Reported by Machine Heart
Machine Heart Editorial Department
Researchers from ByteDance have proposed a next-generation visual Transformer, Next-ViT, which can be effectively deployed in real industrial scenarios. Next-ViT can infer quickly like a CNN while maintaining the powerful performance of a ViT.
Due to the complex attention mechanisms and model designs, most existing visual Transformers (ViT) cannot execute as efficiently as Convolutional Neural Networks (CNN) in real industrial deployment scenarios. This raises the question: Can visual neural networks infer as quickly as CNNs while being as powerful as ViTs?
Recent works have attempted to design CNN-Transformer hybrid architectures to solve this problem, but the overall performance of these works has been far from satisfactory. In response, researchers from ByteDance have proposed a next-generation visual Transformer, Next-ViT, which can be effectively deployed in real industrial scenarios. From the perspective of latency/accuracy trade-offs, Next-ViT’s performance is comparable to that of excellent CNNs and ViTs.

Paper link: https://arxiv.org/pdf/2207.05501.pdf
The research team behind Next-ViT has developed new Convolution Blocks (NCB) and Transformer Blocks (NTB), deploying friendly mechanisms to capture local and global information. The study then proposes a novel hybrid strategy, NHS, designed to stack NCB and NTB in an efficient hybrid paradigm, thereby enhancing the performance of various downstream tasks.
A large number of experiments show that Next-ViT significantly outperforms existing CNNs, ViTs, and CNN-Transformer hybrid architectures in terms of latency/accuracy trade-offs across various visual tasks. On TensorRT, Next-ViT outperforms ResNet by 5.4 mAP (40.4 VS 45.8) on the COCO detection task and by 8.2% mIoU (38.8% VS 47.0%) on the ADE20K segmentation task. Meanwhile, Next-ViT achieves performance comparable to CSWin and has a 3.6 times faster inference speed. On CoreML, Next-ViT outperforms EfficientFormer by 4.6 mAP (42.6 VS 47.2) on the COCO detection task and by 3.5% mIoU (from 45.2% to 48.7%) on the ADE20K segmentation task.
