

❝
Author: Xiao Mo
From: Aze’s Learning Notes
❞
1. Introduction
This blog mainly contains my “encounters, thoughts, and solutions” while learning about Transformers, using a “16-shot” approach to help everyone better understand the issues.
2. Sixteen Shots
-
Why do we need Transformers? -
What is the function of Transformers? -
What is the overall structure of Transformers? -
What is the structure of the Transformer encoder? -
What is the structure of the Transformer decoder? -
What is traditional attention? -
What does self-attention look like? -
How does self-attention solve the long-distance dependency problem? -
How is self-attention parallelized? -
How is multi-head attention resolved? -
Why add position embedding? -
Why add residual modules? -
What is layer normalization? What is normalization? -
What is a mask? -
What problems exist with Transformers? -
How to code Transformers?
3. Q&A
3.1 Why do we need Transformers?
Why do we need Transformers? First, we need to know what technologies existed before Transformers and the problems they had:
-
RNN: Can capture long-distance dependency information, but cannot parallelize; -
CNN: Can parallelize, but cannot capture long-distance dependency information (needs to increase the receptive field through stacking or dilated convolution kernels); -
Traditional Attention -
Method: Calculates attention based on hidden vectors from the source and target sides, -
Result: The dependency relationship between each word in the source and each word in the target 【Source -> Target】 -
Problem: Ignores the dependency relationships between words at the far end or target end
3.2 What is the function of Transformers?
The architecture based on Transformers is mainly used for modeling language understanding tasks. It avoids using recursion in neural networks and instead relies entirely on the self-attention mechanism to map the global dependencies between inputs and outputs.
3.3 What is the overall structure of Transformers?
-
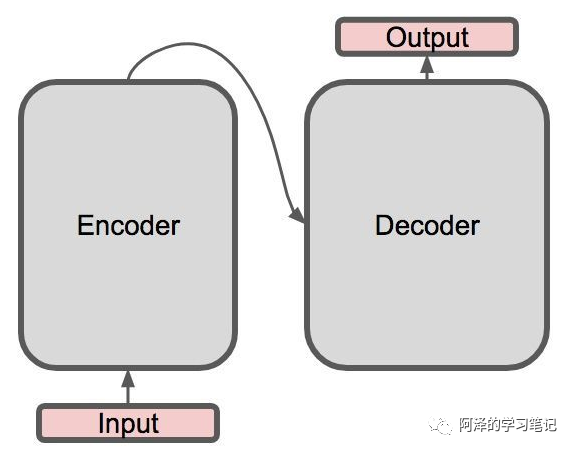
Overall Structure
-
Overall structure of Transformers: -
Encoder-decoder structure -
Specific introduction: -
The left side is an Encoder; -
The right side is a Decoder;
-
Enlarged overall structure
From the previous Transformer structure diagram, we can see that Transformers have an encoder-decoder structure, but what does the encoder and decoder contain?
-
Encoder structure: Contains 6 small encoders, each with 2 sub-layers; -
Decoder structure: Also contains 6 small decoders, each with 3 sub-layers
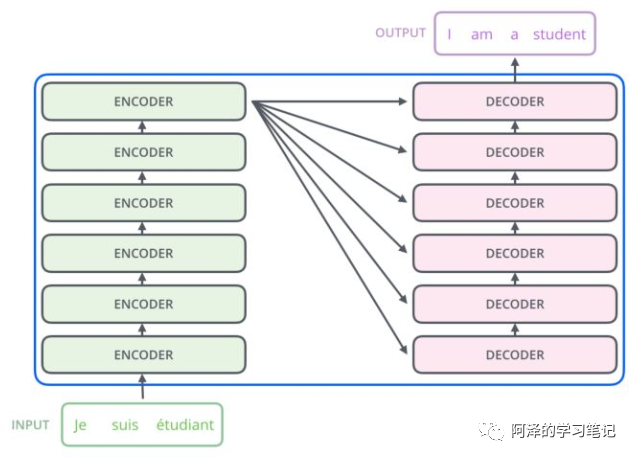
-
Further enlarged overall structure
The internal structure of each layer in the above figure is shown in the following diagram.
-
Each layer encoder on the left side of the above figure has the structure shown on the left side of the following diagram; -
Each layer decoder on the right side of the above figure has the structure shown on the right side of the following diagram;
Specific content will be introduced one by one later.
