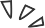Transformer Challenged!
In June 2017, eight Google researchers published a groundbreaking paper titled “Attention is All You Need”.

It is called groundbreaking because this paper proposed a new neural network architecture – the Transformer, which opened a new era of generative artificial intelligence and large models.
The advantage of the Transformer architecture is its ability to perform parallel computation, capture long-distance dependencies, and ease of scaling and optimization. However, it also has a significant drawback: the computational load of the self-attention mechanism grows quadratically with the increase in context length, leading to reduced computational efficiency.
To address this issue, researchers have proposed several optimization methods, such as sparse attention and hierarchical attention, to reduce computational complexity. However, they still have some limitations.
For example, sparse attention may lead to information loss because it only focuses on part of the input elements, while hierarchical attention may perform poorly in handling long-distance dependencies.
To further enhance computational efficiency and model performance, researchers continue to explore other optimization methods.
Recently, researchers from Carnegie Mellon University (CMU) and Princeton University released a new architecture called Mamba – Selective State Space Model.
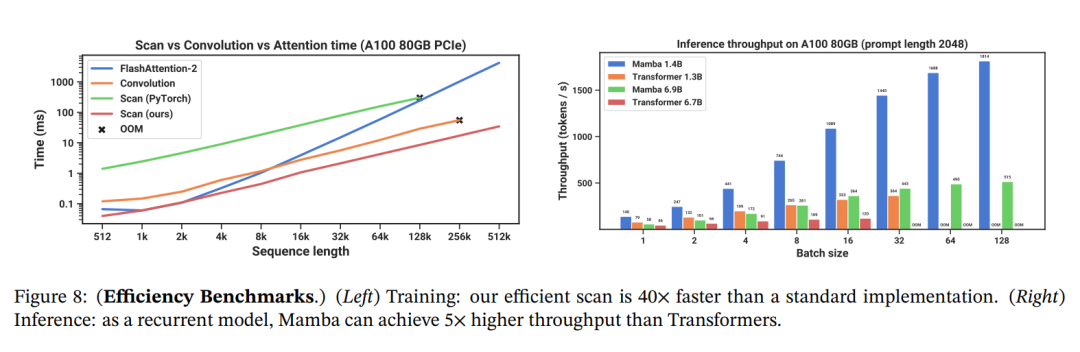
This architecture demonstrates performance comparable to Transformer in language modeling tasks while having the advantage of linear scalability. Compared to Transformer models, Mamba achieves up to 5 times throughput improvement during inference.
First author Albert Gu also stated that Mamba has already surpassed Transformer in some aspects.

The main innovation of Mamba lies in its use of an architecture called Selective SSM (Selective Structured State Spaces).
This architecture is a simplified and generalized version of the S4 architecture (Structured State Spaces for Sequence Modeling) previously led by Albert Gu.
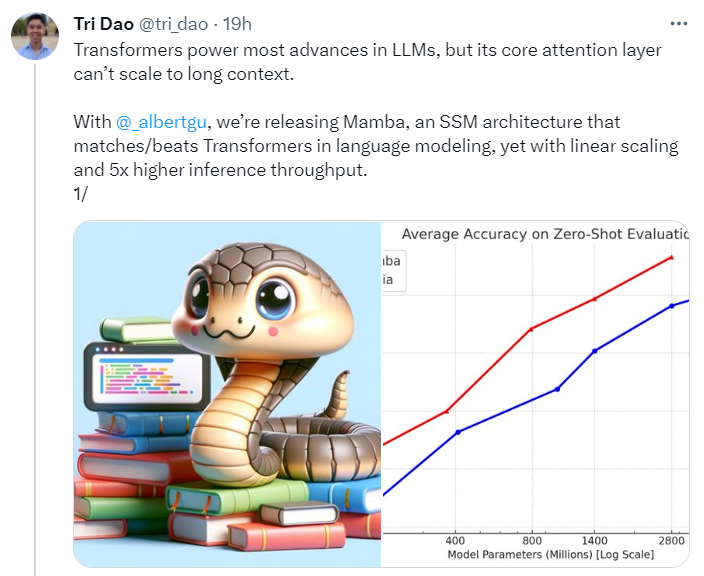
The Selective SSM architecture can selectively decide to pay attention to or ignore incoming inputs, achieving more efficient sequence modeling.