The overall architecture of Next-ViT is shown in Figure 2. Next-ViT follows a hierarchical pyramid architecture, equipped with a patch embedding layer and a series of convolution or transformer blocks at each stage. The spatial resolution is gradually reduced to 1/32 of the original, while the channel dimension is expanded stage by stage.
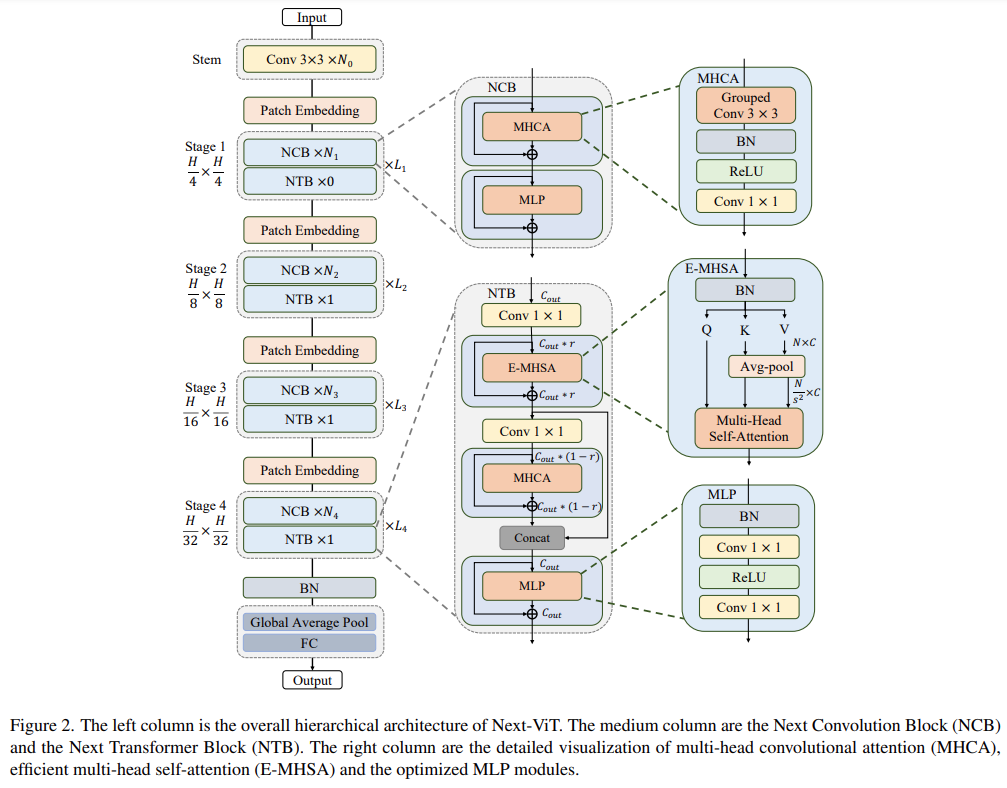
The researchers first delved into the design of the core module for information interaction, separately developing powerful NCB and NTB to simulate short-term and long-term dependencies in visual data. Local and global information fusion was also conducted within NTB, further enhancing modeling capabilities. Finally, to overcome the inherent flaws of existing methods, the study systematically explored the integration of convolution and transformer blocks, proposing the NHS strategy to stack NCB and NTB to construct a novel CNN-Transformer hybrid architecture.
The researchers analyzed several classic structural designs, as shown in Figure 3. The BottleNeck block proposed by ResNet has long dominated visual neural networks due to its inherent inductive bias and ease of deployment on most hardware platforms. Unfortunately, the effectiveness of the BottleNeck block is inferior compared to transformer blocks. The ConvNeXt block modernized the BottleNeck block by mimicking the design of transformer blocks. Although the ConvNeXt block improved network performance, its inference speed on TensorRT/CoreML is severely limited by inefficient components. Transformer blocks have achieved excellent results in various visual tasks, however, their inference speed is much slower than BottleNeck blocks on TensorRT and CoreML due to their complex attention mechanisms, which are difficult to bear in most real industrial scenarios.
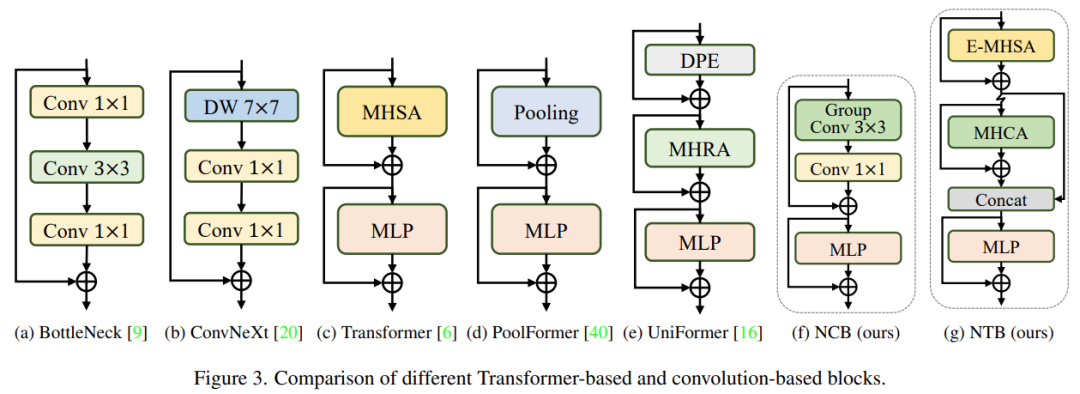
To overcome the issues with the aforementioned blocks, the study proposed the Next Convolution Block (NCB), which retains the deployment advantages of the BottleNeck block while achieving the outstanding performance of transformer blocks. As shown in Figure 3(f), NCB follows the general architecture of MetaFormer, which has been proven critical for transformer blocks.