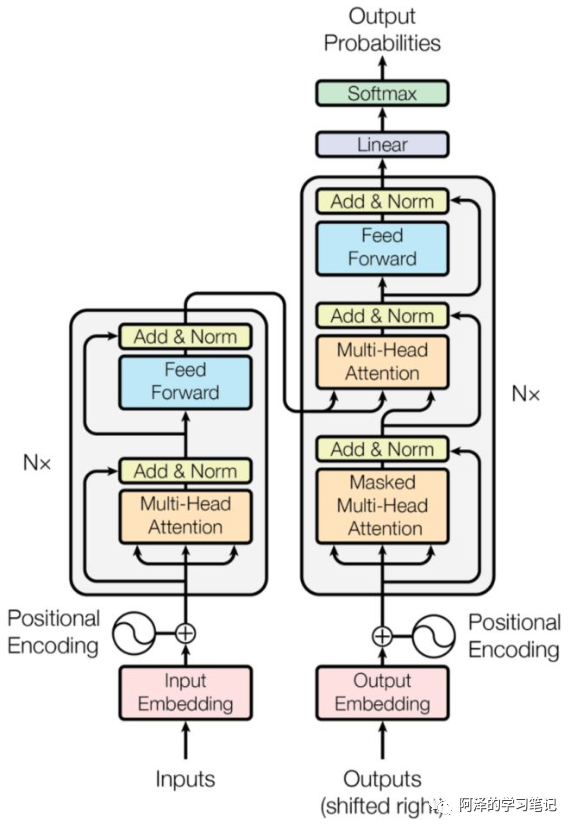
3.4 What is the structure of the Transformer encoder?
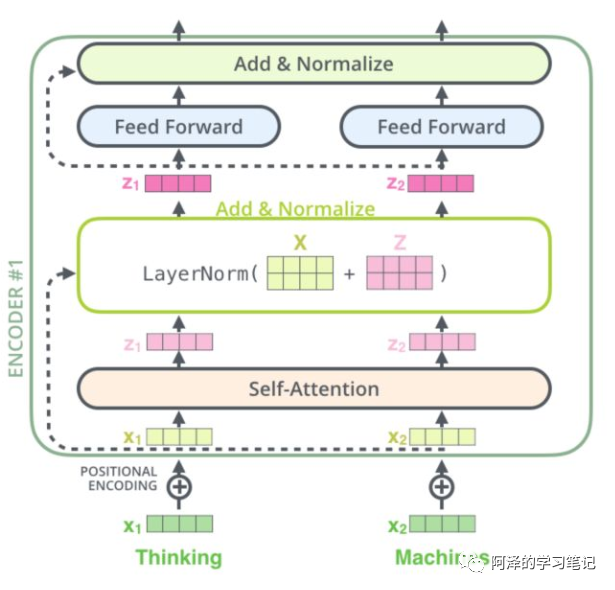
-
Characteristics: -
Similar to RNN and CNN, it can serve as a feature extractor; -
Composition structure introduction -
Embedding layer: Converts input into embedding vectors; -
Position encoding: Adds the position of the input to the input’s embedding to obtain the vector; -
Self-attention: Merges the input’s positional information with the input’s embedding information in the Self-Attention layer; -
Residual network: Added together and passed through the layer normalization layer; -
Feedforward network: After passing through a feedforward network and Add&Normalize (linear transformation + ReLU + linear transformation as below)
-
Example explanation (assuming a fixed sequence length of 100, and the input sequence is “I love China”): -
First requires “encoding”: mapping words to numbers, after encoding, since the sequence is not of fixed length, padding is needed. Then input the embedding layer, assuming the embedding dimension is 128, the input sequence dimension becomes 100*128; -
Next is “Position encoding”, in the paper, each position is directly mapped using cos-sin functions. This part does not need to be trained in the network as it is fixed. However, many papers now embed this part as well, such as in BERT’s model, whether to use encoding or embedding depends on the size of the corpus. If the corpus is large enough, embedding is used. The positional information is also mapped to 128 dimensions and added to the embedding from the previous step, resulting in output of 100*128; -
Through the “self-attention layer”: Assuming the vector’s last dimension is 64 (assuming no multi-head), this part outputs 100*64; -
Through the residual network: The sequence’s embedding vector is added to the previous self-attention vector; -
Through “layer norm”: There are two reasons for this: first, it is better for operation in self-attention; secondly, the actual sequence length keeps changing; -
Through “feedforward network”: The purpose is to increase non-linear expressiveness, as the previous structures are mostly simple matrix multiplications. If the hidden vector of the feedforward network is 512 dimensions, the final output structure will be 100*512;
3.5 What is the structure of the Transformer decoder?
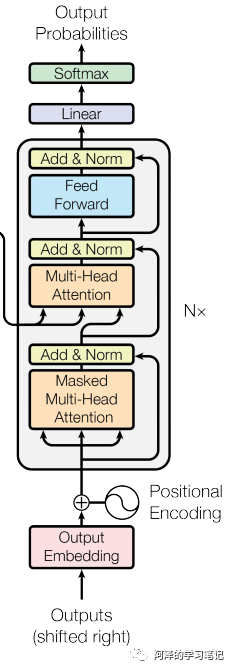
-
Characteristics: Similar to the encoder -
Composition structure introduction -
Masked layer: Ensures that the prediction at position i only relies on known outputs at positions less than i; -
Linear layer: Projects the vector produced by the decoder stack into a larger vector called the logit vector. This vector corresponds to the model’s output vocabulary; each value in the vector corresponds to the score of each word in the vocabulary; -
Softmax layer: Converts these scores into probabilities (all positive values sum to 1.0). Selects the unit with the highest probability and outputs the associated word for that time step
