
Feng Se from Aofeisi Quantum Bit | Public Account QbitAI
Exciting news! The first project to truly scale the popular Mamba architecture to a sufficiently large size has arrived.
52 billion parameters, still using the Mamba+Transformer hybrid architecture.
Its name is Jamba.

By taking the strengths of both architectures, it achieves both model quality and efficiency—high throughput when needed, and low memory usage when required.

Initial benchmarks show:
-
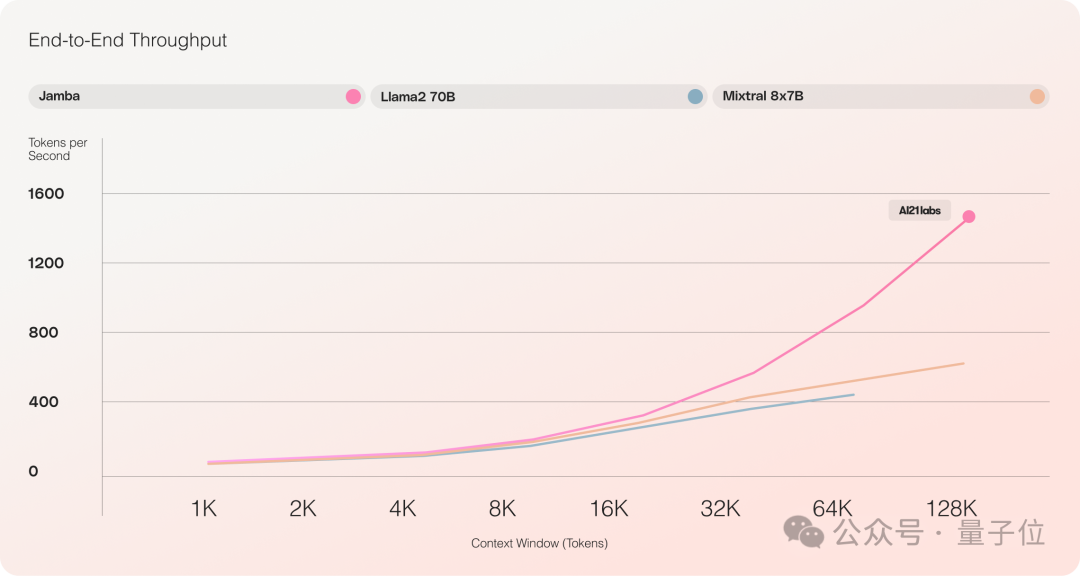
Jamba’s overall performance is close to Mixtral 8x-7B, but its throughput is three times that when processing 128k long contexts.
-
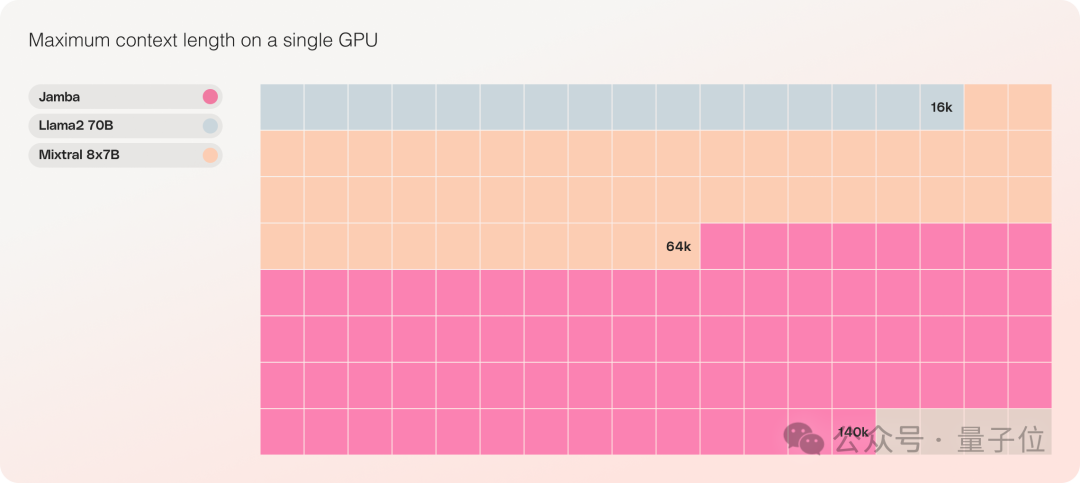
It supports a total of 256k context, while a single A100 GPU can handle 140k, making it the most efficient and economical model of its scale.
This achievement comes from the Israeli AI company AI21labs.
The original author of Mamba was also excited to share the news:
Absolutely a “big news”.

Mamba and Transformer Combined
The Mamba proposed by CMU and Princeton University solves the limitations of the Transformer (as the inference context gets longer, the model’s memory consumption increases while the inference speed slows down, leading to huge computational costs).