Additionally, an efficient attention-based token mixer is equally important. The study designed a Multi-Head Convolutional Attention (MHCA) as an efficient token mixer for deploying convolution operations, and used MHCA and MLP layers to construct NCB within the MetaFormer paradigm.
While NCB has effectively learned local representations, the next step is to capture global information. The transformer architecture has a strong ability to capture low-frequency signals that provide global information (e.g., global shapes and structures).
However, related studies have found that transformer blocks may degrade high-frequency information, such as local texture information, to some extent. Signals of different frequency bands are essential in the human visual system, and they are fused in a specific way to extract more essential and unique features.
Influenced by these known results, the study developed the Next Transformer Block (NTB) to capture multi-frequency signals within a lightweight mechanism. Moreover, NTB can serve as an effective multi-frequency signal mixer, further enhancing overall modeling capabilities.
Recent works have made efforts to combine CNN and transformer for efficient deployment. As shown in Figures 4(b)(c), they almost all adopt convolution blocks in shallow stages, stacking only transformer blocks in the last one or two stages. This combination is effective for classification tasks. However, the study found that these hybrid strategies easily reach performance saturation on downstream tasks (e.g., segmentation and detection). The reason is that classification tasks use only the output of the last stage for predictions, while downstream tasks (such as segmentation and detection) typically rely on features from each stage for better results. This is because traditional hybrid strategies only stack transformer blocks in the last few stages, and shallow layers cannot capture global information.
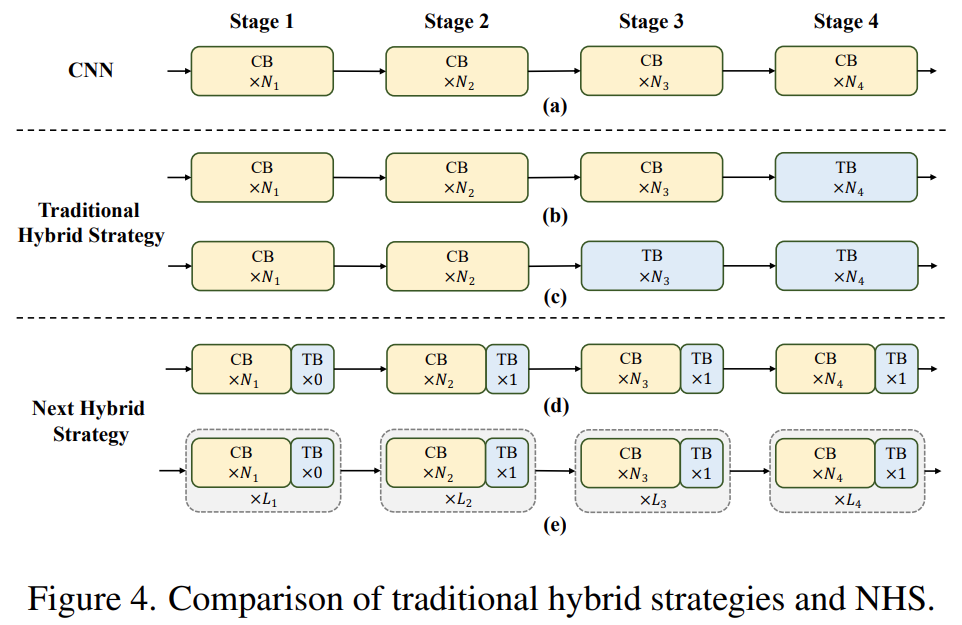
The study proposes a new hybrid strategy (NHS), creatively combining Convolution Blocks (NCB) and Transformer Blocks (NTB) with an (N + 1) * L mixing paradigm. NHS significantly enhances model performance on downstream tasks while achieving efficient deployment, under the control of the transformer block ratio.
First, to endow shallow layers with the ability to capture global information, the study proposes a (NCB×N+NTB×1) pattern mixing strategy, stacking N NCBs and one NTB sequentially at each stage, as shown in Figure 4(d). Specifically, the transformer block (NTB) is placed at the end of each stage, allowing the model to learn global representations in shallow layers. The study conducted a series of experiments to verify the superiority of the proposed mixing strategy, and the performance of different mixing strategies is shown in Table 1.