3.6 What is traditional attention?
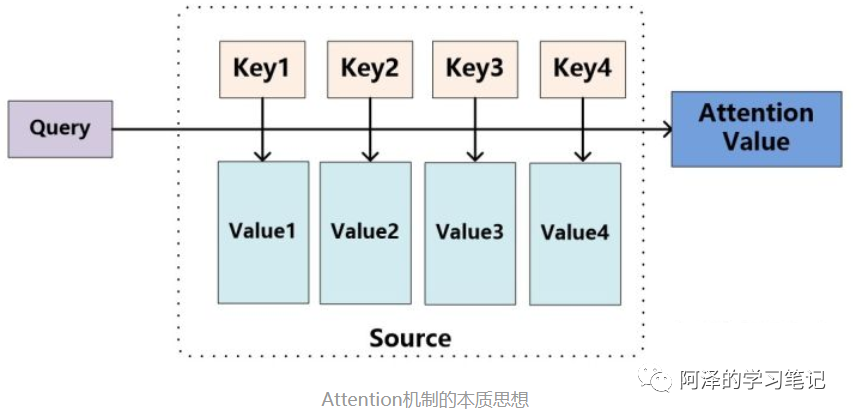
-
What is the attention mechanism? -
It is focusing attention on a specific point -
For example: When you are shopping in a supermarket, and a beautiful woman walks by, what do you do? That’s right, you focus your gaze [i.e., attention] on that beautiful woman, ignoring the surrounding environment. -
Thought process -
Input a query from the target; -
Calculate score weights: Compute the similarity or relevance between the query and each key to obtain the weight coefficients for each key corresponding to its value; -
Perform a weighted sum of the score weights and the values -
Core: -
The attention mechanism performs a weighted sum of the values of various elements in the source, while the query and key are used to calculate the weight coefficients for the corresponding values
Where represents the length of the source
-
Concept: -
The core of attention is to filter out a small amount of important information from a large amount of data; -
Specific operation: The weight coefficient of each value represents its importance;
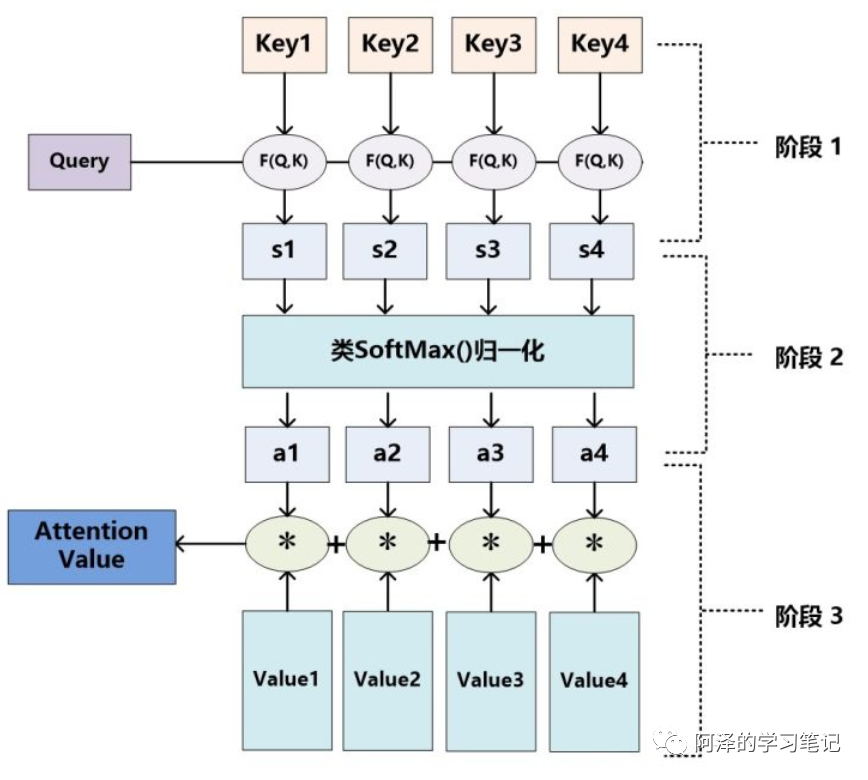
-
Specific process introduction
-
Formula introduction: The calculation result is the corresponding weight coefficient, and then a weighted sum can yield the attention value -
Reason: First, the score value distribution is too scattered, organizing the original calculated score into a probability distribution where the sum of all elements’ weights equals 1; second, the internal mechanism of SoftMax highlights the weights of important elements; -
Formula introduction -
Different functions or calculation methods can be used to calculate the similarity or relevance between the query and key
-
Methods used:
Vector dot product:
Cosine similarity calculation:
MLP network:
-
Step 1: Calculate weight coefficients
-
Step 2: Softmax normalization
-
Step 3: Weighted sum
-
Existing issues
-
Ignores the dependency relationships between words at the source or target end 【For the above example, focusing on the beautiful woman while ignoring the surrounding environment could lead to a mishap!】
