Editor: Editorial Department
[New Intelligence Guide] The production-grade Mamba model with 52B parameters is here! This powerful variant, Jamba, has just broken the world record, capable of directly competing with Transformers, featuring a 256K ultra-long context window and a threefold throughput increase, with weights available for free download.
The Mamba architecture, which previously ignited the AI community, has launched an even more powerful variant today!
The AI unicorn AI21 Labs has just open-sourced Jamba, the world’s first production-grade Mamba model!
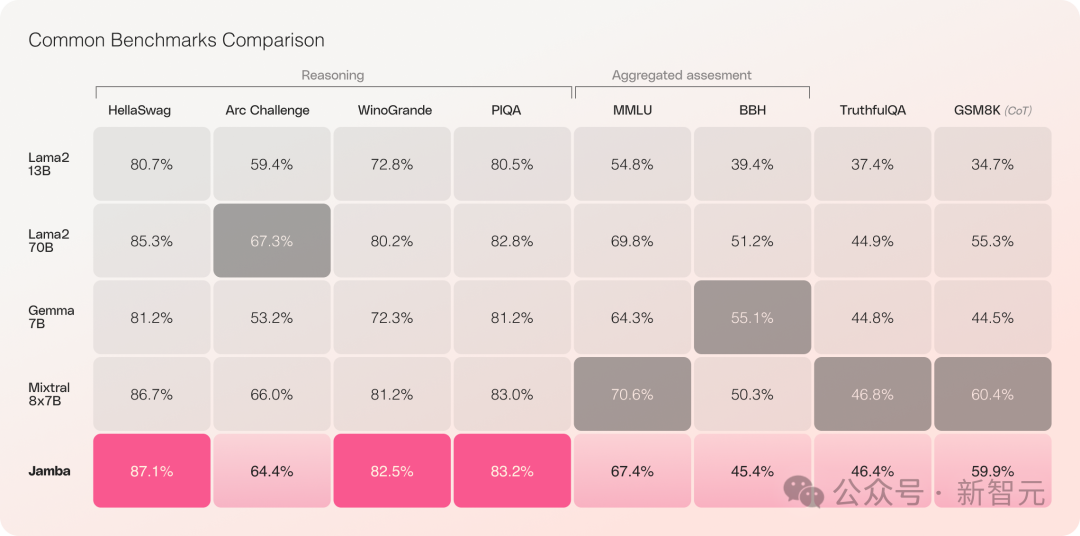
Jamba has performed exceptionally well in multiple benchmark tests, standing shoulder to shoulder with the strongest open-source Transformers.
Especially in comparison with the best-performing MoE architecture, Mixtral 8x7B, they have had their victories over each other.