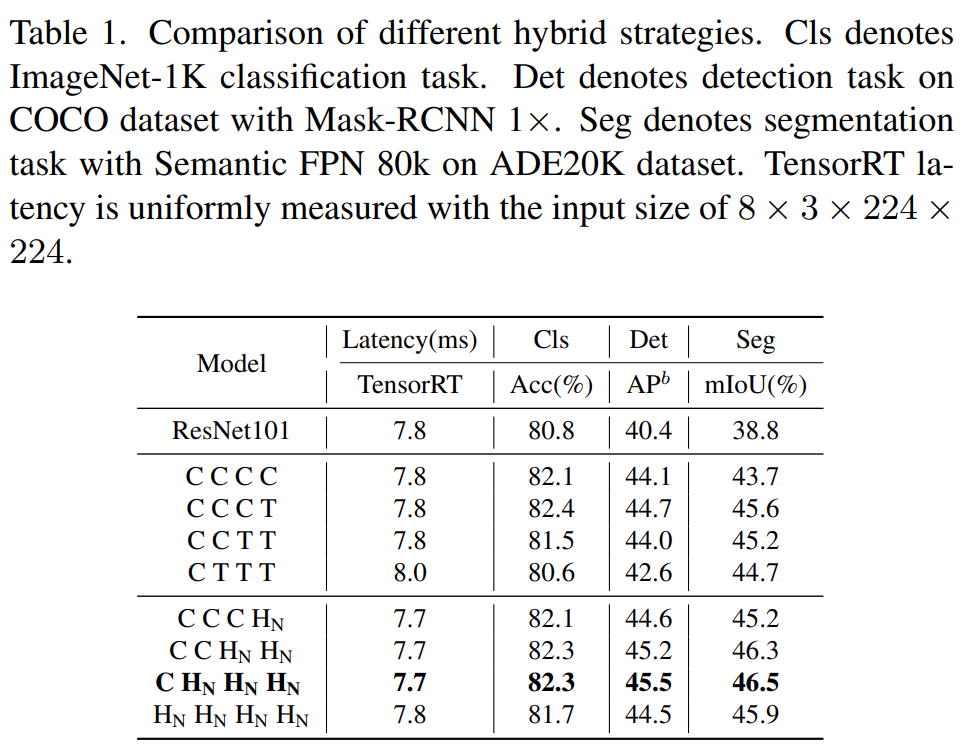
Additionally, as shown in Table 2, the performance of large models gradually reaches saturation. This phenomenon indicates that simply adding more convolution blocks to enlarge the model size through (NCB × N + NTB × 1) pattern is not the optimal choice, and the value of N in the (NCB × N + NTB × 1) pattern may significantly affect model performance.
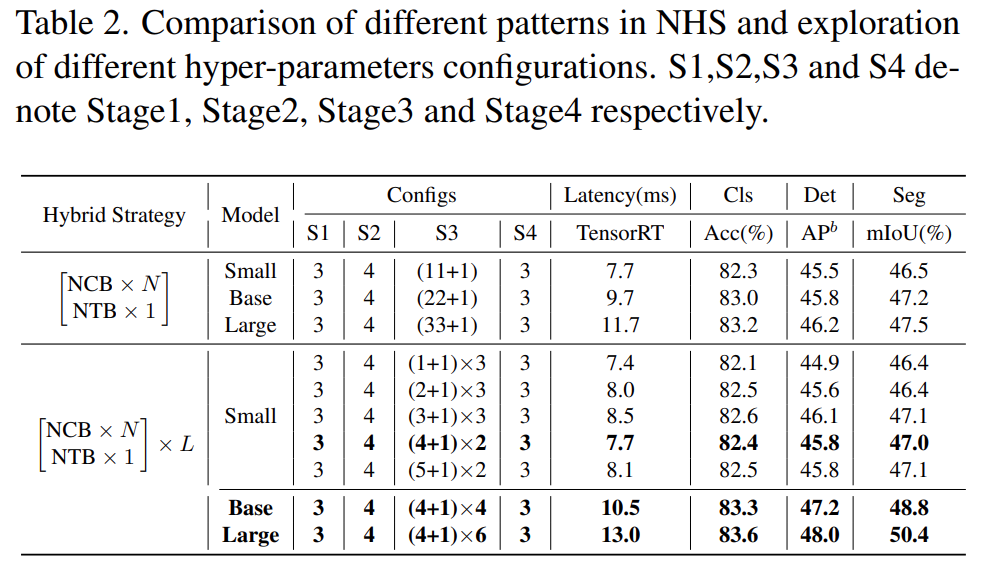
Therefore, the researchers began to explore the impact of the value of N on model performance through extensive experiments. As shown in Table 2 (middle), the study constructed models with different N values in the third stage. To build models with similar latencies for fair comparisons, the study stacked L groups of (NCB × N + NTB × 1) patterns when N values are small.