3.7 What does self-attention look like?
-
Motivation -
The long-distance dependency problem present in CNN; -
The inability to parallelize present in RNN【Although it can alleviate the long-distance dependency problem to some extent】; -
Traditional Attention -
Method: Calculates attention based on hidden vectors from the source and target sides, -
Result: The dependency relationship between each word in the source and each word in the target 【Source -> Target】 -
Problem: Ignores the dependency relationships between words at the far end or target end -
Core idea: The structure of self-attention considers the representations of all other tokens in the sequence when calculating each token; -
Example: For the sequence “I love China”, when calculating the word “I”, it considers not only the embedding of the word itself but also the influence of other words on it. -
Purpose: To learn the dependency relationships between words within a sentence and capture the internal structure of the sentence.
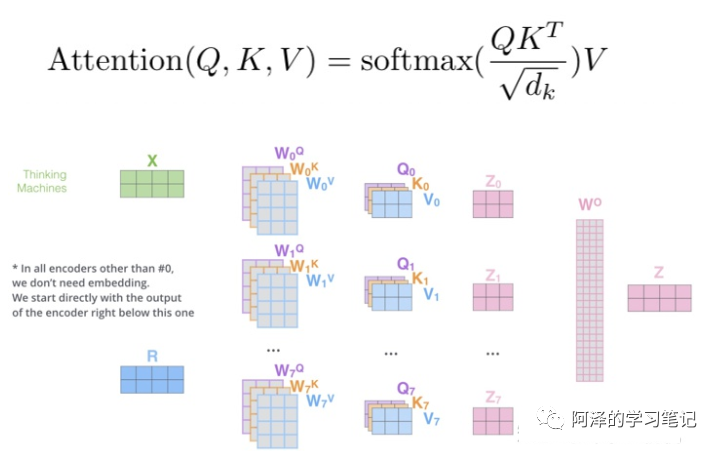
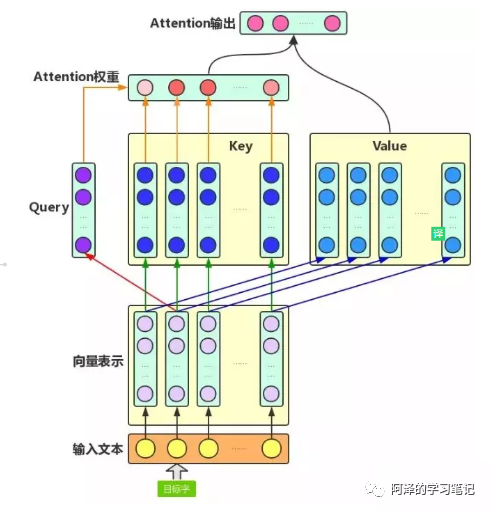
-
Steps
-
Weighted sum of the score weights and the V vectors of the surrounding context -
Purpose: To integrate the V of surrounding words into the original V of the target word -
After Softmax normalization; -
Multiply by ; -
Purpose: To act as a regulator, preventing the dot product from becoming too large. In fact, it is the last dimension of Q, K, and V; when becomes larger, also increases, which may push the Softmax function into a region of very small gradients; -
Query vector query multiplied by key; -
Purpose: To calculate the importance of other words to this word, i.e., the weight; -
Q: Query vector, the target word acts as Query; -
K: Key vector, each word in the context acts as Key; -
V: Value vector, the values of each word in the context; -
Embedding layer: Its purpose is to convert words into embedding vectors; -
Q, K, V vector calculations: Based on embedding and weight matrices, obtain Q, K, V; -
Weight score calculation: -
Scale operation: -
Softmax normalization: -
Calculation of the output of Attention: -
Example
-
The answers are the Q, K, and V in the article; these three vectors can all represent the word “I”, but each vector serves a different purpose. Q represents the query, when calculating the word “I”, it can represent “I” to perform dot product calculations with the K of other words to determine their importance to this word. Therefore, other words (including itself) use K as key; after the dot product calculation, we only obtain the weights of each word regarding the word “I”. We still need to multiply by the V vector of other words (including itself) to complete the calculation of the word “I”, which also completes the process of representing “I” with other words. -
Advantages
-
Captures the dependency relationships between words at the source and target ends -
Captures the dependency relationships between words at the source or target ends
3.8 How does self-attention solve the long-distance dependency problem?
-
Introduction: -
What is the long-distance dependency problem? -
Why can’t CNN and RNN solve the long-distance dependency problem? -
What solutions have been proposed previously? -
How does self-attention solve the long-distance dependency problem? -
In the previous question, we mentioned that both CNN and RNN face long-distance dependency problems when processing long sequences. So you might have the following questions:
Below, we will answer these questions one by one.