However, it also has its own disadvantages—
Without considering the entire context, Mamba’s output quality is poor, especially in recall-related tasks.
In the spirit of “wanting both,” Jamba emerges to provide a win-win solution.
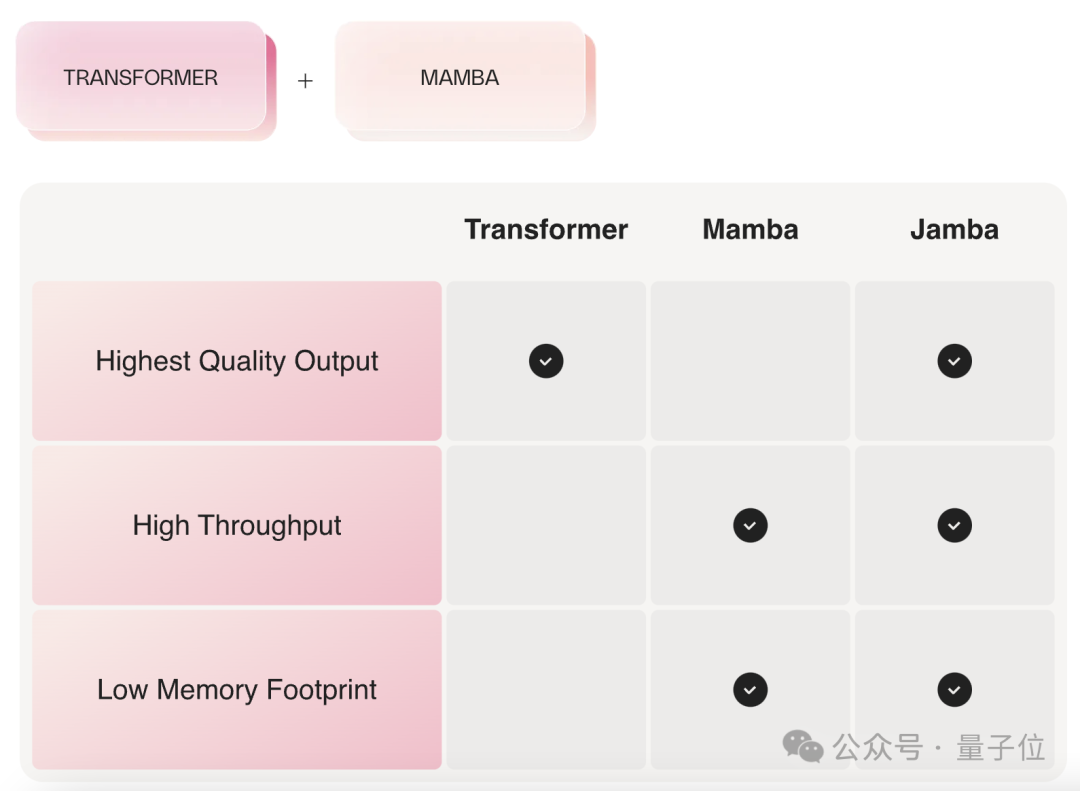
Jamba consists of Transformer, Mamba, and MoE layers, optimizing memory, throughput, and performance simultaneously.
As shown in the figure below, to integrate the two architectures, Jamba adopts an innovative blocks-and-layers combination approach.
In simple terms, each Jamba block contains either an attention layer or a Mamba layer, followed by a multi-layer perceptron (MLP), ensuring a ratio of one Transformer layer for every eight layers.
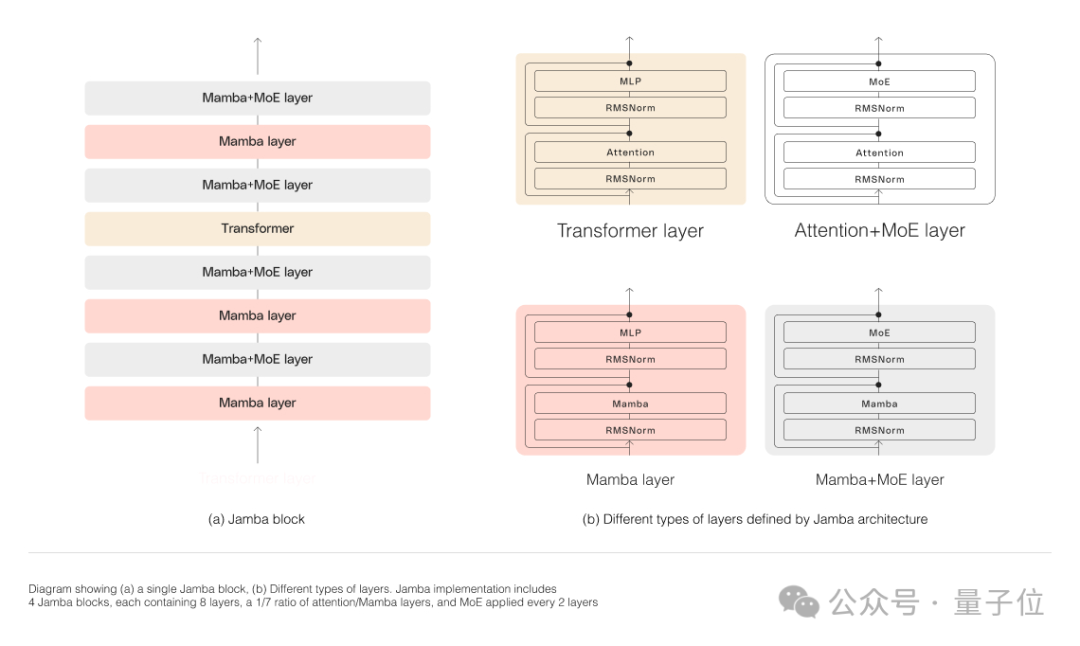
Furthermore, Jamba uses MoE to increase the total number of model parameters while simplifying the number of active parameters used during inference.