As shown in Table 2, the model with N = 4 in the third stage achieves the best trade-off between performance and latency. The study further constructs larger models by expanding the (NCB × 4 + NTB × 1) × L pattern in the third stage. As shown in Table 2 (bottom), the Base (L = 4) and Large (L = 6) models show significant improvements in performance compared to smaller models, validating the general effectiveness of the proposed (NCB × N + NTB × 1) × L pattern.
Finally, to provide a fair comparison with existing SOTA networks, the researchers proposed three typical variants, namely Next-ViTS/B/L.
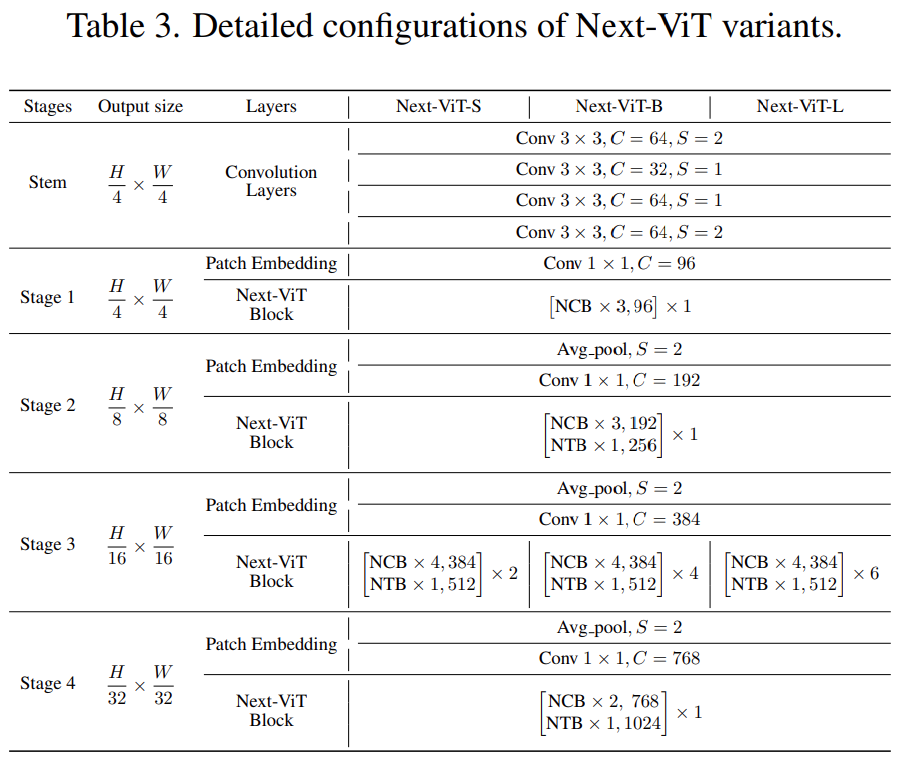
Classification Task on ImageNet-1K
Compared to the latest SOTA methods (e.g., CNN, ViT, and hybrid networks), Next-ViT achieves the best trade-off between accuracy and latency, as shown in Table 4.