Specifically, it —
-
is the first production-grade Mamba model based on the new SSM-Transformer hybrid architecture
-
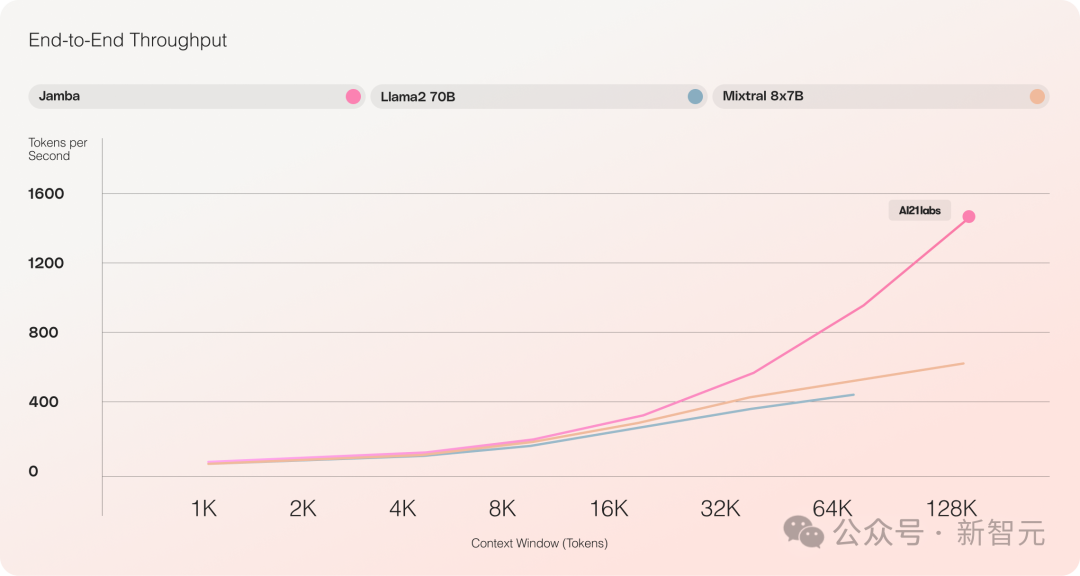
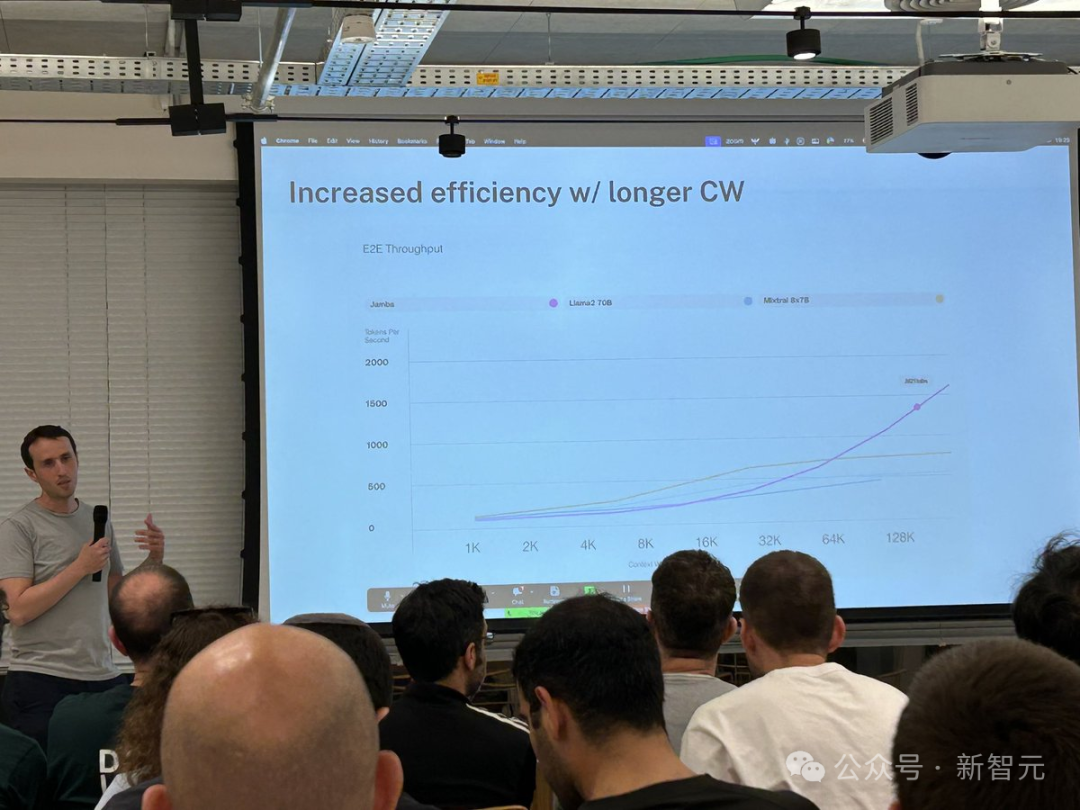
compared to Mixtral 8x7B, the throughput for long text processing has increased threefold
-
achieves a 256K ultra-long context window
-
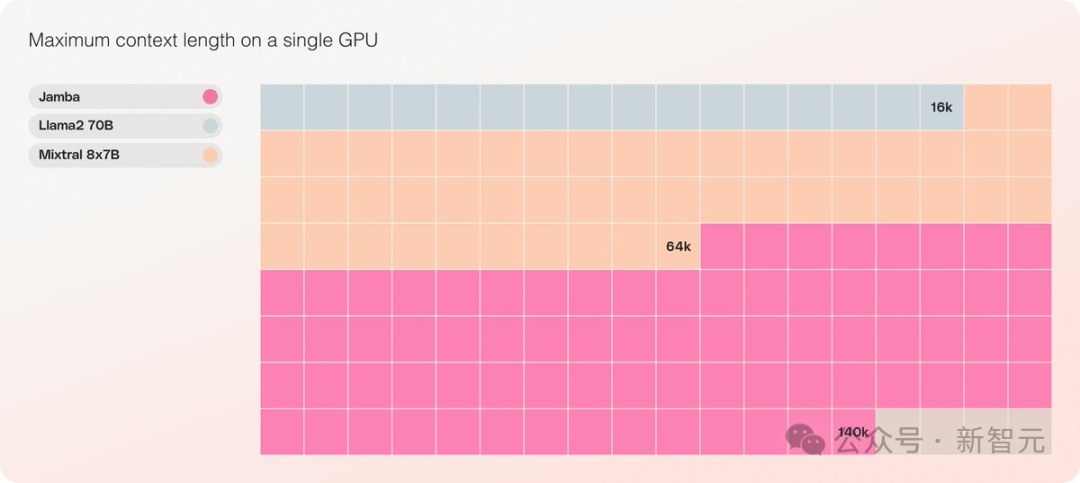
is the only model of its size that can handle 140K context on a single GPU
-
released under the Apache 2.0 open-source license, with weights available
The previous Mamba was limited to 3B parameters, leading to doubts about its ability to take over the mantle of Transformers, while other linear RNN family models like RWKV and Griffin only scaled up to 14B.
— Jamba has now directly scaled to 52B, allowing the Mamba architecture to finally compete directly with production-level Transformers.
