New Intelligence Report
Source: Microsoft
Editor: LRS, Xiao Yun
[New Intelligence Guide] Microsoft has published a new paper on arxiv, bringing CNN into Transformer to simultaneously consider global and local information.
In the development of computer vision technology, the most important model is the Convolutional Neural Network (CNN), which serves as the foundation for other complex models.
CNN has three important characteristics: a certain degree of rotation and scale invariance; weight sharing and local receptive fields; and a hierarchical structure that captures features from details to the whole.
These characteristics make CNN very suitable for computer vision tasks and establish it as the cornerstone of computer vision in the era of deep learning. However, the detail-capturing ability of CNN results in a weaker ability for global modeling.
Thus, how to enable CV models to capture global features has gradually become a research hotspot.
Can NLP models solve CV problems?
In 2017, the Transformer emerged, claiming that Attention is All You Need! Subsequently, BERT-like models dominated major NLP rankings, constantly approaching and surpassing human performance.
In 2020, Google Brain researchers introduced the Vision Transformer (ViT), applying the Transformer to the CV field with minimal modifications.
The dynamic attention mechanism and global modeling capability of Transformer enable ViT to demonstrate strong feature learning capabilities after extensive pre-training.
However, ViT is designed without fully utilizing the spatial information of visual signals, still needing to rely on position embedding in Transformer to compensate for the loss of spatial information.
Visual signals possess strong 2D structural information and have a strong correlation with local features, yet this prior knowledge is not utilized in the design of ViT.
The design of CNN can effectively compensate for these shortcomings in ViT, or it can be said that the design of ViT compensates for the weak global modeling ability of CNN.
This paper proposes a novel foundational network called Convolutional Vision Transformers (CvT), which combines the dynamic attention mechanism and global modeling ability of Transformers with the local capturing ability of CNN, integrating both local and global modeling capabilities.
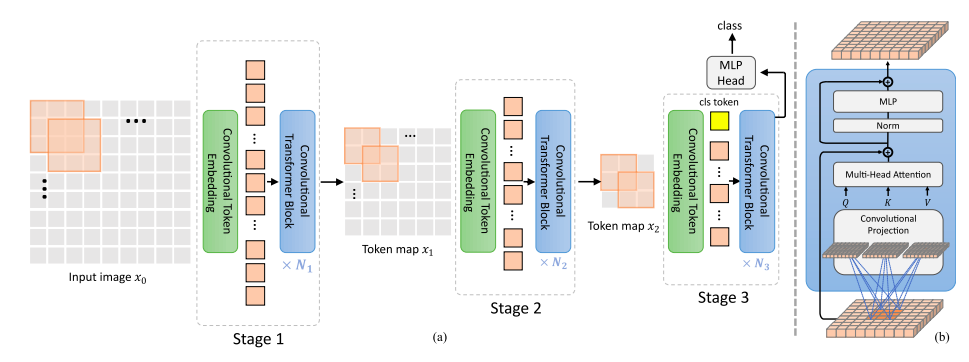
CvT features a hierarchical design structure, where at each level, 2D images or tokens are generated or updated into feature vectors through Convolutional Embedding.
Each layer includes N typical Convolutional Transformer Blocks, replacing linear transformations with convolutional transformations as input to the multi-head attention mechanism, followed by layer normalization.
Convolutional Projection allows the CvT network to maintain the spatial structural information of image signals, enabling tokens to better utilize the local information correlation of image data while also modeling global information through the attention mechanism.
The flexibility of convolution operations allows us to set the stride of convolution operations to downsample keys and values, further enhancing the computational efficiency of the Transformer structure.
Convolutional Embedding and Convolutional Projection fully utilize the spatial characteristics of visual signals, so in the structure of CvT, spatial information does not require position embedding, making CvT more flexible for various downstream tasks in computer vision, such as object detection and semantic segmentation.