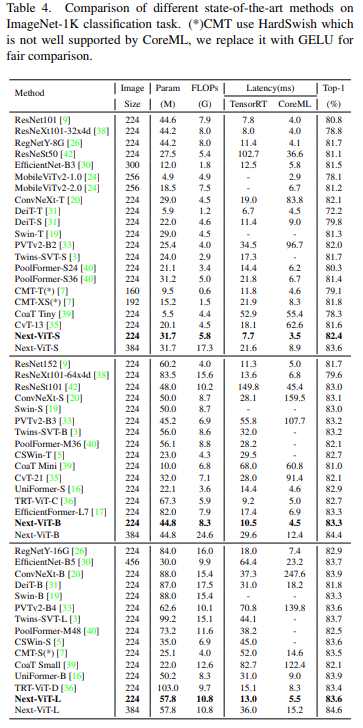
Semantic Segmentation Task on ADE20K
The study compared Next-ViT with CNN, ViT, and recently some hybrid architectures for the semantic segmentation task. As shown in Table 5, a large number of experiments indicate that Next-ViT has excellent potential in segmentation tasks.
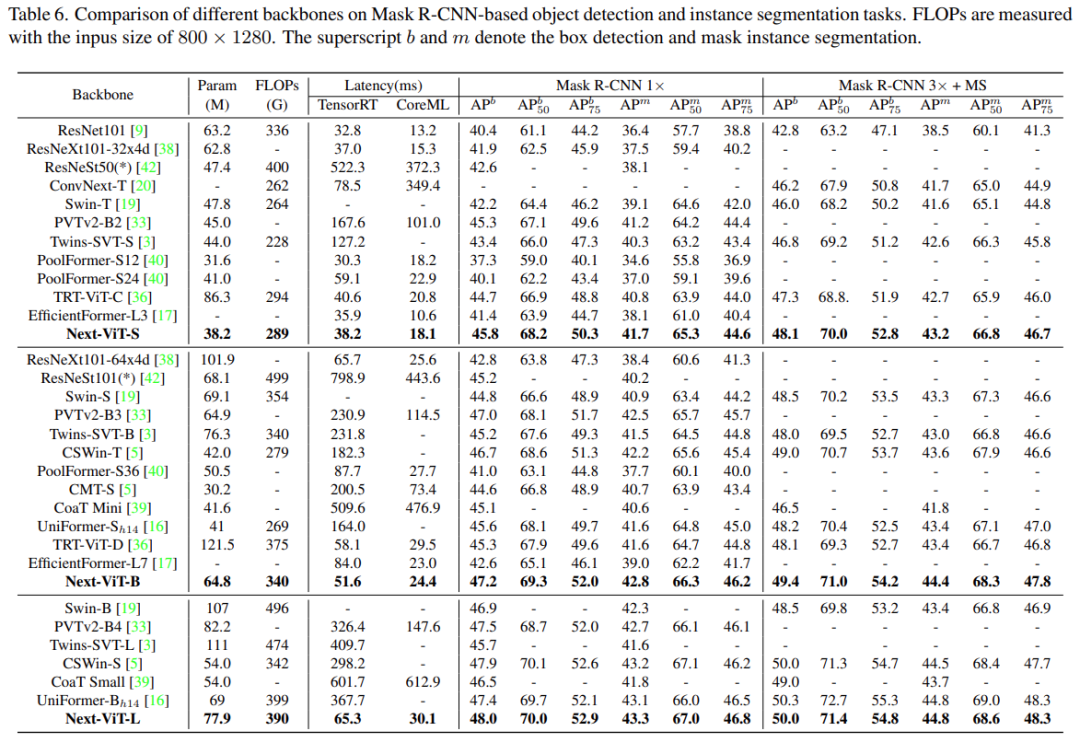
Object Detection and Instance Segmentation
In the object detection and instance segmentation tasks, the study compared Next-ViT with SOTA models, as shown in Table 6.
Ablation Studies and Visualization
To better understand Next-ViT, the researchers analyzed the role of each key design by evaluating its performance on ImageNet-1K classification and downstream tasks, and visualized the Fourier spectrum and heat maps of the output features to show the inherent advantages of Next-ViT.
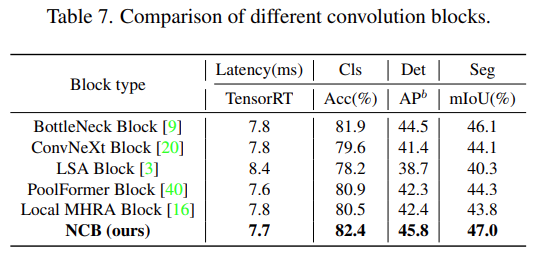
As shown in Table 7, NCB achieves the best latency/accuracy trade-off across all three tasks.
For the NTB block, the study explored the impact of the contraction rate r of NTB on the overall performance of Next-ViT, as shown in Table 8, reducing the contraction rate r will decrease model latency.
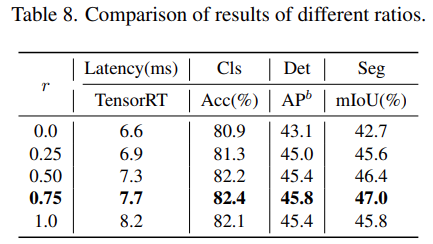
Moreover, models with r = 0.75 and r = 0.5 outperform pure transformer (r = 1) models. This indicates that appropriately fusing multi-frequency signals will enhance the model’s representation learning capability. In particular, the model with r = 0.75 achieves the best latency/accuracy trade-off. These results demonstrate the effectiveness of the NTB block.
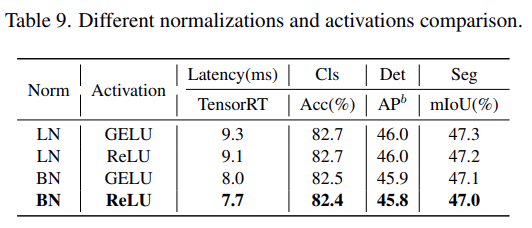
The study further analyzed the impact of different normalization layers and activation functions in Next-ViT. As shown in Table 9, although LN and GELU bring some performance improvements, they significantly increase inference latency on TensorRT. On the other hand, BN and ReLU achieve the best latency/accuracy trade-off across overall tasks. Therefore, Next-ViT uniformly uses BN and ReLU for efficient deployment in real industrial scenarios.
Finally, the researchers visualized the Fourier spectrum and heat maps of the output features of ResNet, Swin Transformer, and Next-ViT, as shown in Figure 5(a). The spectral distribution of ResNet indicates that convolution blocks tend to capture high-frequency signals while struggling to focus on low-frequency signals; ViT excels at capturing low-frequency signals while ignoring high-frequency signals; whereas Next-ViT can capture high-quality multi-frequency signals simultaneously, demonstrating the effectiveness of NTB.
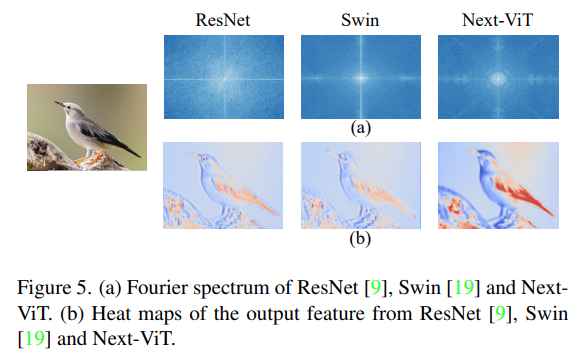
Additionally, as shown in Figure 5(b), Next-ViT can capture richer texture information and more accurate global information than ResNet and Swin, indicating that Next-ViT has stronger modeling capabilities.
© THE END
For reprints, please contact this public account for authorization
For submissions or seeking coverage: [email protected]