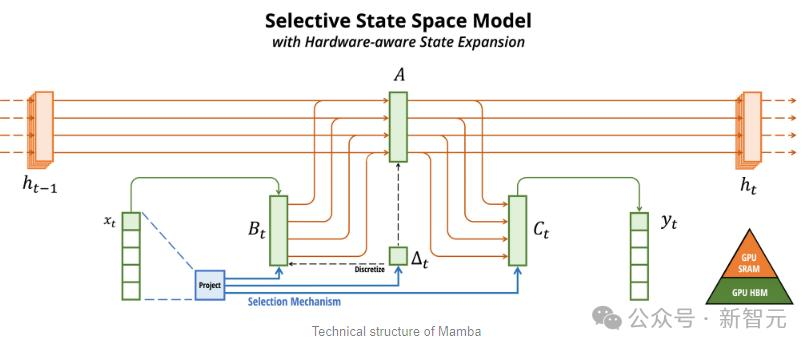
Jamba builds upon the original Mamba architecture, integrating the advantages of Transformers to compensate for the inherent limitations of the state space model (SSM).
This can be seen as a new architecture — a hybrid of Transformer and Mamba, importantly, it can run on a single A100.
It offers an ultra-long context window of up to 256K, capable of running 140K context on a single GPU, and its throughput is three times that of Transformers!
Compared to Transformers, it’s astonishing to see how Jamba scales to such a large context length.
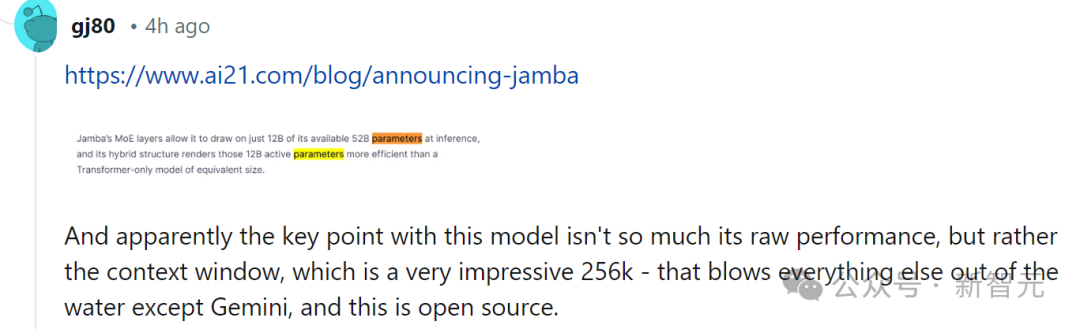
Jamba adopts the MoE scheme, with 12B of its 52B being active parameters; the current model is open-sourced under Apache 2.0, and weights can be downloaded on huggingface.