Performance
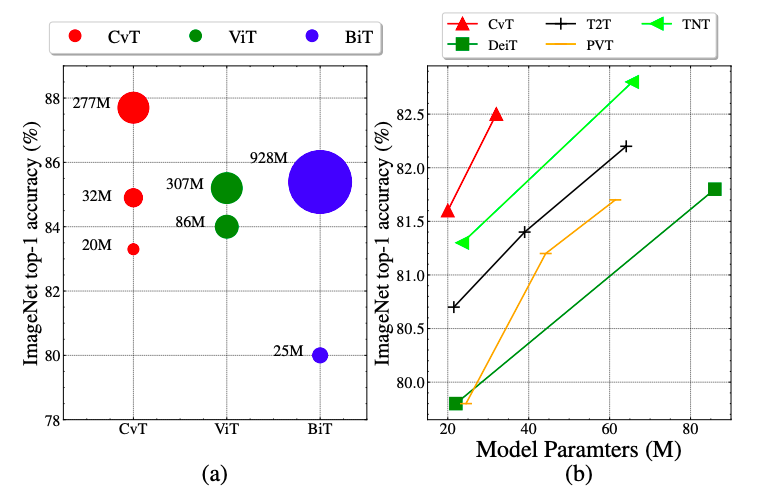
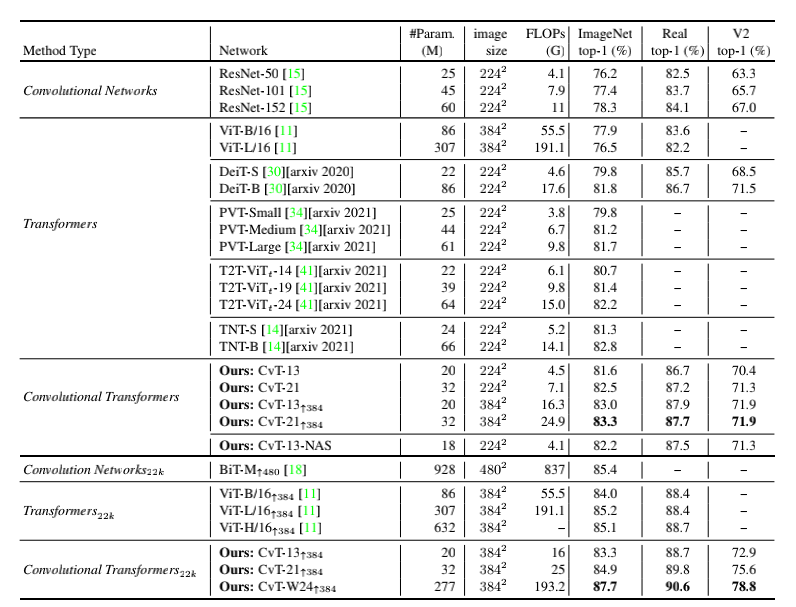
CvT achieved significantly better accuracy on ImageNet1k compared to other Transformer-based works of the same model size.
Additionally, CvT also performed well on the pre-training of the large-scale dataset ImageNet22k, with CvT-W24 achieving a Top-1 accuracy of 87.7% on the ImageNet-1k benchmark with fewer parameters, surpassing the ViT-H/L models trained on the same scale dataset.
Comparing the performance of CvT and SOTA models on datasets such as ImageNet, ImageNet Real, and ImageNet V2, CvT shows superior efficiency compared to ResNet and ViT, as well as other contemporary Transformer-based works under the same scale and computational load.
By employing network structure search techniques to effectively search for optimal model structures in each layer’s Convolutional Projection stride and each layer’s MLP expansion ratio, the optimal model CvT-13-NAS achieved a result of 82.2 on ImageNet1k with 18M model parameters and 4.1G FLOPs.
Comparing the transfer capabilities of CvT with Google’s BiT and ViT in downstream tasks, CvT-W24 achieved a result of 87.7 on ImageNet1k with fewer model parameters, clearly outperforming Google’s BiT-152×4 and ViT-H/16, further verifying the excellent performance of the CvT model.
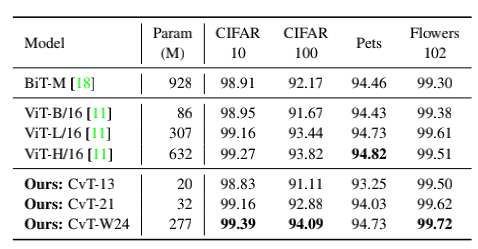
CvT is a novel foundational network that combines the advantages of CNN and Transformers. Experimental results also validate the effectiveness of CvT in ImageNet and various classification tasks. It can be anticipated that this integrated network will further impact the performance of other visual tasks.
References:
https://arxiv.org/pdf/2103.15808.pdf
