
Author: Pranoy Radhakrishnan
Translator: wwl
Proofreader: Wang Kehan
This article is about 3000 words and is recommended to be read in 10 minutes.
This article discusses the application of Transformer models in the field of computer vision and compares them with CNNs.
Before understanding Transformers, consider why researchers are interested in studying Transformers when there are already MLPs, CNNs, and RNNs.
Transformers were initially used for language translation. Compared to recurrent neural networks (like LSTM), Transformers support modeling long dependencies among input sequence elements and allow for parallel processing of sequences.
Transformers utilize the same processing module to handle different types of inputs (including images, videos, text, and speech). Everyone hopes that a unified model can solve various problems while maintaining accuracy and speed. Just as MLPs serve as universal function approximators, Transformer models provide a universal solution function for sequence-to-sequence problems.
Transformers apply attention mechanisms, and first, we learn about attention mechanisms and self-attention mechanisms.
-
Attention Mechanism
The role of the attention mechanism is to enhance the importance of key parts of the input data while reducing the importance of the remaining parts. Just like when you understand an image, you focus on the meaningful parts of the image. The attention mechanism does this as well.
But why do we need attention mechanisms? After all, CNNs have performed well in image feature extraction, haven’t they?
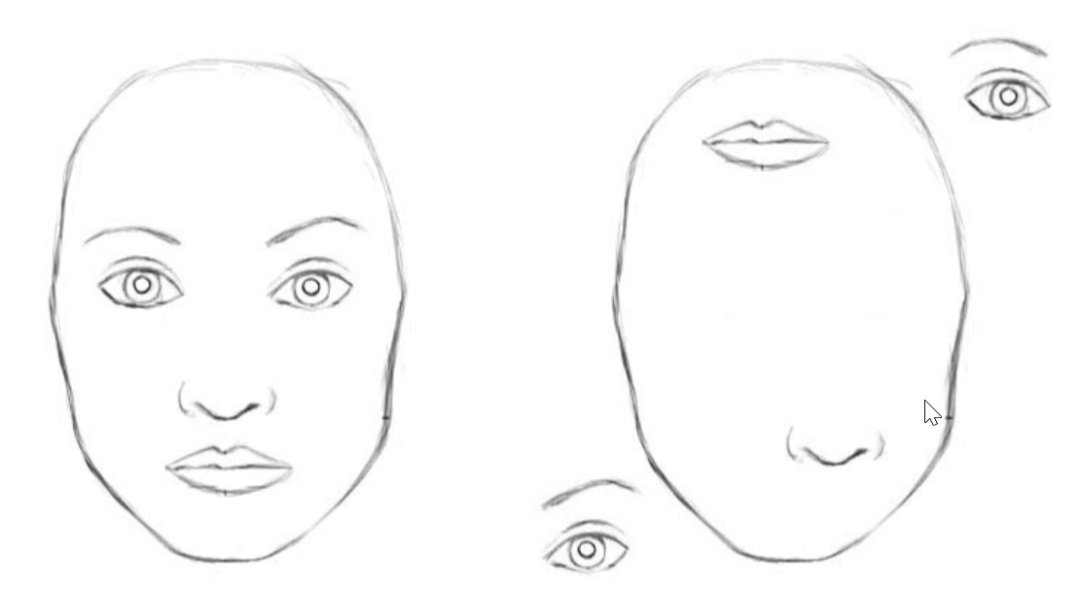
For a CNN, the same operation is applied to every input image. CNNs do not encode the relative positions of different features. If you want to encode the combination of these features, you need a large convolutional kernel. For example, to encode the information of eyes above the nose and mouth, a large convolutional kernel is required.
To capture larger range dependencies within an image, a larger receptive field is needed. Increasing the size of the convolutional kernel can enhance the model’s expressive power, but doing so also sacrifices the computational and statistical efficiency gained from using local convolutional structures.
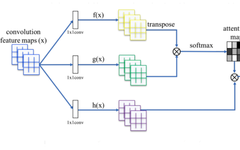
The self-attention mechanism is a type of attention mechanism that, when combined with CNNs, can help fit long-range dependencies without sacrificing computational and statistical efficiency. The self-attention module complements convolution, helping to fit long-range, multi-level dependencies within image regions.
You can see that the self-attention module replaces the convolutional layers, allowing every position in the model to relate to distant pixel points.
In a recent study, researchers conducted a series of ResNet experiments, replacing some or all of the convolutional layers with attention modules. The results showed that the best-performing experiment had convolutional layers in the shallow layers and attention layers in the deeper layers.
-
Self-Attention
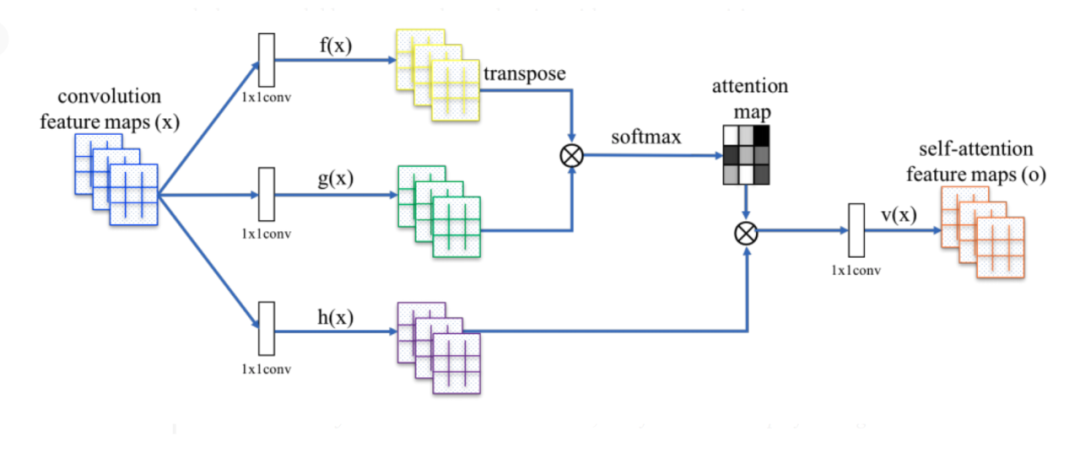
The self-attention mechanism is a type of attention mechanism that allows each element in the sequence to interact with other elements in the sequence and determine which other elements should be focused on more strongly.
The goal of self-attention is to capture relationships among all entities; it is a weighted combination of all word vectors, capable of capturing long-range information and dependencies between elements in the sequence.
From the image above, we can see that “it” refers to “street” and not “animal.” Self-attention is a weighted combination of other word vectors. Here, the word vector for “it” is a weighted combination of other word vectors, where the weight for the word “street” is higher.
If you want to understand how the weights are derived, refer to this video:
https://www.youtube.com/watch?v=tIvKXrEDMhk
Essentially, a self-attention layer updates each element in the input sequence by integrating all information from the complete input sequence.
Therefore, we have learned how attention mechanisms like self-attention effectively address some limitations of convolutional networks. Now, is it possible to completely replace CNNs with attention-based models like Transformers?
In the NLP field, Transformers have already replaced LSTMs. So can Transformers replace CNNs in the field of computer vision? Next, we will delve into the aspects where attention methods surpass CNNs.
-
Transformer Model
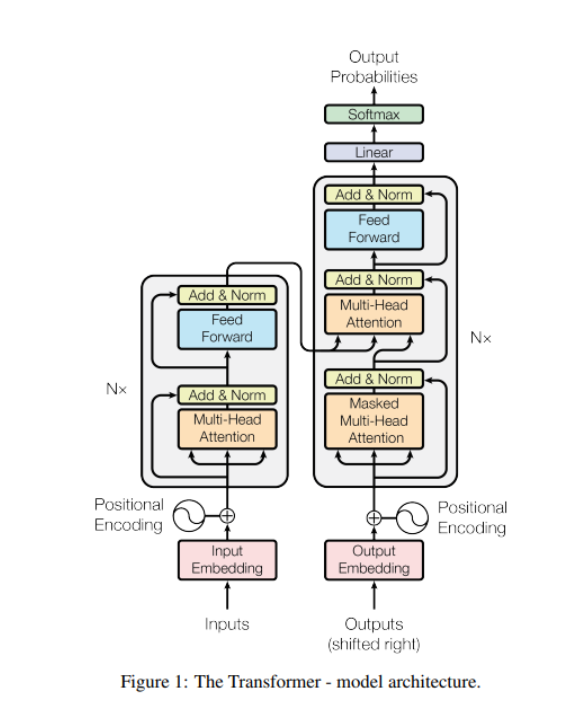
The Transformer model was initially designed to solve translation problems in natural language processing, consisting of an encoder-decoder structure. The left side of the image represents the encoder, while the right side represents the decoder. Both the encoder and decoder contain self-attention mechanisms, linear layers, and residual fully connected layers.
-
Encoder
Taking translation as an example, the self-attention within the encoder helps the words in the input sequence to interact, thus generating a feature representation for each word that contains semantic similarity with other words in the sequence.
-
Decoder
The decoder’s job is to output one translated word at a time, based on the input word embeddings generated so far and the output.
The decoder outputs translated words by referencing specific parts of the encoder’s output and the previous outputs of the decoder. To ensure that the encoder only utilizes previously generated outputs and does not include future outputs during training, the Mask Self Attention mechanism is used in the decoder. It simply masks the future words given as input to the decoder during training.
Self-attention does not concern itself with position. For example, in the sentence “Deepak is the son of Pradeep,” self-attention will give more weight to the word “Deepak” for the word “son.” If we change the order to “Pradeep is the son of Deepak,” self-attention will still give more weight to the word “Deepak” for the word “son,” but actually, we would prefer that if the order of words in the sentence changes, self-attention could give more weight to “Pradeep” for the word “son.”
This is because, when encoding the word “son,” the self-attention mechanism is performing a weighted combination of the word vectors for all other words without considering positional relationships. Therefore, changing the order of words in the sentence does not make any difference. In other words, the self-attention mechanism is position-agnostic. Unless positional information is added to each word before inputting the sub-vectors into the self-attention module.
-
Vision Transformer
Vision Transformer replaces convolutional layers with Transformers.
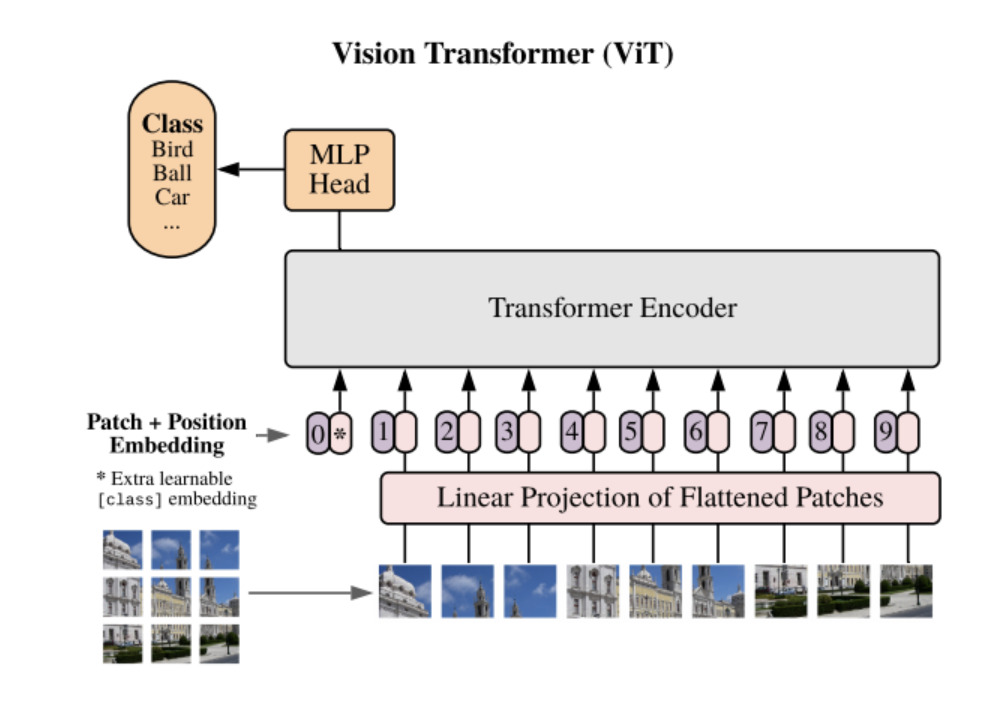
Figure: Vision Transformer
Transformers are generally applied to sequential data, so we split images into patches, and then flatten each patch into a vector. From now on, I will refer to this patch as an element (token), thus we now have a sequence composed of such elements.
The self-attention mechanism is position-agnostic (permutation invariance). Its weighted summation of different attention vectors is a “generalized” summary.
Here, permutation invariance means that if the input sequence is [A, B, C, D], the output from the self-attention network will be the same as when the input sequence is [A, C, B, D], as well as any other sequence where the positions of the elements have changed, the output will still be the same.

Figure: If no positional encoding is added to the patches, these two sequences appear identical to the Transformer
Therefore, adding positional information before inputting helps the Transformer understand the relative positions of elements in the sequence. Here, we learn position encoding rather than using standard encoding. Without adding positional encoding, these sequences appear the same to the Transformer.
Finally, the output from the Transformer serves as input for subsequent MLP classifiers.
Training Transformers from scratch requires more data than CNNs. This is because CNNs can encode prior knowledge of images, such as translational equivariance. However, Transformers need to derive this information from the provided data.
Translational equivariance is a property of convolutional layers; if we move an object in the image to the right, the activations of the feature layer (the extracted features) will also move to the right. But they are “actually the same representation.”
-
ConViT
Vision Transformer, which implements self-attention mechanisms on patches, learns convolutional inductive biases (e.g., equivariance). The downside is that they require a lot of data to learn everything from scratch.
.
CNNs have strong inductive bias, so they perform better on small datasets. However, when large amounts of data are available, the strong inductive bias of CNNs can limit the model’s capabilities.
So, is it possible to have both strong inductive bias on small datasets and not be limited on large datasets?
The solution is to introduce a Positional Self Attention Mechanism (PSA), which can serve the role of convolutional layers if needed. We simply replace some self-attention layers with PSA.
We know that since self-attention has position-agnostic properties, positional information is usually added to image patches. We are not adding positional information during the embedding phase but are replacing the original self-attention layers with PSA.
In PSA, the attention weights are computed using relative position encoding (r) and trained word vectors (v). Here, the relative position encoding (r) relies solely on the distance between pixels.
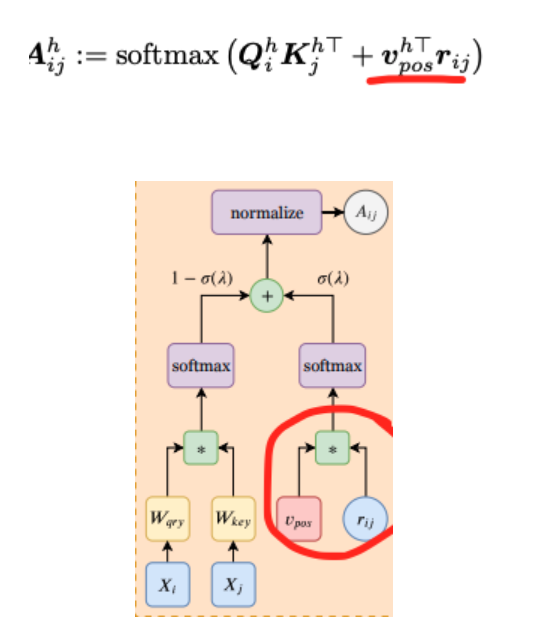
These multi-head PSA layers with learnable relative position encodings can express any convolutional layer.
Thus, we are not integrating CNNs with attention mechanisms but applying PSA layers, which can mimic the effects of convolutional layers by adjusting parameters. In small dataset scenarios, PSA can help the model generalize better, while in large dataset scenarios, PSA can retain its convolutional properties if needed.
-
Conclusion
Here we demonstrate that the Transformer, initially used for machine translation, has shown excellent performance in the image domain. The ViTs surpassing CNNs in image classification is a significant breakthrough. However, ViTs require pre-training on additional large datasets. On the ImageNet dataset, ConViT outperformed ViTs and also improved efficiency. All of these prove that Transformers have the potential to surpass CNNs in the image domain.
-
References
Translator’s Profile
Recruitment Information for Translation Team
Job Content: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are a data science/statistics/computer major studying abroad, or working in related fields, or confident in your language skills, you are welcome to join the translation team.
What you can gain: Regular translation training to improve volunteers’ translation skills, enhance understanding of the frontiers of data science, and allow overseas friends to maintain contact with domestic technological applications. The background of THU Data Team provides good development opportunities for volunteers.
Other Benefits: Data science professionals from well-known companies, students from prestigious schools like Peking University and Tsinghua University, and overseas students will become your partners in the translation team.
Click “Read Original” at the end of the article to join the Data Team~
Reprint Notice
If you need to reprint, please indicate the author and source prominently at the beginning (reprinted from: Data Team ID: DatapiTHU), and place a prominent QR code of Data Team at the end of the article. For articles with original identification, please send [Article Name – Pending Authorization Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
After publication, please provide the link feedback to the contact email (see below). Unauthorized reprints and adaptations will be legally pursued.

Click “Read Original” to embrace the organization