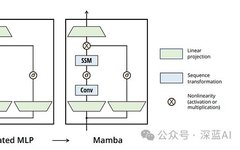
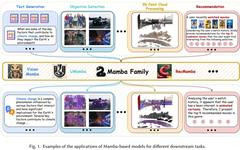
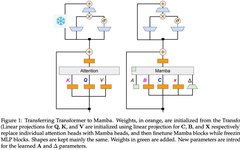
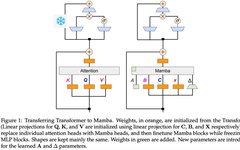
Analysis of Mamba: A New Architecture Challenging Transformers and Pytorch Implementation

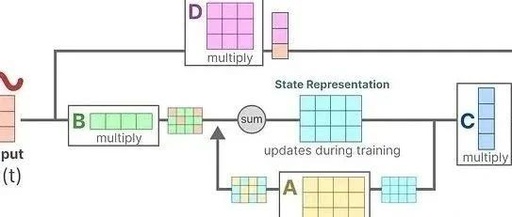
Click the "Little White Learns Vision" above, select "Star" or "Top" Heavyweight content delivered in real-time Today we will study the paper “Mamba: Linear Time Series Modeling with Selective State Space” in detail. Mamba has been making waves in the AI community, touted as a potential competitor to Transformers. What exactly makes Mamba stand out … Read more