This small change – allowing only certain parameters to be a function of the input – enables it to immediately tackle interesting tasks that previous models struggled with.
As a core general sequence model, Mamba exhibits state-of-the-art performance across multiple modalities (such as language, audio, and genomics).

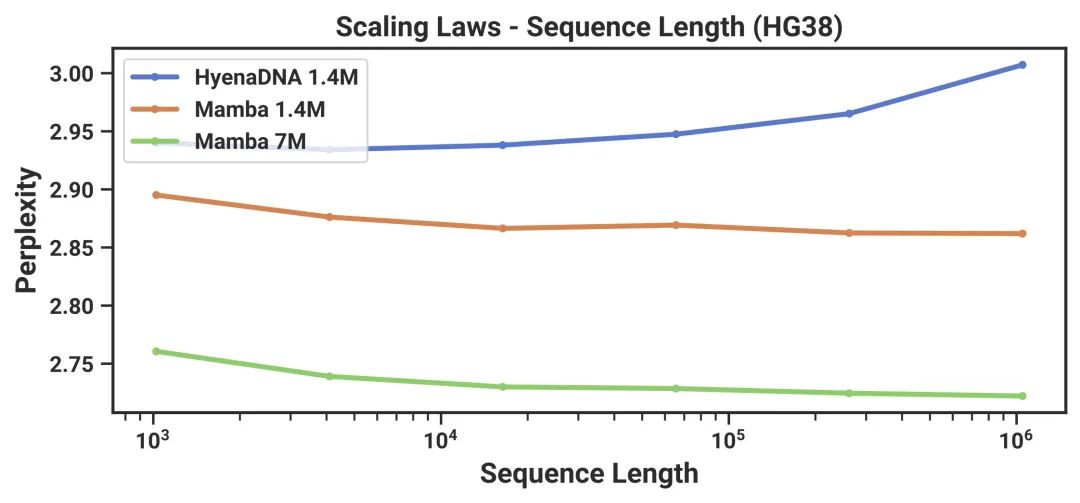
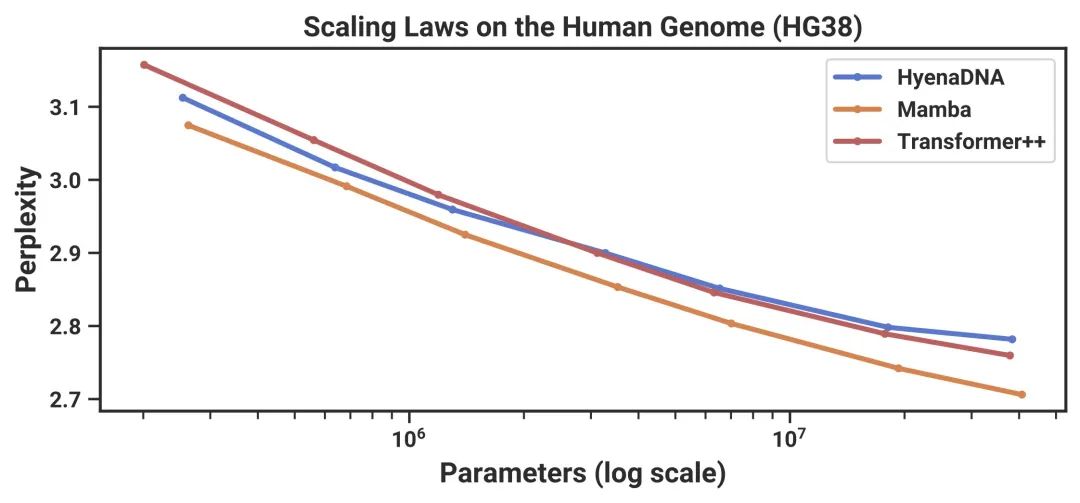
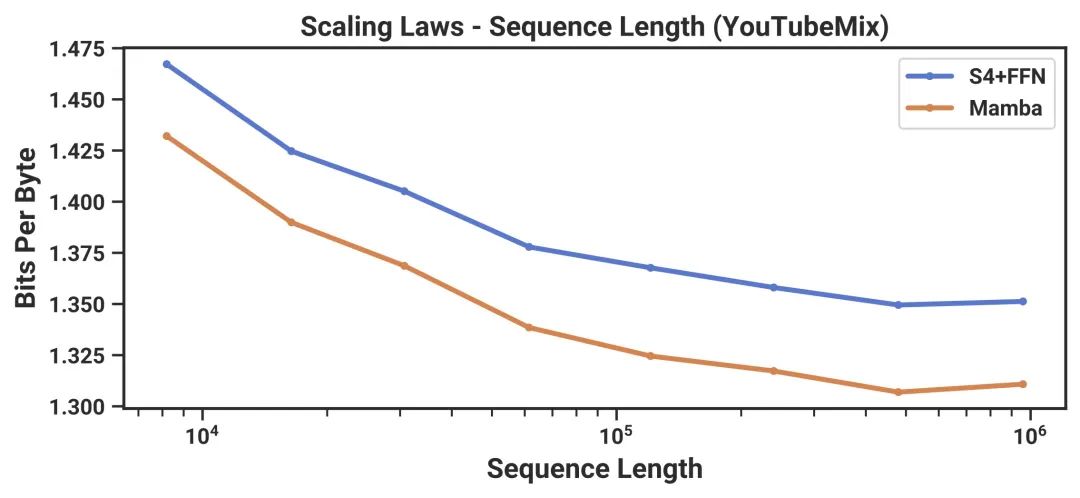
In the field of language modeling, both in pre-training and downstream evaluation, the Mamba-3B model outperforms similarly sized Transformer models and can compete with Transformer models that are twice its size.
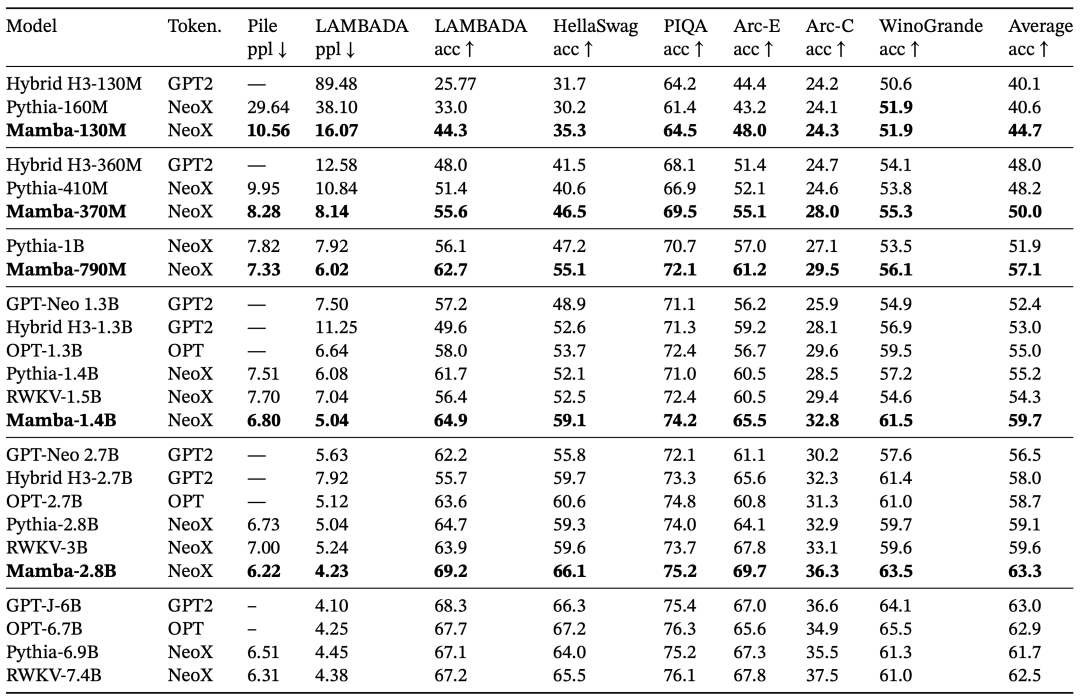
Compared to similarly sized Transformers, Mamba has 5 times the generation throughput.
Seeing Mamba’s performance, Abacus.AI’s CEO Bindu Reddy stated that Mamba challenges the dominance of Transformer.
Regarding why it is called Mamba, Albert Gu provided several reasons.
Team Introduction
The author team of this paper is relatively small, consisting of two outstanding scholars.

One of them is Albert Gu, an assistant professor in the Machine Learning Department at Carnegie Mellon University, who has extensive research experience in machine learning and natural language processing.

The other author is Tri Dao, who is currently the Chief Scientist at Together.AI and will soon become an assistant professor in the Computer Science Department at Princeton University. Tri Dao has profound knowledge in computer science, especially in natural language processing and artificial intelligence.