Author | Wang Zeyang Organization | Niutrans Editor | Tang Li
Reprinted from WeChat Official Account | AI Technology Review
This article is submitted by Wang Zeyang, a graduate student from the Natural Language Processing Laboratory of Northeast University. Wang Zeyang’s research direction is machine translation.
Niutrans, whose core members come from the Natural Language Processing Laboratory of Northeast University, was founded in 1980 by Professor Yao Tianshun and is currently led by Professor Zhu Jingbo and Dr. Xiao Tong. The team has been engaged in related research in computational linguistics, mainly including machine translation, language analysis, and text mining. The Niutrans system developed by the team supports translation between 140 languages and has been widely applied. They have also developed Niutrans Cloud (https://niutrans.vip) to empower global enterprises with machine translation technology.
The method of pre-training was initially proposed in the field of images, achieving good results, and later applied to natural language processing. Pre-training generally consists of two steps: first, a model is trained with a relatively large dataset (this model is often quite large and requires a lot of memory resources) to reach a good state, and then the pre-trained model is adapted for different tasks and fine-tuned using the dataset of that task.This approach has the advantage of low training cost; the parameters of the pre-trained model can enable the new model to achieve faster convergence and effectively improve model performance, especially for tasks with scarce training data. In cases where the neural network parameters are very large, relying solely on the training data of the task may not be sufficient for adequate training. The pre-training method can be seen as allowing the model to learn from a better initial state, thereby achieving better performance.
1. Development of Pre-training Methods
Word Embedding-based Pre-training Methods
In 2003, Bengio et al. proposed the Neural Network Language Model [1]. In the training process, the neural language model not only learns the probability distribution of predicting the next word but also produces a by-product: word embeddings. Compared to randomly initialized word embeddings, the embeddings learned after model training contain information about the relationships between words. In 2013, Mikolov et al. proposed the word2vec tool, which includes the CBOW (Continue Bag of Words) model and the Skip-gram model [2-3]. This tool trains word embeddings using vast amounts of monolingual data through unsupervised methods.
Language Model-based Pre-training Methods
Word embeddings have inherent limitations, the main drawback being their inability to resolve polysemy; different words can have different meanings in different contexts, while word embeddings assign a fixed representation to each word in the model. To address this issue, Peters et al. proposed ELMo (Embedding from Language Model) [4], which uses a language model to obtain deep contextual representations. ELMo’s approach is to use a bidirectional LSTM language model to obtain the representation of a word based on its context. ELMo can extract rich features for downstream tasks, but it only performs feature extraction without pre-training the entire network, thus not fully leveraging the potential of pre-training. Another limitation is that the self-attention mechanism of the Transformer model structure can more effectively capture long-distance dependencies and model information in sentences.To address these two issues, Radford et al. proposed GPT (Generative Pre-Training) [5], which replaces LSTM with Transformer, achieving better results. However, because it uses a unidirectional model, it can only predict subsequent words based on preceding words, potentially missing information. Devlin et al. proposed BERT (Bidirectional Encoder Representations from Transformers) [6], which is based on a bidirectional encoder representation from Transformer. The structure and methods of BERT and GPT are quite similar, but the main difference is that the GPT model uses a unidirectional language model, which can be viewed as a decoder representation based on Transformer, while BERT uses a Transformer-based encoder that can model information from both past and future, enabling it to extract richer information. The diagram of the three pre-trained models is shown below: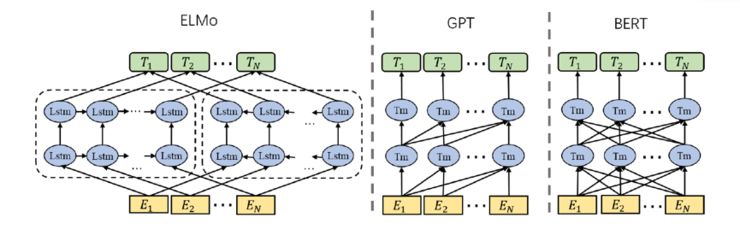 After BERT’s introduction, it gained immense popularity, possibly because of its excellent performance. Currently, the vast majority of pre-trained models are adaptations of BERT. Wang Xiaozhi and Zhang Zhengyan from Tsinghua University provided a relationship diagram of current pre-trained models, which is quoted here as shown below:
After BERT’s introduction, it gained immense popularity, possibly because of its excellent performance. Currently, the vast majority of pre-trained models are adaptations of BERT. Wang Xiaozhi and Zhang Zhengyan from Tsinghua University provided a relationship diagram of current pre-trained models, which is quoted here as shown below: Below, several variants of BERT will be introduced.