-
What is the long-distance dependency problem?
-
Introduction: For sequence problems, the output at time step t relies on previous inputs, i.e., it depends on , as the gap gradually increases, the information of becomes difficult to be learned by , which means it is hard to establish this long-distance dependency relationship. This is the long-distance dependency problem (Long-Term Dependencies Problem). -
Why can’t CNN and RNN solve the long-distance dependency problem?
-
RNN mainly learns (remembers) previous information through loops;
-
Problem: However, over time, you will encounter the “gradient vanishing or exploding” problem, which only allows you to establish short-distance dependency information.
-
Example: The learning pattern of RNN is similar to human memory; humans may remember things that happened in the short term very clearly, but as time passes, the memory of events that happened a long time ago becomes vague, just like your memories from childhood.
-
Solution: To address this issue, many variants of RNN were proposed later, such as LSTM and GRU, which selectively remember some important information by introducing gating mechanisms. However, this method can only alleviate the long-distance dependency problem to some extent, but cannot fundamentally solve it.
-
CNN mainly captures local information within sentences using convolution kernels; you can understand it as a “n-gram based local encoding method” for capturing local information.
-
Problem: Since it is an n-gram local encoding method, when the distance exceeds , it becomes difficult to learn the information;
-
Example: The n-gram method is similar to a person’s visual range; at each moment, a person’s visual range can only capture information within a certain range. For example, when you are looking ahead, you cannot pay attention to what is happening behind you unless you turn around.
-
CNN: Method for capturing information:
-
RNN: Method for capturing information:
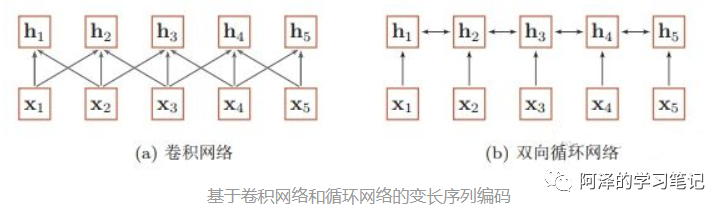
-
What solutions have been proposed previously? -
Increase the number of layers in the network: Use a deep network to obtain long-distance information exchange. -
Use fully connected networks: Model long distances through fully connected methods; but this raises two issues: 1. Cannot handle variable-length input sequences; 2. For different input lengths, the size of the connection weights also varies; -
Introduction: So what methods were mainly used to solve the problem previously? -
Solution:
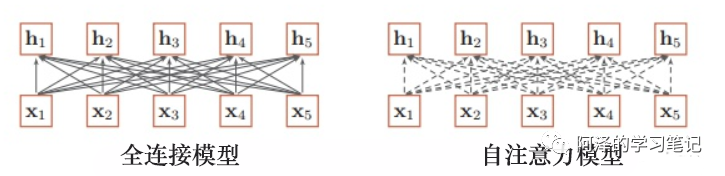
-
How does self-attention solve the long-distance dependency problem? -
Solution: Utilize attention mechanisms to dynamically generate different connection weights to handle variable-length information sequences. -
Specific introduction: For the current query, you need to perform dot products with all keys in the sentence and then apply Softmax to obtain the score (which can be understood as contribution) of all keys to the current query, and then perform weighted fusion with the value vectors of all words to enable the current word to learn information from other words in the sentence;
3.9 How is self-attention parallelized?
-
Introduction: -
In the previous question, we mainly discussed the long-distance dependency problems faced by CNN and RNN when processing long sequences, as well as how Transformers solve long-distance dependency issues. However, RNN also has another issue: the inability to parallelize. -
So how does Transformer achieve parallelization? -
How does Transformer achieve parallelization? -
Core: Self-attention -
Why can’t RNN parallelize: The reason is that RNN requires consideration of the information from during its calculations, making it impossible to compute from to ; -
Thought process: In self-attention, different queries can be computed in parallel within the sentence, as there are no sequential dependencies between each query, allowing the Transformer to parallelize;
