Exploring DeepSeek and Its Core Technologies
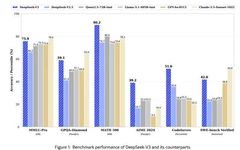
Alibaba Sister’s Guide This article delves deep into the core technologies of the DeepSeek large model, providing a comprehensive analysis from the company’s background, model capabilities, training and inference costs to the details of the core technologies. 1. About DeepSeek Company and Its Large Model 1.1 Company Overview DeepSeek was established in July 2023 in … Read more