Below, several variants of BERT will be introduced.
2. Cross-lingual Language Model Pretraining (XLM) [7]
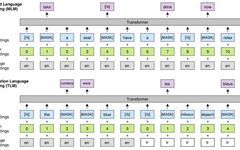
In this work, the authors extended the pre-training method to multiple languages and demonstrated the effectiveness of cross-lingual pre-training. The author believes that there are two innovations in this work: the design of a cross-lingual language model training task for multilingual classification; and the use of BERT as the model initialization for unsupervised machine translation.
1. Multilingual Classification Task
Although BERT has been trained on over 100 languages, it has not been optimized for cross-lingual tasks, resulting in limited shared knowledge. To overcome this issue, XLM modified BERT in the following way:
In BERT, each sample is constructed in one language. XLM’s improvement is that each training sample contains the same text in two languages. Like BERT, the model’s objective is to predict masked words, but with a new architecture, the model can use the context of one language to predict words in another language. Since the masked words in different languages are different (randomly), the modified BERT is represented as TLM (Translation Language Model), while the ‘original’ BERT with BPE input is represented as MLM (Masked Language Model). The complete model is trained by training MLM and TLM and alternating between them.
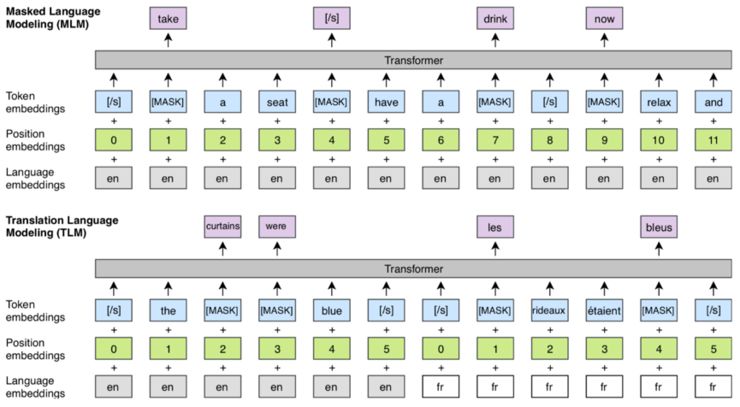 XLM shows that training a cross-lingual language model can be very beneficial for resource-scarce languages, as they can leverage data from other languages, especially similar languages produced by BPE preprocessing.
XLM shows that training a cross-lingual language model can be very beneficial for resource-scarce languages, as they can leverage data from other languages, especially similar languages produced by BPE preprocessing.
