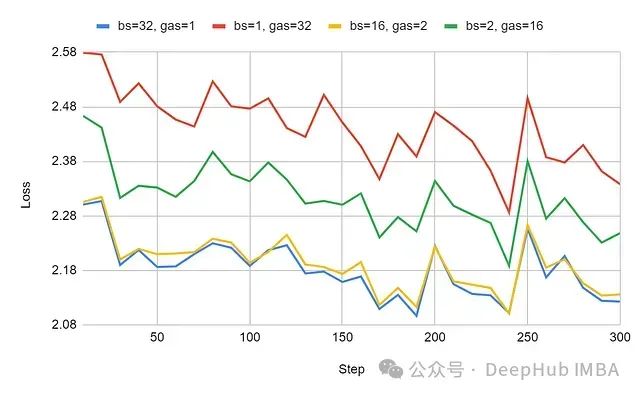
This study focuses on the relative loss differences between configurations rather than absolute loss values. The learning curves under the maximum sequence length of 2048 tokens (the upper limit supported by SmolLM) are as follows:
Comparing the learning curves under different batch sizes (bs) and gradient accumulation steps (gas), we can see the learning curves under a sequence length of 512 tokens:
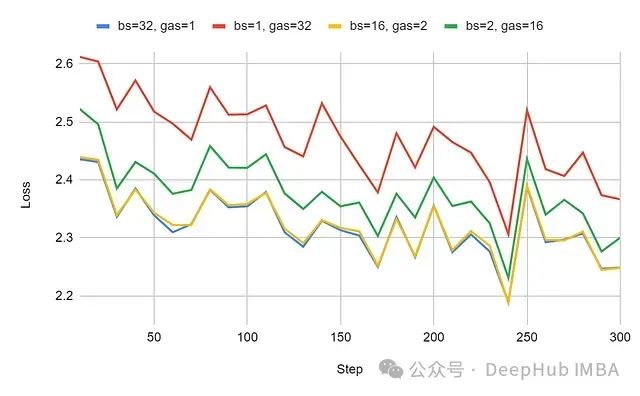
The experimental data shows that there are significant differences between the configurations of batch size (bs) 32 and gradient accumulation steps (gas) 32. When the gradient accumulation steps are reduced to 16, this difference diminishes.
Data analysis indicates that the loss value under the configuration of gas=32 cannot fully converge to the level of bs=32. For the configuration of 2048 token sequence length, the loss difference stabilizes in the range of 0.2 to 0.3; for the configuration of 512 token sequence length, the difference range is between 0.1 and 0.2.
The configuration with 2048 token sequence length exhibits greater performance differences, indicating that the increase in padding sequences within small batches significantly amplifies the bias effect of gradient accumulation.
Experimental Analysis of Highly Disparate Sequence Length Scenarios
To further investigate this issue, the author constructed a testing scenario with highly uneven small batch sequence lengths. For example, when a small batch contains a sequence with 1 effective token (accompanied by 2047 padding tokens), while another contains a complete sequence with 2048 effective tokens (no padding), the extreme difference in sequence lengths significantly amplifies the bias of gradient accumulation.
In the experiment, sequences with extreme lengths were artificially constructed by filtering out extremes from the fine-tuning dataset (only retaining sequences shorter than 256 tokens and longer than 1024 tokens).
The learning curves obtained from the experiment are as follows:
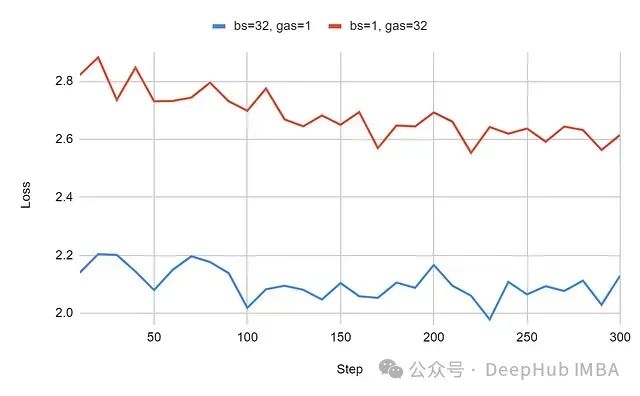
As expected, the extreme variation in sequence lengths and sparse distribution led to more significant performance degradation. The loss difference remained in the large range of 0.45 to 0.70.
Experimental Conclusion: This issue has a significant negative impact on training configurations with a wide range of sequence lengths.
Experimental Validation of Sequence Length Consistency Scenarios
Although significant variations in sequence lengths exacerbate the gradient accumulation issue, when processing datasets with relatively consistent sequence lengths, the impact of this issue should be significantly reduced. In such cases, the bias of gradient accumulation should be minimized.