3.10 How is multi-head attention resolved?
-
Thought process: -
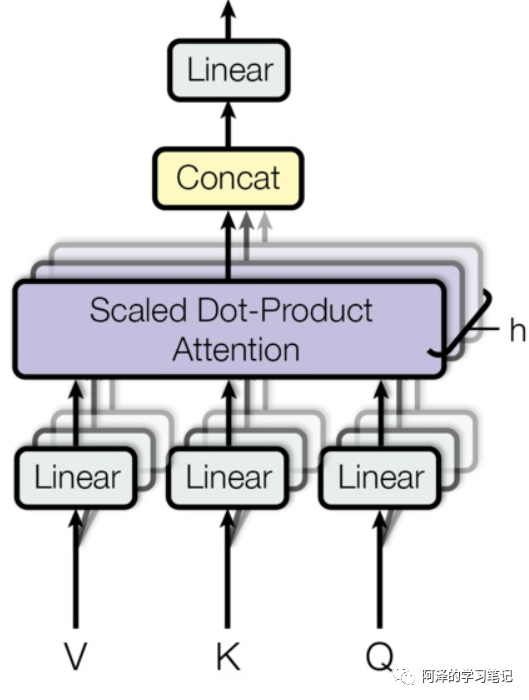
It is equivalent to an ensemble of different self-attentions. -
It involves performing self-attention n times, depending on the number of heads; the paper performed it 8 times. -
Steps: -
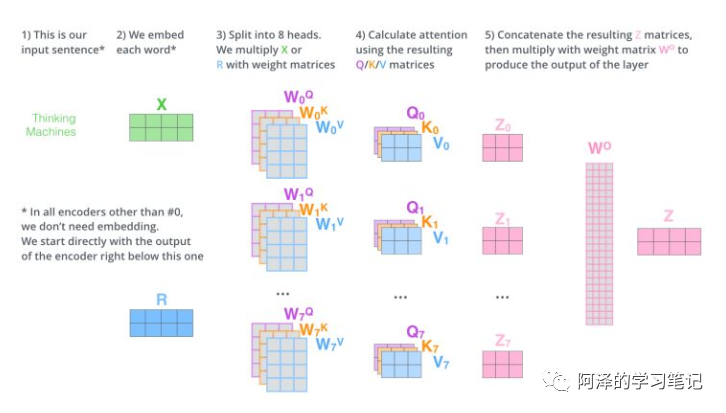
Step 1: Initialize N groups of matrices (the paper used 8 groups);
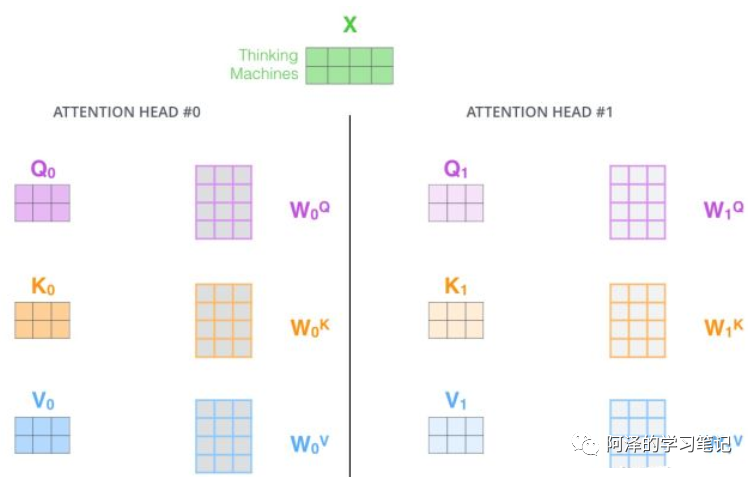
-
Step 2: Each group performs self-attention separately; -
Step 3: -
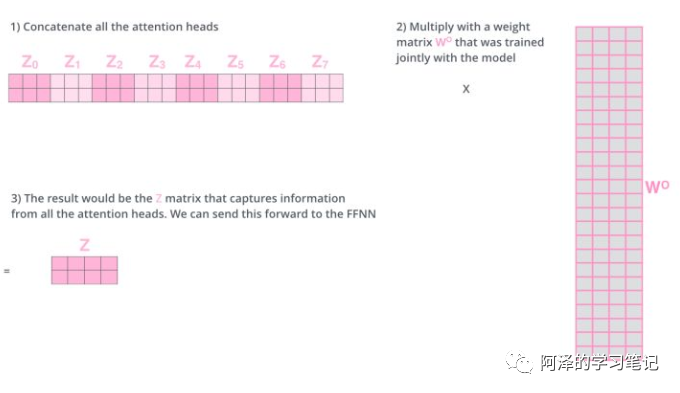
Each self-attention will produce a Z matrix, concatenate each Z matrix, -
Then multiply by a Wo matrix, -
To obtain a final matrix, which is the result of multi-head attention;
-
Problem: Multiple self-attentions yield multiple matrices, but the feedforward neural network cannot input 8 matrices; -
Goal: Reduce the 8 matrices to 1; -
Steps:
Finally, let’s look at the complete process:
Another representation:
3.11 Why add position embedding?
-
Issue: -
Introduction: Lack of a method to represent the order of words in the input sequence -
Explanation: Because the model does not include recurrence/convolution, it cannot capture the sequential order information. For example, if K and V are shuffled by rows, the result after attention remains the same. However, sequence information is crucial, representing the global structure, hence the positional information of the word tokens must be utilized. -
Purpose: To incorporate word order information so that attention can distinguish words in different positions -
Thought process: -
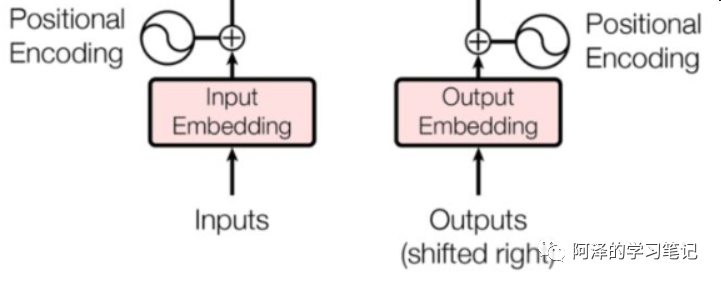
In the encoder and decoder layers, an additional vector Positional Encoding is added, which has the same dimension as the embedding, allowing the model to learn this value. -
Role of the position vector: -
Determines the position of the current word; -
Calculates the distance between different words in a sentence -
Steps: -
Number each position, -
Then each number corresponds to a vector, -
By adding the position vector to the word vector, positional information is introduced to each word.
-
The paper uses trigonometric functions for positional encoding. Benefits: -
Values are only in the range of [-1, 1] -
Easy to compute relative positions.
Note: represents the position of the current word in the sentence; represents the index of each value in the vector; at even positions: use sine encoding; at odd positions: use cosine encoding.
3.12 Why add residual modules?
-
Motivation: Because Transformers stack many layers, they are prone to gradient vanishing or exploding.
3.13 What is Layer Normalization? What is normalization?
-
Motivation: Because Transformers stack many layers, they are prone to gradient vanishing or exploding;
-
Reason: After data passes through the network layer, it is no longer normalized, and the bias will increase, so the data needs to be re-normalized;
-
Purpose: To perform normalization (normalization) on the input data before it enters the activation function, ensuring that the input data is transformed into a mean of 0 and a variance of 1 to avoid gradient vanishing or exploding problems due to the input data falling into the saturation zone of the activation function.
-
Introduction:
-
A way of normalization -
Describes the mean and variance for each sample【This differs from BN, as it calculates the mean and variance across batches】 -
Formula
-
LN calculation formula -
BN calculation formula
3.14 What is a Mask?
-
Introduction: Masks certain values’ information, preventing the model from accessing that information; -
Types: padding mask and sequence mask -
Scope: Only applies to the self-attention in the decoder -
Motivation: Unpredictability; -
Goal: The sequence mask ensures that the decoder cannot see future information. For a sequence, at time step t, the output of our decoding should only depend on outputs before time t, not on those after. Therefore, we need a method to hide information after time t. -
Method: Generate an upper triangular matrix where all upper triangular values are 0. Applying this matrix to each sequence achieves our goal. -
Scope: Each scaled dot-product attention -
Motivation: The issue of variable-length input sentences -
Method: Short sentences: apply 0 padding at the end; long sentences: only retain the left portion, discarding others -
Reason: The information contained in the padding positions contributes little to the model’s learning, so self-attention should discard learning from these positions; -
Method: Add a very large negative number (negative infinity) at these positions, causing the values at those positions to approach 0 after Softmax, utilizing padding masks to mark which values need processing; -
Padding mask -
Sequence mask
Note: In the scaled dot-product attention of the decoder, the attn_mask = padding mask + sequence mask; in the encoder’s scaled dot-product attention, the attn_mask = padding mask.
3.15 What problems exist with Transformers?
-
Introduction
-
Since Transformers are so powerful, do they also have shortcomings? -
Answer: Yes. -
Problem 1: Unable to handle ultra-long input issues well?
-
Solution 1: Truncate sentences (the Transformer processing method);
-
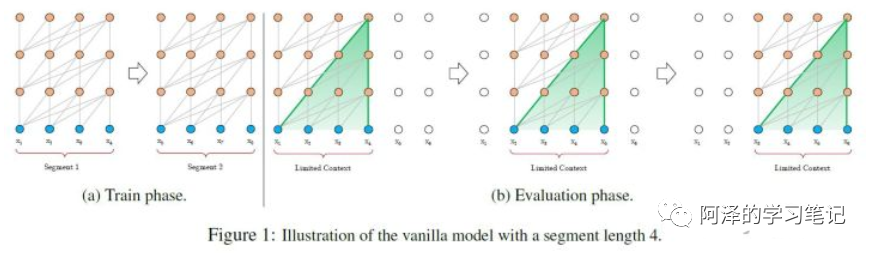
Solution 2: Divide sentences into multiple segments (Vanilla Transformer processing method);
Thought process: Divide the text into multiple segments; during training, each segment is processed separately;
Problem: Since segments are independently trained, the longest dependency relationship between different tokens depends on the segment length (as shown in diagram (a)); for efficiency, segments are divided based on fixed lengths without considering natural sentence boundaries, leading to semantically incomplete segments (as shown in diagram (a)); during prediction, fixed-length segments are computed, generally taking the hidden vector of the last position as output. To fully utilize contextual relationships, after each prediction, the entire sequence is moved one position to the right for another calculation, leading to very low computational efficiency (as shown in diagram (b));
-
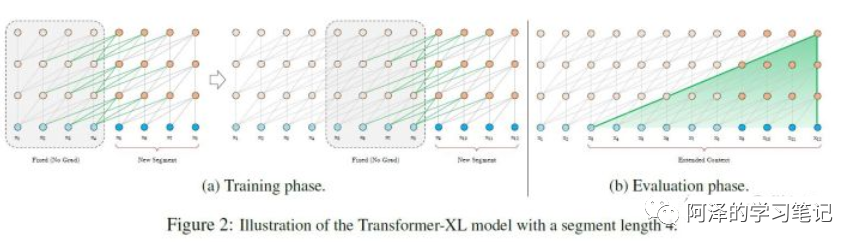
Solution 3: Segment-Level Recurrence (Transformer-XL processing method);
Thought process: When processing the current segment, “cache” and utilize the hidden vector sequences of all layers from the previous segment; the hidden vector sequences of the previous segment only participate in forward computation, not in backpropagation;
-
Introduction: Transformers fix the length of sentences;
-
Example: In BERT, the default input sentence length is 512;
-
For the length issue, the following handling is done: Shorter than 512: padding sentences; longer than 512:
-
Problem 2: Missing directional information and relative position? -
Example: As shown in the figure, the word “Inc” is likely preceded by an organization (ORG), and the word “in” is likely followed by a time or place (TIME); moreover, an entity should consist of consecutive words, so the highlighted “Louis Vuitton” will not form an entity with the highlighted “Inc”. However, the original Transformer cannot capture this information. -
Motivation: The absence of directional and positional information leads to poor performance of Transformers in NLP tasks, such as named entity recognition;
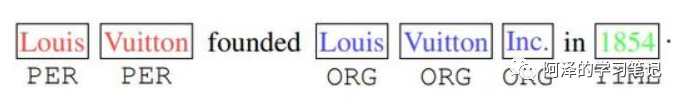
-
Solution: Refer to TENER: Adapting Transformer Encoder for Name Entity Recognition 【A summary of the paper will be provided later】
-
Problem 3: Lack of Recurrent Inductive Bias
-
Motivation: Inductive bias in learning algorithms can be used to predict outputs for inputs never encountered (see [10]). This is crucial for many sequence modeling tasks (such as those requiring modeling of input hierarchical structures or differing input length distributions during training and inference); recurrent inductive bias is essential 【Refer to the paper The Importance of Being Recurrent for Modeling Hierarchical Structure】 -
Problem 4: Transformers are not Turing complete: Simply put, they cannot solve all problems
-
Motivation: In Transformers, the number of sequential operations needed in a single layer (context for two symbols) is time, independent of the length of the input sequence. Thus, the total number of sequential operations is determined solely by the number of layers. This means that transformers cannot be computationally universal, i.e., they cannot handle certain inputs. For instance, if the input requires “processing each input element sequentially”, in such cases, for any given depth of the transformer, a length can be constructed; -
Problem 5: Transformers lack conditional computation
-
Motivation: During the encoding process in transformers, all input elements have the same computational load. For example, for the sentence “I arrived at the bank after crossing the river”, compared to “river”, more background knowledge is needed to infer the meaning of the word “bank”. However, the transformer applies the same computational load unconditionally to each word during the encoding of this sentence, making this process clearly inefficient. -
Problem 6: Transformers have excessive time and space complexity
-
Motivation: The self-attention used in Transformers exhibits time and space complexity that scales with the length n -
Solution: Linformer
3.16 How to code Transformers?
-
Finally, here’s a detailed explanation of the theory and source code from whalePaper member Yi Shen regarding Transformers;
-
Theory + practice, working never tires!
4. References
-
Detailed explanation of Transformer theory and source code -
Paper notes: Attention is all you need (Transformer) -
Deep learning – Paper reading – Transformer – 20191117 -
Detailed explanation of Transform (super detailed) Attention is all you need paper -
What mainstream attention methods are there? -
The Transformer trilogy -
Character-Level Language Modeling with Deeper Self-Attention -
Transformer-XL: Unleashing the Potential of Attention Models -
The Importance of Being Recurrent for Modeling Hierarchical Structure -
Linformer
Repository address sharing:
Reply "code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL 2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Yizhen Natural Language Processing - Pytorch group has officially been established! There are a lot of resources in the group, welcome everyone to join and learn!
Note: Please modify the remarks as [School/Company + Name + Direction] when adding.
For example - HIT + Zhang San + Dialogue System.
The account owner, WeChat merchants, please consciously avoid. Thank you!
Recommended reading:
Longformer: A Pre-trained Model Born for Long Documents Beyond RoBERTa
A Visual Understanding of KL Divergence
Top 100 Must-Read Papers in Machine Learning: Highly Cited, Comprehensive, and Wide Coverage | GitHub 21.4k Stars