Model download: https://huggingface.co/ai21labs/Jamba-v0.1
The release of Jamba marks two important milestones for LLMs:
First, it successfully combines Mamba with Transformer architecture; second, it successfully elevates the new type of model (SSM-Transformer) to production-level scale and quality.
Currently, the strongest large models are all based on Transformers, although everyone recognizes the two main drawbacks of the Transformer architecture:
High memory usage: The memory consumption of Transformers scales with context length. Running long context windows or large parallel batches requires significant hardware resources, limiting large-scale experimentation and deployment.
As context grows, inference speed slows down: The attention mechanism of Transformers leads to a quadratic growth in inference time relative to sequence length, causing throughput to decrease. Since each token depends on the entire preceding sequence, achieving ultra-long contexts becomes quite challenging.
Last year, two experts from Carnegie Mellon and Princeton proposed Mamba, igniting hope among researchers.
Mamba is based on SSM, enhancing the capability to selectively extract information and employing hardware-efficient algorithms, effectively resolving the issues present in Transformers.
This new field has quickly attracted numerous researchers, with a surge of applications and improvements related to Mamba appearing on arXiv, such as using Mamba for vision tasks — Vision Mamba.
It must be said that the current research field is extremely competitive; it took three years to bring Transformers into vision (ViT), but it only took a month for Mamba to evolve into Vision Mamba.
However, the original Mamba had a relatively short context length, and the model itself did not scale up significantly, making it difficult to surpass SOTA Transformer models, especially in recall-related tasks.
Jamba then takes a step further by integrating Joint Attention and Mamba architecture, combining the advantages of Transformers, Mamba, and Expert Mixture (MoE), while optimizing memory, throughput, and performance.
Jamba is the first hybrid architecture to reach production-level scale (52B parameters).
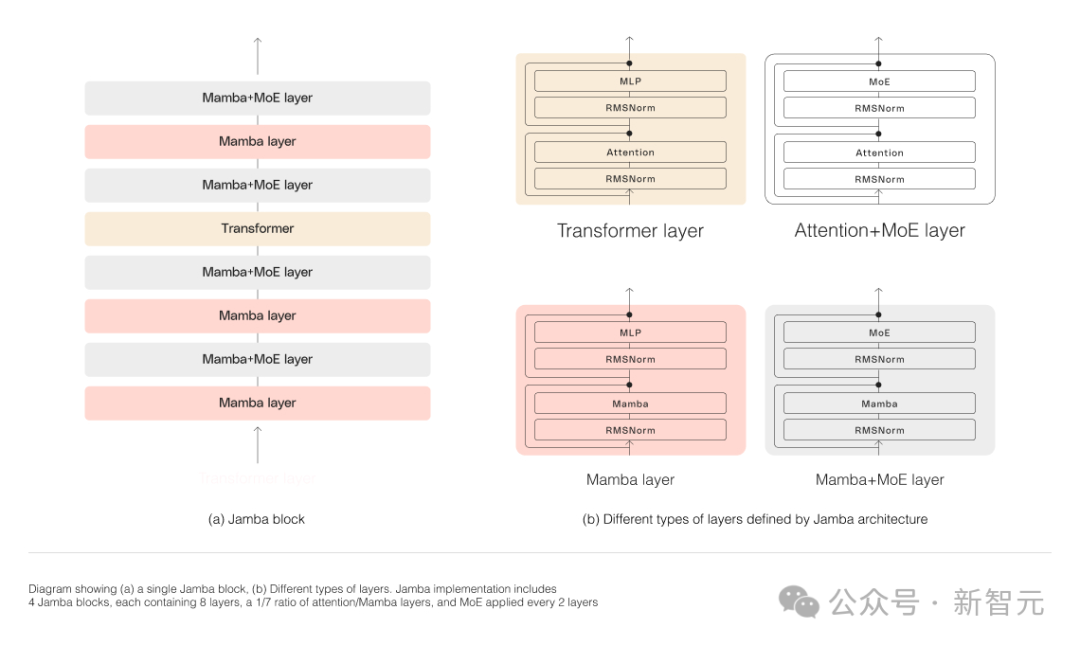
As shown in the figure below, AI21’s Jamba architecture employs a blocks-and-layers approach, enabling Jamba to successfully integrate both architectures.