To validate this hypothesis, the experiment set the maximum sequence length to 1024 and only retained sequences of at least 1024 tokens for fine-tuning. Under this configuration, all sequences do not require padding, and excessively long sequences are truncated to 1024 tokens.
All small batches in the experiment maintained consistent sequence lengths:
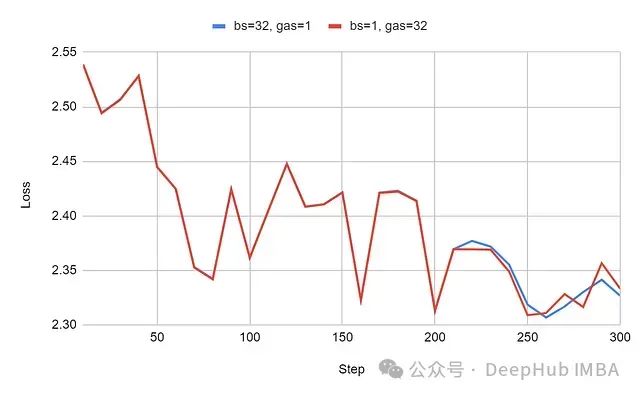
The experimental results align with theoretical expectations, and the learning curves exhibit high consistency. Although slight differences emerged after approximately 210 training steps, this can be attributed to numerical approximation errors introduced by the 8-bit quantized AdamW optimizer.
This experiment practically verifies the effectiveness of gradient accumulation when sequence lengths are consistent. It further supports the previous inference: the pre-training phase of LLMs is relatively less affected by this issue, as padding is rarely used during pre-training, and developers typically maximize the use of tokens in each batch to improve memory efficiency.
Experimental Validation of Gradient Accumulation Correction Solutions
To validate the effectiveness of the correction proposed by Unsloth and implemented by Hugging Face, we need to evaluate the consistency of learning curves between configurations with and without gradient accumulation after the correction.
First, the Transformers library environment needs to be updated. Since this correction was only recently merged into the main branch, we use the following command to update from the source code:
pip install --upgrade --no-cache-dir "git+https://github.com/huggingface/transformers.git"
Comparing the learning curves under the configuration of a maximum sequence length of 2048 tokens:
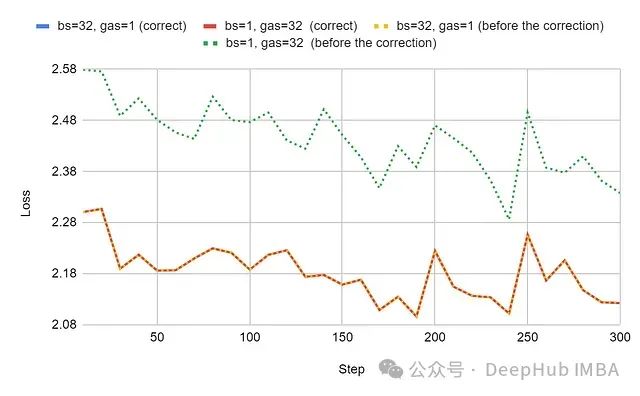
Experimental results indicate that the correction achieved the desired effect: the learning curves of the configurations bs=32, gas=1 and bs=1, gas=32 effectively aligned. The mathematical equivalence of gradient accumulation has been restored. Although not obvious in the graph, detailed data analysis shows that there are still minor differences of up to approximately 0.0004 in certain training steps, which can be attributed to numerical approximation errors introduced during AdamW quantization.
Conclusion
Given that this issue affects the gradient accumulation mechanism across devices and small batches, it can be inferred that some model training results over the past several years may have been suboptimal.
The study results indicate that the extent of its impact mainly depends on the specific training configuration, especially the number of GPUs involved and the number of gradient accumulation steps. Models trained with large-scale gradient accumulation steps or highly variable sequence lengths may have undergone suboptimal learning processes, potentially leading to performance losses in downstream tasks.
As this issue has been recognized and corrected in the Hugging Face Transformers framework, future model training and fine-tuning efforts are expected to achieve better and more stable results. For relevant work in the research and industrial communities that previously used the affected framework, it is recommended to reassess whether training with the corrected gradient accumulation scheme can yield significant performance improvements.
Overall, although the specific impact range of this issue remains to be quantified in further studies, it is certain that models trained using flawed gradient accumulation schemes have significant optimization potential. This study not only points out a long-ignored technical issue but also provides important optimization directions for future model training practices.
About Us
Data Pie THU is a data science public account backed by Tsinghua University Big Data Research Center, sharing cutting-edge research dynamics in data science and big data technology innovation, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group in China’s big data.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU