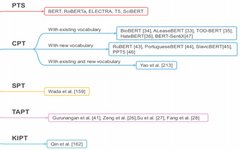
Current Status and Analysis of Pre-trained Models in NLP
Author | Wang Zeyang Organization | Niutrans Editor | Tang Li Reprinted from WeChat Official Account | AI Technology Review This article is submitted by Wang Zeyang, a graduate student from the Natural Language Processing Laboratory of Northeast University. Wang Zeyang’s research direction is machine translation. Niutrans, whose core members come from the Natural Language … Read more