XLNet Pre-training Model: Everything You Need to Know
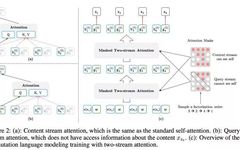
Author | mantch Reprinted from WeChat Official Account | AI Technology Review 1. What is XLNet XLNet is a model similar to BERT, rather than a completely different model. In short, XLNet is a general autoregressive pre-training method. It was released by the CMU and Google Brain teams in June 2019, and ultimately, XLNet outperformed … Read more