2. Unsupervised Machine Translation
Another contribution of XLM is the use of BERT to initialize unsupervised models’ Encoder and Decoder. The specific approach involves random initialization, MLM initialization, or CLM initialization (as shown in the figure) on the Encoder and Decoder ends of the Transformer, resulting in 9 different structures.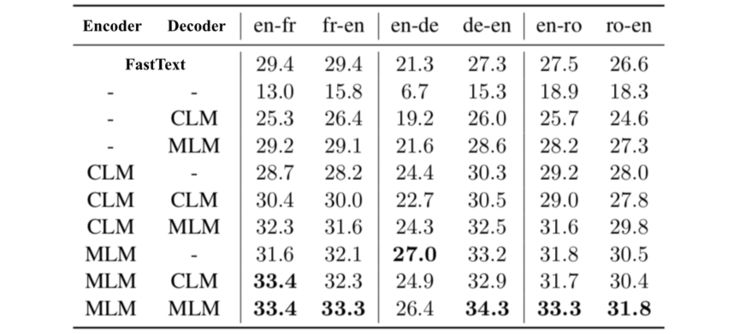
3. Masked Sequence to Sequence Pre-training (MASS) [8]
BERT’s pre-training is conducted on the Encoder of the Transformer, making BERT inherently more aligned with natural language understanding tasks, while it is difficult to apply to language generation tasks such as machine translation.Microsoft’s researchers believe that BERT only pre-trains the Encoder part of the Transformer, but for end-to-end tasks, the Encoder-Decoder are related. If BERT initializes both the Encoder and Decoder ends, they are trained separately without any connection. To solve this problem, Microsoft’s work proposed MASS (Masked Sequence to Sequence Pre-training).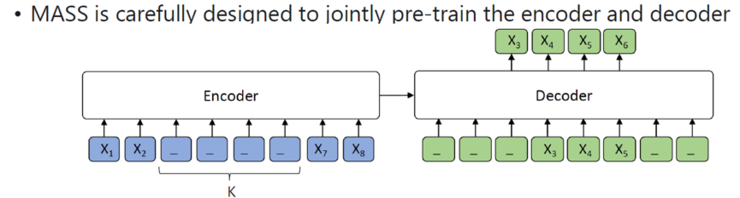 MASS pre-trains the Encoder and Decoder through a language model. Unlike BERT, the masked words are k (these k words are consecutive), and only the first k-1 masked words are input into the Decoder to predict the k masked words. The advantages of MASS include:
MASS pre-trains the Encoder and Decoder through a language model. Unlike BERT, the masked words are k (these k words are consecutive), and only the first k-1 masked words are input into the Decoder to predict the k masked words. The advantages of MASS include:
- The Encoder is forced to extract the semantics of the unmasked words to enhance its ability to understand the source sequence text.
- Other words in the Encoder (the words that are not masked in the Encoder) are masked, allowing the Decoder to extract information from the Encoder to help predict the continuous segment.
- The Encoder predicting continuous sequence segments can enhance the language modeling capability of the Encoder.
MASS requires only unsupervised monolingual data for pre-training. MASS supports cross-lingual sequence-to-sequence generation (such as machine translation) and also supports monolingual sequence-to-sequence generation (such as text summarization and dialogue generation). For example, when using MASS for English-French machine translation, pre-training is conducted simultaneously for both English and French within one model (adding the corresponding language embedding vectors to each language to distinguish between different languages).Regarding effectiveness, in WMT19, MASS helped Microsoft achieve several translation championships; specific rankings can be viewed in the WMT19 leaderboard.
4. XLNet: Generalized Autoregressive Pretraining for Language Understanding
Autoregressive language models are unidirectional but naturally match natural language generation tasks, while autoencoding (BERT) can integrate bidirectional information but introduces MASK, leading to inconsistencies between pre-training and fine-tuning phases. XLNet combines the advantages of autoregressive language models and autoencoding language models. XLNet’s contribution in modeling is that, although it appears to still follow a left-to-right input and prediction pattern, it actually introduces contextual information of the current word.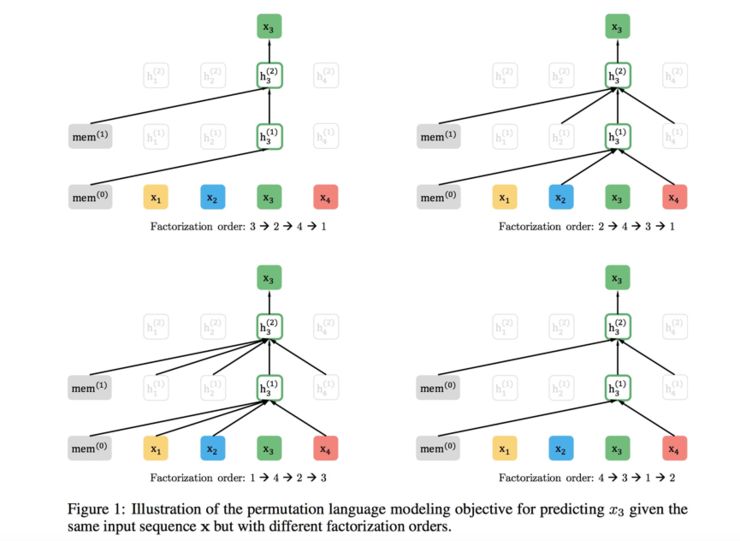 In the pre-training phase, the training objective introduces a Permutation Language Model. In simpler terms, it fixes the word to be predicted, rearranging the positions of the remaining words, swapping the words that follow the predicted word to the front, and selecting a portion of the randomly arranged combinations as the input for model pre-training. This allows the current word to see the contextual content, but it still appears as a left-to-right prediction of the next word. The specific implementation can be found in the XLNet paper.Additionally, it incorporates the main ideas of Transformer-XL: relative position encoding and segmented RNN mechanisms. Practice has shown that these two points are very helpful for long document tasks; during the pre-training phase, the data scale is greatly expanded, and the quality is filtered.Compared to BERT, XLNet shows significant improvement for long documents because Transformers inherently struggle with long document tasks. As mentioned earlier, for generative NLP tasks, BERT still does not perform well. However, XLNet’s pre-training mode naturally aligns with the sequence generation results of downstream tasks. However, there is currently no experimental evidence to prove this.
In the pre-training phase, the training objective introduces a Permutation Language Model. In simpler terms, it fixes the word to be predicted, rearranging the positions of the remaining words, swapping the words that follow the predicted word to the front, and selecting a portion of the randomly arranged combinations as the input for model pre-training. This allows the current word to see the contextual content, but it still appears as a left-to-right prediction of the next word. The specific implementation can be found in the XLNet paper.Additionally, it incorporates the main ideas of Transformer-XL: relative position encoding and segmented RNN mechanisms. Practice has shown that these two points are very helpful for long document tasks; during the pre-training phase, the data scale is greatly expanded, and the quality is filtered.Compared to BERT, XLNet shows significant improvement for long documents because Transformers inherently struggle with long document tasks. As mentioned earlier, for generative NLP tasks, BERT still does not perform well. However, XLNet’s pre-training mode naturally aligns with the sequence generation results of downstream tasks. However, there is currently no experimental evidence to prove this.
5. Conclusion
The various variants of BERT demonstrate the popularity of BERT and Transformer. The author believes that the trend of pre-training + fine-tuning for downstream tasks is unifying the field of natural language. Pre-training not only has a significant enhancement effect on low-resource tasks but also notably improves model performance even on resource-rich tasks. Unless a feature extraction model surpassing Transformer is proposed, it is believed that various adaptations based on BERT will continue to emerge to suit different types of downstream tasks. Some pre-trained models have introduced knowledge graphs based on BERT to make BERT more ‘knowledgeable,’ such as Tsinghua University’s ERNIE [10].Since various tasks modify pre-trained models differently, is there a pre-trained model that can adapt to all NLP tasks? Recently, Google released the extremely large T5 (NLP Text-to-Text) [11] pre-trained model. It provides a universal framework for the entire NLP pre-training model field, transforming all tasks into a single format. Regardless of the task, one can simply use a large pre-trained model, and the main task becomes how to convert the task into suitable text input and output, for example, for German to English translation, one simply adds ‘translate German to English’ to the input part of the training dataset.Another approach is not to modify pre-trained models but to compress the large pre-trained model. For instance, the recent alBERT reduces BERT’s parameters through shared parameters and introduces a separate word embedding layer dimension. Its performance also topped GLUE (recently surpassed by T5). Additionally, models like tinyBERT trained through knowledge distillation are also compressions of the BERT model.References[1] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model. [2] Mikolov T, Chen K, Corrado G S, et al. Efficient Estimation of Word Representations in Vector Space. [3] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality. [4] Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep Contextualized Word Representations.[5] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. [6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.[7] Guillaume Lample and Alexis Conneau. 2019. Cross-lingual Language Model Pretraining.[8] Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2019. MASS: Masked Sequence to Sequence Pre-training for Language Generation.[9] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019. XLNet: Generalized Autoregressive Pretraining for Language Understanding.[10] Zhengyan Zhang, Xu Han, Zhiyuan Liu1, Xin Jiang, Maosong Sun1, Qun Liu. ERNIE: Enhanced Language Representation with Informative Entities.[11] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee,et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
Recommended Reading:
Geometric Interpretation of Systems of Equations [MIT Linear Algebra First Class PDF Download]
Common Normalization Methods: BN, LN, IN, GN
PaddlePaddle Practical NLP Classic Model BiGRU + CRF Detailed Explanation