Each Jamba block contains an attention layer or a Mamba layer, followed by a multi-layer perceptron (MLP).
The second feature of Jamba is the use of MoE to increase the total number of model parameters while simplifying the number of active parameters used during inference, thereby enhancing model capacity without increasing computational demands.
To maximize model quality and throughput on a single 80GB GPU, researchers optimized the number of MoE layers and experts used, leaving ample memory for common inference workloads.
Compared to similar-sized Transformer-based models like Mixtral 8x7B, Jamba achieves a threefold acceleration in long contexts.
Jamba will soon join the NVIDIA API directory.
New contenders in long contexts
Recently, major companies have been competing in long contexts.
Models with smaller context windows often forget recent conversation content, while those with larger contexts avoid this pitfall, better grasping the data stream they receive.
However, models with long context windows are often computationally intensive.
The generative model from startup AI21 Labs proves that this is not the case.
When running on a single GPU with at least 80GB of memory (like A100), Jamba can handle up to 140,000 tokens.
This is equivalent to about 105,000 words, or 210 pages, the length of a moderately sized novel.
In contrast, Meta Llama 2 has a context window of only 32,000 tokens, requiring 12GB of GPU memory.
By today’s standards, this context window is clearly on the smaller side.
In response, some netizens immediately expressed that performance is not the key; the crucial point is that Jamba has a context of 256K, which no one else has besides Gemini, — and Jamba is open-source.
The True Uniqueness of Jamba
On the surface, Jamba may not seem remarkable.
Whether it’s the currently popular DBRX or Llama 2, there are now many generative AI models available for free download.
However, Jamba’s uniqueness lies beneath the model: it simultaneously combines two model architectures — Transformer and State Space Model SSM.
On one hand, Transformer is the preferred architecture for complex reasoning tasks. Its defining feature is the “attention mechanism.” For each input data point, Transformer weighs the relevance of all other inputs and extracts from them to generate output.
On the other hand, SSM combines several advantages of earlier AI models, such as recurrent neural networks and convolutional neural networks, allowing it to handle long sequence data with greater computational efficiency.
Although SSM has its own limitations, some early representatives, like Mamba proposed by Princeton and CMU, can produce outputs larger than Transformer models and perform better in language generation tasks.
Regarding this, Dagan, the product lead at AI21 Labs, stated —
While there are some preliminary examples of SSM models, Jamba is the first commercially scalable model.
In his view, Jamba not only offers innovative and interesting possibilities for further community research but also provides immense efficiency and throughput potential.
Currently, Jamba is released under the Apache 2.0 license, with few usage restrictions but not for commercial use. Subsequent fine-tuned versions are expected to be released within weeks.
Even though it is still in the early stages of research, Dagan asserts, Jamba undoubtedly showcases the immense potential of SSM architecture.
The additional value of this model — whether due to its size or architectural innovations — can be easily installed on a single GPU.
He believes that as Mamba continues to be refined, performance will further improve.
https://www.ai21.com/blog/announcing-jamba
https://techcrunch.com/2024/03/28/ai21-labs-new-text-generating-ai-model-is-more-efficient-than-most/