The final model capacity has increased without a corresponding increase in computational demands.
To maximize model throughput on a single GPU (80GB), Jamba also optimizes the number of MoE layers and experts used, leaving enough memory for daily inference workloads.
It is worth mentioning that during inference, Jamba’s MoE layer only requires 12 billion of the 52 billion available parameters to maintain efficiency compared to similarly sized Transformer-only models.
Previously, attempts to scale Mamba did not exceed 3 billion parameters.
Thus, besides successfully combining Mamba and Transformer, Jamba also achieves a second major accomplishment:
It is the first hybrid architecture to reach production-level scale and quality in its class (SSM mixed Transformer) (ps. Mamba is a type of state space model SSM).
Throughput and Efficiency Up
Preliminary evaluations show that Jamba excels in key metrics such as throughput and efficiency.
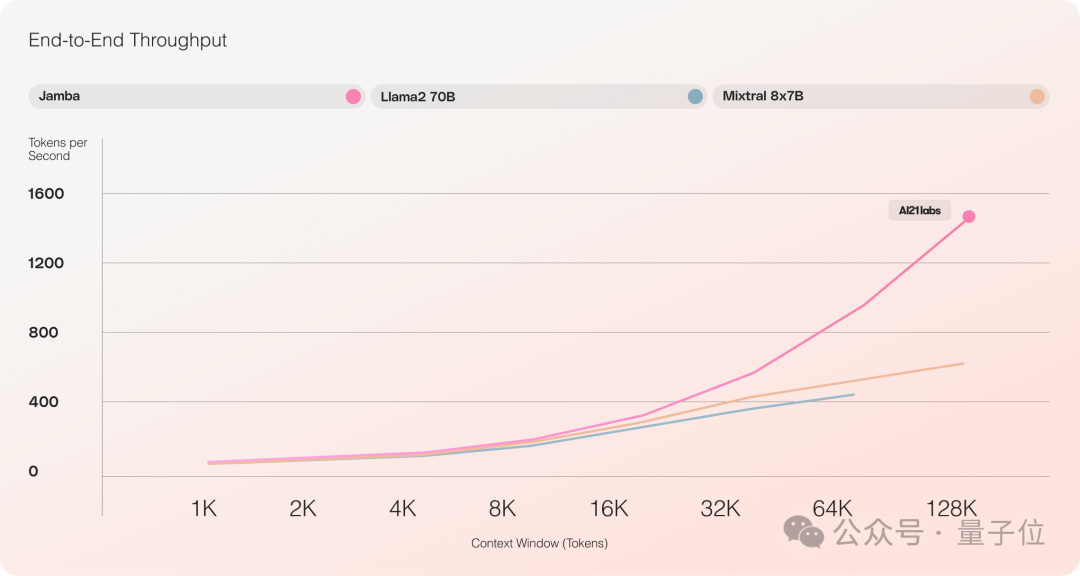
First, Jamba can provide three times the throughput in long contexts, outperforming Transformer models of similar size like Mixtral 8x7B.
As shown in the figure below, when the context window reaches 128k, Jamba’s tokens per second are nearly 1500, while the best-performing Mixtral 8x7B is only about 500.
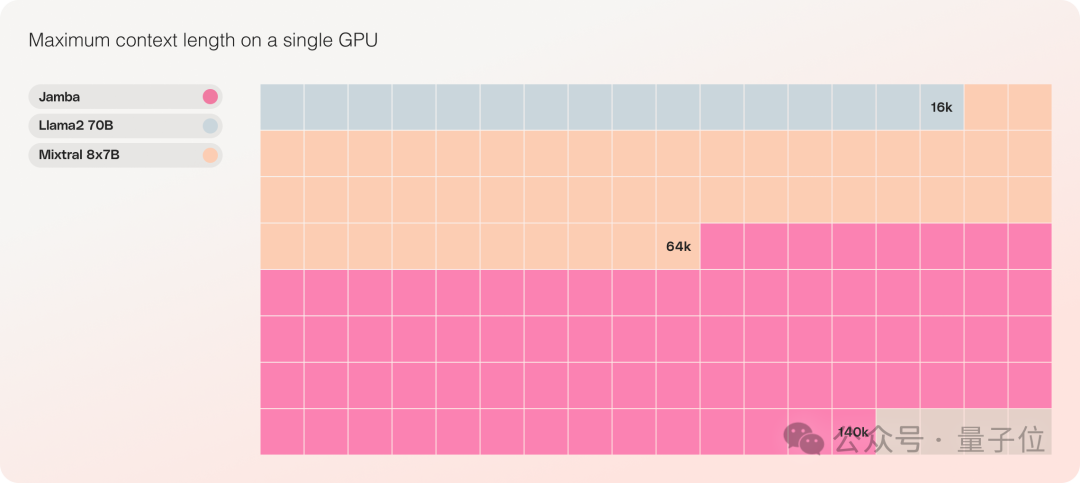
Second, on a single GPU, Jamba can accommodate up to 140k contexts, making it economical and efficient.
In contrast, Mixtral 8x7B supports only 64k, and Llama2 70B only 16k.
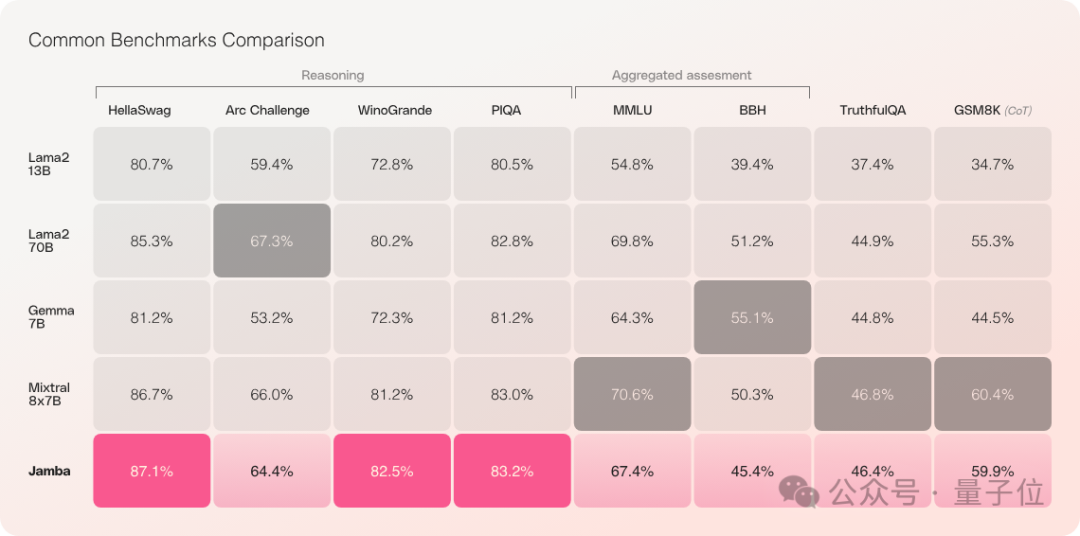
Third, the output quality of Jamba has also been ensured.
In a series of inference benchmarks, it achieved state-of-the-art (SOTA) performance in three out of four tests. Additionally, in benchmarks like GSM8K, Jamba performed comparably to SOTA models, even if it did not take the lead.
Overall, Jamba’s performance is close to that of Mixtral 8x7B.
Finally, the authors remind us not to forget that these are just the initial results after modifications, and there is still much room for optimization (such as MoE parallelization and faster Mamba implementations). Therefore, performance will improve further.
Good news: Jamba is now live on Hugging Face and notably: uses Apache-2.0 license.
(The instruction version of Jamba will soon be available on the AI21labs platform.)
Internet users are moved to tears after reading this.

Link: https://huggingface.co/ai21labs/Jamba-v0.1
References: [1] https://www.ai21.com/blog/announcing-jamba [2] https://www.ai21.com/jamba [3] https://twitter.com/AI21Labs/status/1773350888427438424?s=20 [4] https://twitter.com/tri_dao/status/1773418926518734957?s=20
— The End —
Registration for selection is about to end!
AIGC Companies & Products to Watch in 2024


China AIGC Industry Summit “Hello, New Applications!” is now open for registration! Click to register for the conference. The summit will also be live-streamed ⬇️
Click here👇 to follow me and remember to star it
One-click triple connection: “Share”, “Like” and “See”
Cutting-edge technology developments every day ~
